
精确计算一次包含给定单词的固定长度字符串的数目。
例如,给定固定长度的N=10和单词W=“雷达”。我们也知道我们有26个角色。
然后,我们可以“很容易”地计算字符串的数量,如:
雷达___ -> 26^5-26-1 (因为雷达和radaradar_不行)
___ -> 26^5-26
___ -> ___ 26^5
___ -> ___ 26^5
雷达-> 26^5-26
雷达-> 26^5-26-1
也就是71288150。有更好的方法来计算这个吗?即使N可以很大。
回答 1
Stack Overflow用户
发布于 2021-10-08 02:44:11
这个答案很大程度上是基于software engineering stack thread提出的一个相关问题,这个问题本身就是基于KMP算法的。
其思想是构建一个确定性有限自动机(DFA),其转换是小写字母,可以编码匹配模式0、一次或2+次的属性。例如,对于pattern =‘n’,我们有一个模式长度为5的模式长度,因此我们的DFA中将包含n + n + 1状态。把这些看作是3行的状态是有帮助的:
- Row
0,列i是对应于0完全匹配的状态,最后的i字母来自我们当前的部分匹配。 - Row
1,列i是对应于1完全匹配的状态,而最后一个d19字母是我们当前部分匹配的状态。H 220H 121Row 2有一个无法转义的状态:我们至少看到了2完全匹配。H 224F 225
我们的“争吵”只会不断增加。在代码中,实际上只有一个2n+1状态的平面列表,但这只是一个实现细节。
显示了“雷达”的DFA图的部分图:几乎所有的边都不是绘制的,因为每个状态都有26向外跃迁。通常,最多两个转换不会导致在行开始时返回“不匹配”状态(在这里,0和5),但是我也不能包括一些后边缘,其中networkx会使它们重叠。
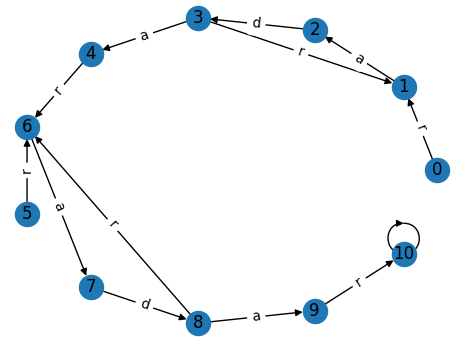
为了得到答案,我们需要在看到length = 10字母之后,计数处于每种可能状态的频率(从0开始)--好的状态是n, n+1 ... 2n-1,它正好对应于一个完全匹配的状态。为了生成转换矩阵,我们可以使用KMP算法中的前缀函数,几乎不作任何修改。第一行的DFA定义如下:
For state 0 <= i < n,
DFA[i][letter] = Length of longest suffix of (pattern[:i]+letter)
that is also a prefix of pattern请注意,状态n-1中的完全匹配将我们移到第1行。状态n <= i < 2n的定义是相同的,只是每个状态都由n向上移动。
使用numpy,我们可以相当快地使用矩阵幂得到一个答案:我们需要将一个粗略的2nx2n矩阵提高到我们固定的length的幂。如果length太大,您要么需要使用Python的大整数,要么使用模块化来避免溢出,一旦答案变得太大。然而,对于O(n^3 * log(length))的时间复杂度,可以用简单矩阵乘法进行重复平方运算。
def kmp_count(pattern: str, length: int) -> int:
if not pattern.islower():
raise ValueError("Pattern must be lowercase")
n = len(pattern)
if n > length:
return 0
if n == length:
return 1
if n == 1:
return length * pow(25, length - 1)
pattern_chars = [ord(x) - ord('a') for x in pattern]
# Create the DFA
dfa = [[0 for _ in range(26)] for _ in range(2 * n + 1)]
# Final failure state is an absorbing state
dfa[2 * n] = [2 * n for _ in range(26)]
dfa[0][pattern_chars[0]] = 1
restart_state = 0
for i in range(1, n):
dfa[i] = dfa[restart_state][:]
dfa[i][pattern_chars[i]] = i + 1
restart_state = dfa[restart_state][pattern_chars[i]]
dfa[n - 1][pattern_chars[n - 1]] += restart_state
for i in range(n, 2 * n):
dfa[i] = [x + n for x in dfa[i - n]]
# Two or more matches moves us to fail state
dfa[2 * n - 1][pattern_chars[n - 1]] = 2 * n
transitions = np.zeros((2 * n + 1, 2 * n + 1), dtype=np.int64)
for i, x in enumerate(dfa):
for y in x:
transitions[i][y] += 1
final_transitions = np.linalg.matrix_power(transitions, length)
return final_transitions[0, n:2 * n].sum()print(kmp_count(pattern='radar', length=10))
>>> 71288150https://stackoverflow.com/questions/69473756
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号