
minikube集群吊舱不健康,并由于连接拒绝错误而重新启动。
minikube集群吊舱不健康,并由于连接拒绝错误而重新启动。
提问于 2021-09-08 04:35:07
我已经在centos7 VM上安装了minikube集群。安装后,由于不健康的吊舱状态,很少有吊舱重新启动。所有失败的吊舱都有类似的原因:
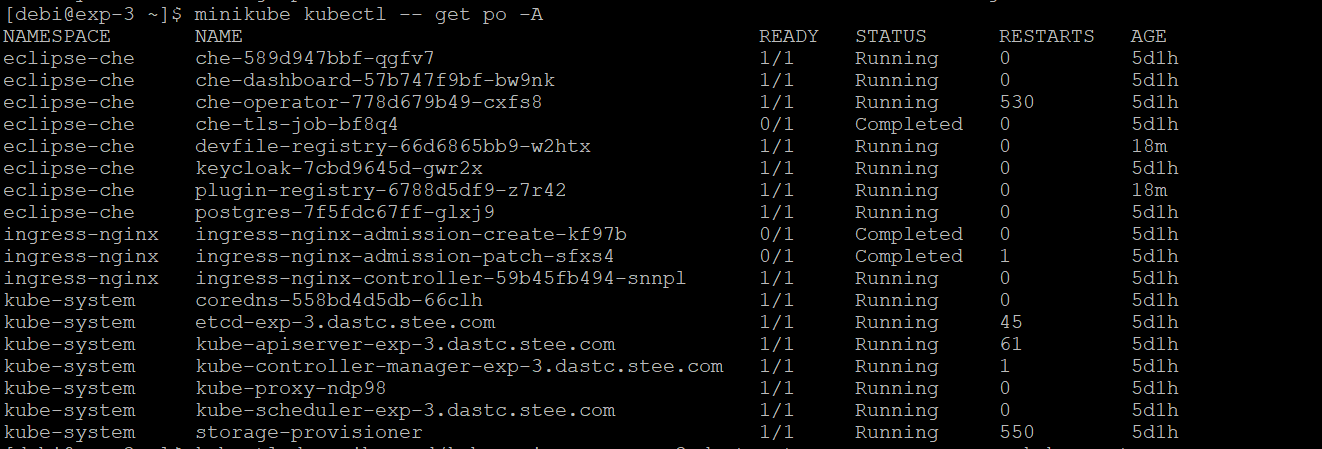
豆荚错误(描述命令):
Readiness probe failed: Get "http://172.17.0.4:6789/readyz": dial tcp 172.17.0.4:6789: connect: connection refused
Liveness probe failed: Get "http://172.17.0.4:6789/healthz": dial tcp 172.17.0.4:6789: connect: connection refused
Liveness probe failed: HTTP probe failed with statuscode: 500
Readiness probe failed: HTTP probe failed with statuscode: 500
Liveness probe failed: HTTP probe failed with statuscode: 503由于这些错误,吊舱中的应用程序无法正常工作。我对kubernates不熟悉,无法理解调试此错误。
更新请参阅以下的pod错误日志(che-操作符)
time="2021-09-09T15:37:13Z" level=info msg="Deployment plugin-registry is in the rolling update state."
I0909 15:37:15.651964 1 request.go:655] Throttling request took 1.04725976s, request: GET:https://10.96.0.1:443/apis/extensions/v1beta1?timeout=32s
time="2021-09-09T15:37:16Z" level=info msg="Deployment plugin-registry is in the rolling update state."
I0909 15:37:37.710602 1 request.go:655] Throttling request took 1.046990691s, request: GET:https://10.96.0.1:443/apis/apiextensions.k8s.io/v1?timeout=32s
W0909 15:43:23.172829 1 warnings.go:70] extensions/v1beta1 Ingress is deprecated in v1.14+, unavailable in v1.22+; use networking.k8s.io/v1 Ingress
E0909 15:47:05.403189 1 leaderelection.go:325] error retrieving resource lock eclipse-che/e79b08a4.org.eclipse.che: Get "https://10.96.0.1:443/api/v1/namespaces/eclipse-che/configmaps/e79b08a4.org.eclipse.che": context deadline exceeded
I0909 15:47:05.403334 1 leaderelection.go:278] failed to renew lease eclipse-che/e79b08a4.org.eclipse.che: timed out waiting for the condition
{"level":"info","ts":1631202425.4036877,"logger":"controller","msg":"Stopping workers","reconcilerGroup":"org.eclipse.che","reconcilerKind":"CheCluster","controller":"checluster"}
{"level":"error","ts":1631202425.4034257,"logger":"setup","msg":"problem running manager","error":"leader election lost","stacktrace":"github.com/go-logr/zapr.(*zapLogger).Error\n\t/che-operator/vendor/github.com/go-logr/zapr/zapr.go:132\nmain.main\n\t/che-operator/main.go:254\nruntime.main\n\t/usr/lib/golang/src/runtime/proc.go:204"}回答 1
Stack Overflow用户
发布于 2021-09-08 04:44:07
基于错误的准备状态和生命探测失败
就绪探测失败:获取"http://172.17.0.4:6789/readyz“
准备和活性探针用于检查POD内部的应用状况。如果应用程序没有响应Kubernetes将自动重新启动POD,它将持续检查一个端点上的应用程序状态。
在这种情况下,我建议检查在POD中运行的应用程序状态。准备和健康的失败,因此,你的吊舱是失败的。
欲了解更多关于准备和活力的信息,请访问:https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
您还可以使用以下方法检查应用程序的日志:
kubectl get logs <POD name>页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69097080
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号