
计算x的r点对点法
我正在使用一个商业ELISA试剂盒,其中包含四个标准。这些标准是用来建立一个标准曲线,光密度从ELISA读取器的y轴和国际单位每英里在x轴的浓度。
我现在需要使用这个标准曲线来获得只有光密度读数的样品的浓度。ELISA试剂盒说明书明确规定“使用”点对点“绘制计算标准曲线的计算机”。
我假设它们的意思是求出x的值,通过看到y到达标准曲线上点之间的直线,然后从那里下降到x轴。问题是,我不知道如何在r中完成这个任务(这就是我所使用的全部分析管道)。我搜索了与“点对点”相对应的任何r包、函数或代码,但没有找到任何东西。所有处理ELISA数据和/或标准曲线的R包(例如drc和ELISAtools )似乎都做了一些更复杂的事情,比如拟合一个日志模型,并考虑板块间的差异等等,这不是我所需要的。
请注意,我不需要可视化标准曲线-我只需要一种方法,从标准曲线数据的浓度根据点对点线。
以下是一些示例数据:
# Data for standard curve:
scdt <- data.table(id = c("Cal1", "Cal2", "Cal3", "Cal4"),
conc = c(200, 100, 25, 5),
od = c(1.783, 1.395, 0.594, 0.164))
> scdt
id conc od
1: Cal1 200 1.783
2: Cal2 100 1.395
3: Cal3 25 0.594
4: Cal4 5 0.164
# Some example OD values for which I would like to derive concentration:
unknowns <- c(0.015, 0.634, 0.891, 1.510, 2.345, 3.105) 在我想为x求解的示例值中,我还包括了一些超出标准范围的值,因为这在我的实际数据中时有发生。试剂盒制造商建议不要报告任何OD值超过最高标准(Cal1)的情况,这是明智的。
我怎样才能用标准曲线上的标尺和图形纸求出x的R当量,这又是怎么回事呢?(我认为我可能找不到任何东西的原因之一是因为“点对点”不是一个数学术语,但必须有一个这样的术语--它是插值的吗?)
回答 1
Stack Overflow用户
发布于 2021-09-30 14:45:38
听起来你想要一个简单的线性插值。这是在R中使用函数approx实现的。给它输入已知的x值、已知的y值和需要对应y值的x的新值。(请注意,只要您是一致的,那么调用x和调用y的变量并不重要)。
为了获得更容易处理的结果,我们可以将响应转换为具有适当列名的数据框架:
new_data <- approx(scdt$od, scdt$conc, xout = unknowns) |>
setNames(c("od", "conc")) |>
as.data.frame()
new_data
#> od conc
#> 1 0.015 NA
#> 2 0.634 28.74532
#> 3 0.891 52.80899
#> 4 1.510 129.63918
#> 5 2.345 NA
#> 6 3.105 NA请注意(正如制造商所建议的),光密度超出校准点的极限范围将给出浓度的NA值。要得到这些,您需要进行外推,而不是插值。
为了确认这就是您要寻找的内容,让我们用红色绘制由初始数据形成的曲线上的插值结果:
plot(scdt$od, scdt$conc, type = "l", lty = 2)
points(scdt$od, scdt$conc)
points(new_data$od, new_data$conc, col = "red")
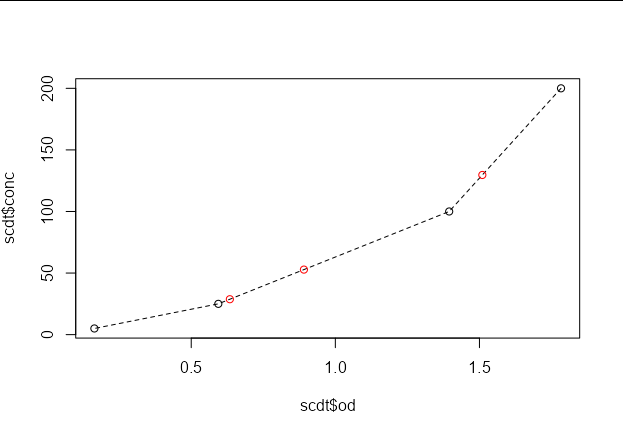
我们可以看到,每一种新的光密度的估计浓度都在连接校准点的线上。
https://stackoverflow.com/questions/69393999
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号