
如何在Timespan上迭代,并使用Python计算Dataframe中的值?
如何在Timespan上迭代,并使用Python计算Dataframe中的值?
提问于 2021-09-22 13:38:02
我有如下所示的数据
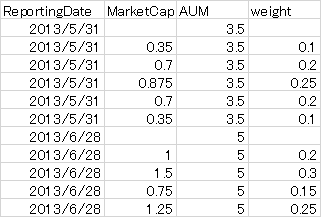
data = {'ReportingDate':['2013/5/31','2013/5/31','2013/5/31','2013/5/31','2013/5/31','2013/5/31',
'2013/6/28','2013/6/28',
'2013/6/28','2013/6/28','2013/6/28'],
'MarketCap':[' ',0.35,0.7,0.875,0.7,0.35,' ',1,1.5,0.75,1.25],
'AUM':[3.5,3.5,3.5,3.5,3.5,3.5,5,5,5,5,5],
'weight':[' ',0.1,0.2,0.25,0.2,0.1,' ',0.2,0.3,0.15,0.25]}
# Create DataFrame
df = pd.DataFrame(data)
df.set_index('Reporting Date',inplace=True)
df只是8000行数据集的一个示例。
ReportingDate从2013/5/31至2015/10/30开始。其中包括上述期间所有月份的数据。但每个月的最后一天。每个月的第一行有两个缺失的数据。我知道
- 每个月的权重之和等于1
- 权重*AUM等于MarketCap
我可以用下面的一行来得到我想要的答案,只有一个月
a= (1-df["2013-5"].iloc[1:]['weight'].sum())
b= a* AUM
df.iloc[1,0]=b
df.iloc[1,2]=a如何使用循环来获取整个期间的数据?谢谢
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-09-22 13:48:03
使用pandas.DataFrame.groupby的一种方法
# If whitespaces are indeed whitespaces, not nan
df = df.replace("\s+", np.nan, regex=True)
# If not already datatime series
df.index = pd.to_datetime(df.index)
s = df["weight"].fillna(1) - df.groupby(df.index.date)["weight"].transform(sum)
df["weight"] = df["weight"].fillna(s)
df["MarketCap"] = df["MarketCap"].fillna(s * df["AUM"])注意:这假设日期总是最后一天,因此它相当于按年月份分组。如果不是这样,试着:
s = df["weight"].fillna(1) - df.groupby(df.index.strftime("%Y%m"))["weight"].transform(sum)输出:
MarketCap AUM weight
ReportingDate
2013-05-31 0.350 3.5 0.10
2013-05-31 0.525 3.5 0.15
2013-05-31 0.700 3.5 0.20
2013-05-31 0.875 3.5 0.25
2013-05-31 0.700 3.5 0.20
2013-05-31 0.350 3.5 0.10
2013-06-28 0.500 5.0 0.10
2013-06-28 1.000 5.0 0.20
2013-06-28 1.500 5.0 0.30
2013-06-28 0.750 5.0 0.15
2013-06-28 1.250 5.0 0.25页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69285396
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号