
用R调整skimr封装中的火花图/直方图
我正在编写一份报告,其中将显示一些Likert刻度数据的结果。我想使用skimr包中的skim()函数来利用星火图/直方图可视化。问题是,对于每个问题,我的答复选项从1到5不等,但我的一些问题只收集了在3至5范围内的答复(未选择答复选项1和2)。直方图显示五列,范围似乎代表3,3.5,4,4.5,5,而不是从1到5。我如何告诉skimr显示选项1到5?谢谢你提前提供帮助。
示例:
数据:
Var1 Var2 Var3 Var4 Var5 Var6 Var7 Var8
1 3 3 3 1 3 4 4
5 5 5 4 2 5 5 5
5 5 5 5 5 5 5 5
5 5 5 4 2 5 5 5
5 5 5 4 2 5 5 5我使用以下代码:
skim(Data)我希望历史记录(“hist”栏)显示Reponse 1到5。但是对于变量2,3,4,6,7,8,它只显示3或4到5的值。有什么方法来调整这个值吗?
回答 1
Stack Overflow用户
发布于 2021-09-29 21:35:01
你似乎有一点误解。
让我们以tibble的形式获取未更改的数据,并将其放入skim函数中。
library(tidyverse)
library(skimr)
df = read.table(
header = TRUE,text="
Var1 Var2 Var3 Var4 Var5 Var6 Var7 Var8
1 3 3 3 1 3 4 4
5 5 5 4 2 5 5 5
5 5 5 5 5 5 5 5
5 5 5 4 2 5 5 5
5 5 5 4 2 5 5 5
") %>% as_tibble()
df %>% skim()我们从输出中得到这个
-- Data Summary ------------------------
Values
Name Piped data
Number of rows 5
Number of columns 8
_______________________
Column type frequency:
numeric 8
________________________
Group variables None
-- Variable type: numeric ---------------------------------------------------------------------------------------------
# A tibble: 8 x 11
skim_variable n_missing complete_rate mean sd p0 p25 p50 p75 p100 hist
* <chr> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
1 Var1 0 1 4.2 1.79 1 5 5 5 5 ▂▁▁▁▇
2 Var2 0 1 4.6 0.894 3 5 5 5 5 ▂▁▁▁▇
3 Var3 0 1 4.6 0.894 3 5 5 5 5 ▂▁▁▁▇
4 Var4 0 1 4 0.707 3 4 4 4 5 ▂▁▇▁▂
5 Var5 0 1 2.4 1.52 1 2 2 2 5 ▂▇▁▁▂
6 Var6 0 1 4.6 0.894 3 5 5 5 5 ▂▁▁▁▇
7 Var7 0 1 4.8 0.447 4 5 5 5 5 ▂▁▁▁▇
8 Var8 0 1 4.8 0.447 4 5 5 5 5 ▂▁▁▁▇然而,您确实会写到您的数据处于Likert比例。对于这些数据,计算平均值、标准差等是没有意义的,因为变量Var1的平均值是4.2是什么意思?我不能解释。
然后,我们必须将所有变量变异为因子类型。
df %>% mutate_all(~factor(., 1:5)) %>% skim()输出
-- Data Summary ------------------------
Values
Name Piped data
Number of rows 5
Number of columns 8
_______________________
Column type frequency:
factor 8
________________________
Group variables None
-- Variable type: factor ----------------------------------------------------------------------------------------------
# A tibble: 8 x 6
skim_variable n_missing complete_rate ordered n_unique top_counts
* <chr> <int> <dbl> <lgl> <int> <chr>
1 Var1 0 1 FALSE 2 5: 4, 1: 1, 2: 0, 3: 0
2 Var2 0 1 FALSE 2 5: 4, 3: 1, 1: 0, 2: 0
3 Var3 0 1 FALSE 2 5: 4, 3: 1, 1: 0, 2: 0
4 Var4 0 1 FALSE 3 4: 3, 3: 1, 5: 1, 1: 0
5 Var5 0 1 FALSE 3 2: 3, 1: 1, 5: 1, 3: 0
6 Var6 0 1 FALSE 2 5: 4, 3: 1, 1: 0, 2: 0
7 Var7 0 1 FALSE 2 5: 4, 4: 1, 1: 0, 2: 0
8 Var8 0 1 FALSE 2 5: 4, 4: 1, 1: 0, 2: 0现在更有意义了。可以看出,对于变量Var1,无论答案类型5意味着什么,我们有4个答案5、一个答案1和零剩余答案。
但是,现在没有直方图了。好吧,我们很容易自己生产它们。
df %>% mutate_all(~factor(., 1:5)) %>%
pivot_longer(everything()) %>%
ggplot(aes(value))+
geom_histogram(stat="count")+
facet_grid(rows=vars(name))
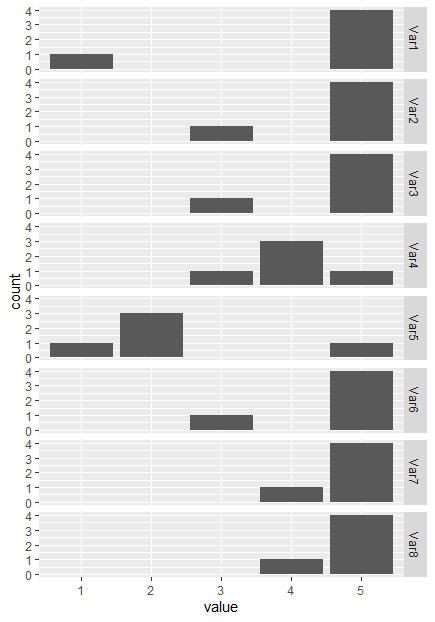
最后一点提示。当处理数据时,称其为更有意义的。根据您的比例输入相同的值。所以,我把你的变量稍微改成了问题和答案值,达到了以下的水平:“肯定是,是,我不知道,不,绝对不是”。
df = read.table(
header = TRUE,text="
Question1 Question2 Question3 Question4 Question5 Question6 Question7 Question8
def.not don't.know don't.know don't.know def.not don't.know yes yes
def.yes def.yes def.yes yes not def.yes def.yes def.yes
def.yes def.yes def.yes def.yes def.yes def.yes def.yes def.yes
def.yes def.yes def.yes yes not def.yes def.yes def.yes
def.yes def.yes def.yes yes not def.yes def.yes def.yes
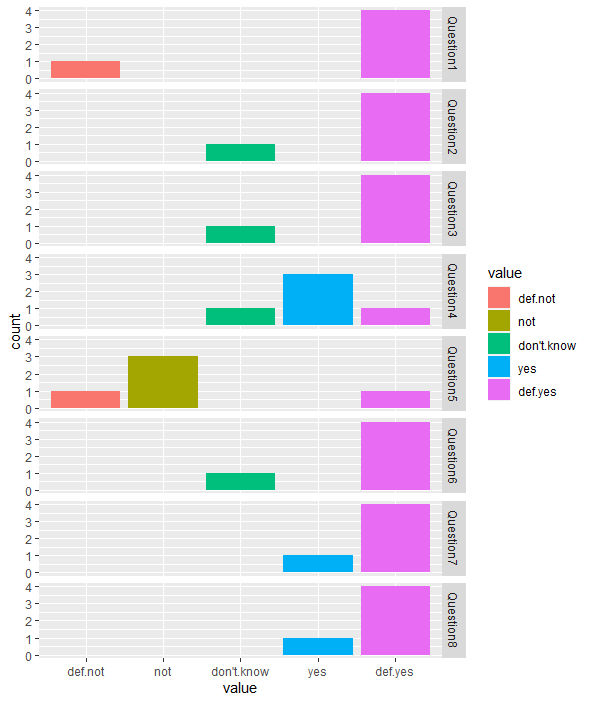
") %>% as_tibble() %>% mutate_all(~factor(., c("def.not", "not", "don't.know", "yes", "def.yes")))输出
# A tibble: 5 x 8
Question1 Question2 Question3 Question4 Question5 Question6 Question7 Question8
<fct> <fct> <fct> <fct> <fct> <fct> <fct> <fct>
1 def.not don't.know don't.know don't.know def.not don't.know yes yes
2 def.yes def.yes def.yes yes not def.yes def.yes def.yes
3 def.yes def.yes def.yes def.yes def.yes def.yes def.yes def.yes
4 def.yes def.yes def.yes yes not def.yes def.yes def.yes
5 def.yes def.yes def.yes yes not def.yes def.yes def.yes 现在你的直方图会更清晰,你不觉得吗?
df %>% pivot_longer(everything()) %>%
ggplot(aes(value))+
geom_histogram(stat="count")+
facet_grid(rows=vars(name))
https://stackoverflow.com/questions/69364822
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号