
对于流行的计算机视觉模型,是否有实际的最小输入图像大小?(例如,vgg、resnet等)
根据关于传递学习的预先训练的计算机视觉模型(例如这里)的文件,输入图像应该是“3通道RGB形状的图像(3xHxW)的迷你批次,其中H和W至少应该是224”。
然而,当在3通道图像上运行传输学习实验时,当图像的高度和宽度小于预期时(如小于224),网络通常运行平稳,性能良好。
因此,在我看来,“最小高度和宽度”在某种程度上是一个惯例,而不是一个关键的参数。我是不是漏掉了什么?
回答 2
Stack Overflow用户
发布于 2021-10-06 19:54:29
您的输入大小有一个限制,它对应于网络的最后一个卷积层的接收字段。直观地说,你可以观察到空间维数随着你通过网络而减少。至少这是用于从输入图像中提取特征嵌入的特征提取器CNN的情况。这是大多数预先训练的模型,如香草VGG,和ResNets网络不保留空间维数。如果卷积层的输入小于内核大小(即使/当填充时),那么您就无法执行该操作。
Stack Overflow用户
发布于 2022-01-11 22:24:23
例如,标准的resnet50模型只接受范围为193-225的输入,这是由于体系结构和向下缩放层造成的(见下文)。默认reason模型工作的唯一原因是它使用自适应池层,它允许不限制输入大小。所以它会起作用的,但是你应该准备好面对性能衰退和其他有趣的事情:)
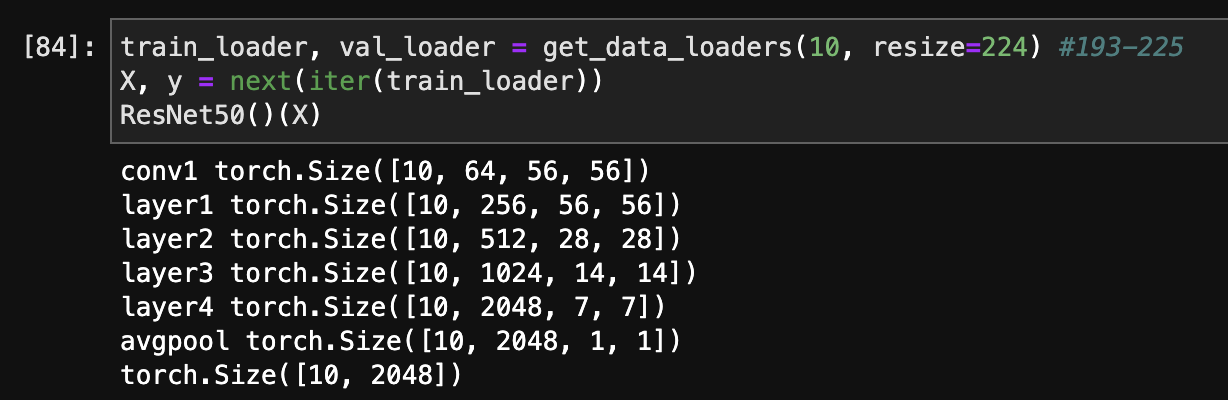
希望你会发现它有用:
- https://discuss.pytorch.org/t/how-can-torchvison-models-deal-with-image-whose-size-is-not-224-224/51077/3
- 什么是自适应平均池?它是如何工作的?
- https://pytorch.org/docs/stable/generated/torch.nn.AdaptiveAvgPool2d.html
- https://github.com/pytorch/vision/blob/c187c2b12d86c3909e59a40dbe49555d85b98703/torchvision/models/resnet.py#L118
- https://github.com/pytorch/vision/blob/c187c2b12d86c3909e59a40dbe49555d85b98703/torchvision/models/resnet.py#L151
- https://developpaper.com/pytorch-implementation-examples-of-resnet50-resnet101-and-resnet152/
https://stackoverflow.com/questions/69471729
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号