
单表DynamoDB设计技巧
我有一个旧的应用,我正在现代化,并带来了AWS。我将使用DynamoDB作为数据库,并希望使用单一的表设计。这是一个多租户应用程序。
申请将包括组织,网点,客户和交易。任何东西都来源于一个组织,一个组织可以有多个网点,网点可以有多个客户,客户可以有多个事务。
预计访问模式如下:
transaction)
- Get
- 通过其ID
- 搜索客户的姓名或电子邮件
- 获取给定出口的所有客户
- 获取客户
- 获取插座的所有事务
H 210H 111在给定的时间段内获取一个出口的所有事务(时间戳将通过其IDH 216F 217将时间戳存储到每个给定organisation
Get的所有出口
我一直在阅读单个表的设计,并使用主键和排序键来启用这种访问,但现在我还不太清楚表/模式的设计。客户会附上outletID和OrganiastionID,所以我应该一直知道那些ID
数据结构(可修改)
组织:
idNameOwnerList of OutletscreatedAt (时间戳)
网点:
OrganisationIdOutlet NameNumber of customersNumber of transactionscreatedAt (时间戳)
客户:
idOrganisationIDOutletIDfirstNamelastNameemailtotal transactionstotal spentcreatedAt (时间戳)
Transactions:
idcustomerIDOrganisationIDOutletIDcreatedAt (timestamp)typevalue
回答 1
Stack Overflow用户
发布于 2021-09-25 23:15:05
通过彻底了解您的实体和访问模式,您将有一个很好的开始!我尝试过对这些访问模式进行建模,但请记住,这并不是对解决方案建模的唯一方法。DynamoDB中的数据建模是迭代的,所以这很可能不适合100%的用例。
把免责声明让开,让我们开始吧!
我使用一个名为data的表来建模您的访问模式,其中包含名为GSI1和GSI2的全局辅助索引(GSI)。每个GSI都有分区和排序密钥,分别命名为GSI#PK和GSI#SK。

基表对以下访问模式进行了建模:
getItem where PK=CUST#<id> and SK = A
- Fetch
- 按ID获取客户:
query where PK=CUST#<id> and SK begins_with TX
- Fetch所有客户事务:
query where PK=CUST#<id> and SK begins_with TX
- Fetch a outlet by ID:
getItem where PK=ORG#<id> and SK = A
- Fetch all customers for a outlet:
query where PK=OUT#<id>#CUST
最后一个访问模式可能需要更多的解释。我选择使用一个独特的PK/SK模式来建模网点和客户之间的关系,其中PK是OUT#<id>#CUST,SK是CUST#<id>。当应用程序记录特定客户的事务时,它可以使用批处理写入操作在DDB中插入两条记录。批处理写入操作将执行两个操作:
将新事务写入客户分区(例如PK = TX#<id>)
- Write和SK =),向CUSTOMERLIST分区写入新记录(例如PK =
OUT#<id>#CUST和SK =CUST#<id>)。如果这个记录已经存在,DynamoDB将只覆盖现有的记录,这对于您的用例来说是很好的。
移动到GSI1上:
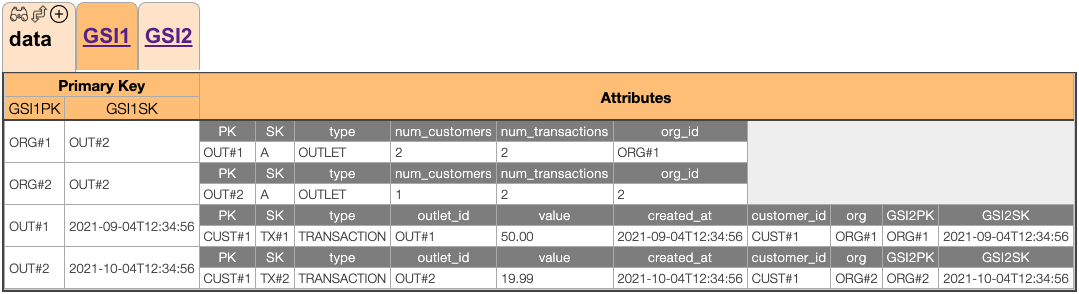
GSI1支持以下操作:
按组织计算的query GSI1 where GSI1PK = ORG#<id>
- Fetch事务:按出口计算的
query GSI1 where GSI1PK = OUT#<id>
- Fetch事务:给定时间段的
query GSI1 where GSI1PK = OUT#<id>
- Fetch事务:“查询GSI1,其中GSI1PK=OUT#和GSI1SK之间和
最后,还有GSI2
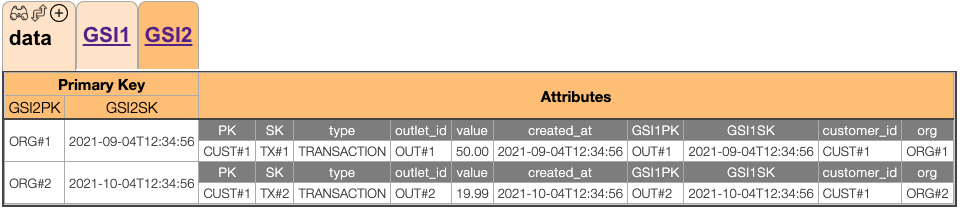
GSI2支持以下事务:
按组织提取事务:按组织分列的query GSI2 where GSI2PK = ORG#<id>
- Fetch事务,在给定时间内:
query GSI2 where GSI2PK=OUT#<id> and GSI2SK between <period1> and <period2>
对于最后的访问模式,您已经要求支持通过电子邮件或名称搜索客户。DynamoDB非常擅长通过主键查找项目。DynamoDB不适合搜索,在搜索中需要进行模糊或部分匹配。如果您需要在电子邮件或名称上进行完全匹配,您可以在DynamoDB中通过在用户项的主键中包含电子邮件//名称来实现这一点。
我希望这能给你一些关于如何建模你的访问模式的想法!
https://stackoverflow.com/questions/69318572
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号