
R- mgsub问题:子字符串被替换,而不是整个字符串。
我从USPS下载了街道缩写。以下是数据:
dput(usps_streets)
structure(list(common_abbrev = c("allee", "alley", "ally", "aly",
"anex", "annex", "annx", "anx", "arc", "arcade", "av", "ave",
"aven", "avenu", "avenue", "avn", "avnue", "bayoo", "bayou",
"bch", "beach", "bend", "bnd", "blf", "bluf", "bluff", "bluffs",
"bot", "btm", "bottm", "bottom", "blvd", "boul", "boulevard",
"boulv", "br", "brnch", "branch", "brdge", "brg", "bridge", "brk",
"brook", "brooks", "burg", "burgs", "byp", "bypa", "bypas", "bypass",
"byps", "camp", "cp", "cmp", "canyn", "canyon", "cnyn", "cape",
"cpe", "causeway", "causwa", "cswy", "cen", "cent", "center",
"centr", "centre", "cnter", "cntr", "ctr", "centers", "cir",
"circ", "circl", "circle", "crcl", "crcle", "circles", "clf",
"cliff", "clfs", "cliffs", "clb", "club", "common", "commons",
"cor", "corner", "corners", "cors", "course", "crse", "court",
"ct", "courts", "cts", "cove", "cv", "coves", "creek", "crk",
"crescent", "cres", "crsent", "crsnt", "crest", "crossing", "crssng",
"xing", "crossroad", "crossroads", "curve", "dale", "dl", "dam",
"dm", "div", "divide", "dv", "dvd", "dr", "driv", "drive", "drv",
"drives", "est", "estate", "estates", "ests", "exp", "expr",
"express", "expressway", "expw", "expy", "ext", "extension",
"extn", "extnsn", "exts", "fall", "falls", "fls", "ferry", "frry",
"fry", "field", "fld", "fields", "flds", "flat", "flt", "flats",
"flts", "ford", "frd", "fords", "forest", "forests", "frst",
"forg", "forge", "frg", "forges", "fork", "frk", "forks", "frks",
"fort", "frt", "ft", "freeway", "freewy", "frway", "frwy", "fwy",
"garden", "gardn", "grden", "grdn", "gardens", "gdns", "grdns",
"gateway", "gatewy", "gatway", "gtway", "gtwy", "glen", "gln",
"glens", "green", "grn", "greens", "grov", "grove", "grv", "groves",
"harb", "harbor", "harbr", "hbr", "hrbor", "harbors", "haven",
"hvn", "ht", "hts", "highway", "highwy", "hiway", "hiwy", "hway",
"hwy", "hill", "hl", "hills", "hls", "hllw", "hollow", "hollows",
"holw", "holws", "inlt", "is", "island", "islnd", "islands",
"islnds", "iss", "isle", "isles", "jct", "jction", "jctn", "junction",
"junctn", "juncton", "jctns", "jcts", "junctions", "key", "ky",
"keys", "kys", "knl", "knol", "knoll", "knls", "knolls", "lk",
"lake", "lks", "lakes", "land", "landing", "lndg", "lndng", "lane",
"ln", "lgt", "light", "lights", "lf", "loaf", "lck", "lock",
"lcks", "locks", "ldg", "ldge", "lodg", "lodge", "loop", "loops",
"mall", "mnr", "manor", "manors", "mnrs", "meadow", "mdw", "mdws",
"meadows", "medows", "mews", "mill", "mills", "missn", "mssn",
"motorway", "mnt", "mt", "mount", "mntain", "mntn", "mountain",
"mountin", "mtin", "mtn", "mntns", "mountains", "nck", "neck",
"orch", "orchard", "orchrd", "oval", "ovl", "overpass", "park",
"prk", "parks", "parkway", "parkwy", "pkway", "pkwy", "pky",
"parkways", "pkwys", "pass", "passage", "path", "paths", "pike",
"pikes", "pine", "pines", "pnes", "pl", "plain", "pln", "plains",
"plns", "plaza", "plz", "plza", "point", "pt", "points", "pts",
"port", "prt", "ports", "prts", "pr", "prairie", "prr", "rad",
"radial", "radiel", "radl", "ramp", "ranch", "ranches", "rnch",
"rnchs", "rapid", "rpd", "rapids", "rpds", "rest", "rst", "rdg",
"rdge", "ridge", "rdgs", "ridges", "riv", "river", "rvr", "rivr",
"rd", "road", "roads", "rds", "route", "row", "rue", "run", "shl",
"shoal", "shls", "shoals", "shoar", "shore", "shr", "shoars",
"shores", "shrs", "skyway", "spg", "spng", "spring", "sprng",
"spgs", "spngs", "springs", "sprngs", "spur", "spurs", "sq",
"sqr", "sqre", "squ", "square", "sqrs", "squares", "sta", "station",
"statn", "stn", "stra", "strav", "straven", "stravenue", "stravn",
"strvn", "strvnue", "stream", "streme", "strm", "street", "strt",
"st", "str", "streets", "smt", "suite", "sumit", "sumitt", "summit",
"ter", "terr", "terrace", "throughway", "trace", "traces", "trce",
"track", "tracks", "trak", "trk", "trks", "trafficway", "trail",
"trails", "trl", "trls", "trailer", "trlr", "trlrs", "tunel",
"tunl", "tunls", "tunnel", "tunnels", "tunnl", "trnpk", "turnpike",
"turnpk", "underpass", "un", "union", "unions", "valley", "vally",
"vlly", "vly", "valleys", "vlys", "vdct", "via", "viadct", "viaduct",
"view", "vw", "views", "vws", "vill", "villag", "village", "villg",
"villiage", "vlg", "villages", "vlgs", "ville", "vl", "vis",
"vist", "vista", "vst", "vsta", "walk", "walks", "wall", "wy",
"way", "ways", "well", "wells", "wls"), usps_abbrev = c("aly",
"aly", "aly", "aly", "anx", "anx", "anx", "anx", "arc", "arc",
"ave", "ave", "ave", "ave", "ave", "ave", "ave", "byu", "byu",
"bch", "bch", "bnd", "bnd", "blf", "blf", "blf", "blfs", "btm",
"btm", "btm", "btm", "blvd", "blvd", "blvd", "blvd", "br", "br",
"br", "brg", "brg", "brg", "brk", "brk", "brks", "bg", "bgs",
"byp", "byp", "byp", "byp", "byp", "cp", "cp", "cp", "cyn", "cyn",
"cyn", "cpe", "cpe", "cswy", "cswy", "cswy", "ctr", "ctr", "ctr",
"ctr", "ctr", "ctr", "ctr", "ctr", "ctrs", "cir", "cir", "cir",
"cir", "cir", "cir", "cirs", "clf", "clf", "clfs", "clfs", "clb",
"clb", "cmn", "cmns", "cor", "cor", "cors", "cors", "crse", "crse",
"ct", "ct", "cts", "cts", "cv", "cv", "cvs", "crk", "crk", "cres",
"cres", "cres", "cres", "crst", "xing", "xing", "xing", "xrd",
"xrds", "curv", "dl", "dl", "dm", "dm", "dv", "dv", "dv", "dv",
"dr", "dr", "dr", "dr", "drs", "est", "est", "ests", "ests",
"expy", "expy", "expy", "expy", "expy", "expy", "ext", "ext",
"ext", "ext", "exts", "fall", "fls", "fls", "fry", "fry", "fry",
"fld", "fld", "flds", "flds", "flt", "flt", "flts", "flts", "frd",
"frd", "frds", "frst", "frst", "frst", "frg", "frg", "frg", "frgs",
"frk", "frk", "frks", "frks", "ft", "ft", "ft", "fwy", "fwy",
"fwy", "fwy", "fwy", "gdn", "gdn", "gdn", "gdn", "gdns", "gdns",
"gdns", "gtwy", "gtwy", "gtwy", "gtwy", "gtwy", "gln", "gln",
"glns", "grn", "grn", "grns", "grv", "grv", "grv", "grvs", "hbr",
"hbr", "hbr", "hbr", "hbr", "hbrs", "hvn", "hvn", "hts", "hts",
"hwy", "hwy", "hwy", "hwy", "hwy", "hwy", "hl", "hl", "hls",
"hls", "holw", "holw", "holw", "holw", "holw", "inlt", "is",
"is", "is", "iss", "iss", "iss", "isle", "isle", "jct", "jct",
"jct", "jct", "jct", "jct", "jcts", "jcts", "jcts", "ky", "ky",
"kys", "kys", "knl", "knl", "knl", "knls", "knls", "lk", "lk",
"lks", "lks", "land", "lndg", "lndg", "lndg", "ln", "ln", "lgt",
"lgt", "lgts", "lf", "lf", "lck", "lck", "lcks", "lcks", "ldg",
"ldg", "ldg", "ldg", "loop", "loop", "mall", "mnr", "mnr", "mnrs",
"mnrs", "mdw", "mdws", "mdws", "mdws", "mdws", "mews", "ml",
"mls", "msn", "msn", "mtwy", "mt", "mt", "mt", "mtn", "mtn",
"mtn", "mtn", "mtn", "mtn", "mtns", "mtns", "nck", "nck", "orch",
"orch", "orch", "oval", "oval", "opas", "park", "park", "park",
"pkwy", "pkwy", "pkwy", "pkwy", "pkwy", "pkwy", "pkwy", "pass",
"psge", "path", "path", "pike", "pike", "pne", "pnes", "pnes",
"pl", "pln", "pln", "plns", "plns", "plz", "plz", "plz", "pt",
"pt", "pts", "pts", "prt", "prt", "prts", "prts", "pr", "pr",
"pr", "radl", "radl", "radl", "radl", "ramp", "rnch", "rnch",
"rnch", "rnch", "rpd", "rpd", "rpds", "rpds", "rst", "rst", "rdg",
"rdg", "rdg", "rdgs", "rdgs", "riv", "riv", "riv", "riv", "rd",
"rd", "rds", "rds", "rte", "row", "rue", "run", "shl", "shl",
"shls", "shls", "shr", "shr", "shr", "shrs", "shrs", "shrs",
"skwy", "spg", "spg", "spg", "spg", "spgs", "spgs", "spgs", "spgs",
"spur", "spur", "sq", "sq", "sq", "sq", "sq", "sqs", "sqs", "sta",
"sta", "sta", "sta", "stra", "stra", "stra", "stra", "stra",
"stra", "stra", "strm", "strm", "strm", "st", "st", "st", "st",
"sts", "smt", "ste", "smt", "smt", "smt", "ter", "ter", "ter",
"trwy", "trce", "trce", "trce", "trak", "trak", "trak", "trak",
"trak", "trfy", "trl", "trl", "trl", "trl", "trlr", "trlr", "trlr",
"tunl", "tunl", "tunl", "tunl", "tunl", "tunl", "tpke", "tpke",
"tpke", "upas", "un", "un", "uns", "vly", "vly", "vly", "vly",
"vlys", "vlys", "via", "via", "via", "via", "vw", "vw", "vws",
"vws", "vlg", "vlg", "vlg", "vlg", "vlg", "vlg", "vlgs", "vlgs",
"vl", "vl", "vis", "vis", "vis", "vis", "vis", "walk", "walk",
"wall", "way", "way", "ways", "wl", "wls", "wls")), class = "data.frame", row.names = c(NA,
-503L))我想用它们来处理街道地址和州。玩具数据:
a <- c("10900 harper ave", "12235 davis annex", "24 van cortland parkway")为了将常见的缩写转换为usps缩写(标准化数据),我构建了一个小函数:
mr_zip <- function(x){
x <-textclean::mgsub(usps_streets$common_abbrev, usps_streets$usps_abbrev, x, fixed = T,
order.pattern = T)
return(x)
}当我将我的函数应用于我的数据时,问题就出现了:
f <- sapply(a, mr_zip)我得到了错误的结果:
"10900 harper avee" "1235 davis anx" "24 van cortland pkway"因为我应该得到的是:
"10900 harper ave" "1235 davis anx" "24 van cortland pkwy"我的问题:
- 当我在
order.pattern = T函数中指定fixed = T和fixed = T时,为什么会发生这种情况? - 我能做些什么来解决这个问题?
- 在文本的多个替代模式中是否有使用向量的替代方法?
谢谢,欢迎所有的建议。
编辑:多亏@RichieSacramento,我发现使用单词边界确实有帮助,但是在一个大的dataframe (> 400,000行)上使用这个函数的速度仍然非常慢。在safe = TRUE中使用mgsub可以使函数正常工作,但它非常慢。很快就会得到一些东西
回答 4
Stack Overflow用户
发布于 2021-10-29 22:03:14
更新
下面是对OP问题的基准测试(从@Marek Fiołka借用测试数据,但使用n <- 10000)
> mb1
Unit: milliseconds
expr min lq mean median
f_MK_conv2(df$addresses) 1409.0643 1470.3992 1612.09037 1631.3014
f_MK_replaceString(df, addresses) 50.1582 54.3035 94.53149 62.5772
f_TIC1(df$addresses) 394.5972 420.3283 461.50675 447.6186
f_TIC2(df$addresses) 1579.1868 1852.6873 2052.28388 1964.8845
f_TIC3(df$addresses) 65.8436 71.5448 93.36210 84.9698
uq max neval
1710.3459 1898.6773 20
116.3108 264.2616 20
499.4052 626.9240 20
2246.5562 2916.2253 20
102.7689 183.5121 20
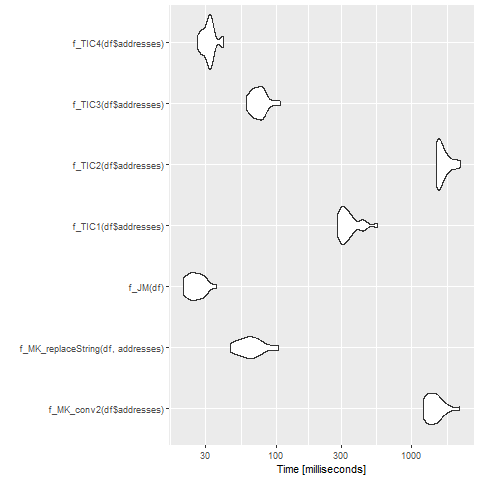
其中,基准代码如下所示
f_MK_conv2 <- function(x) {
USPSv <- array(
data = USPS$usps_abbrev,
dimnames = list(USPS$common_abbrev)
)
USPS_conv2 <- function(x) {
t <- str_split(x, " ")
comm <- t[[1]][length(t[[1]])]
str_replace(x, comm, USPSv[comm])
}
Vectorize(USPS_conv2)(x)
}
f_MK_replaceString <- function(.data, value) {
ht.create <- function() new.env()
ht.insert <- function(ht, key, value) ht[[key]] <- value
ht.insert <- Vectorize(ht.insert, c("key", "value"))
ht.lookup <- function(ht, key) ht[[key]]
ht.lookup <- Vectorize(ht.lookup, "key")
ht.delete <- function(ht, key) rm(list = key, envir = ht, inherits = FALSE)
ht.delete <- Vectorize(ht.delete, "key")
addHashTable2 <- function(.x, .y, key, value) {
key <- enquo(key)
value <- enquo(value)
if (!all(c(as_label(key), as_label(value)) %in% names(.y))) {
stop(paste0(
"`.y` must contain `", as_label(key),
"` and `", as_label(value), "` columns"
))
}
if ((.y %>% distinct(!!key, !!value) %>% nrow()) !=
(.y %>% distinct(!!key) %>% nrow())) {
warning(paste0(
"\nThe number of unique values of the ", as_label(key),
" variable is different\n",
" from the number of unique values of the ",
as_label(key), " and ", as_label(value), " pairs!\n",
"The dictionary will only return the last values for a given key!"
))
}
ht <- ht.create()
ht %>% ht.insert(
.y %>% distinct(!!key, !!value) %>% pull(!!key),
.y %>% distinct(!!key, !!value) %>% pull(!!value)
)
attr(.x, "hashTab") <- ht
.x
}
.data <- .data %>% addHashTable2(USPS, common_abbrev, usps_abbrev)
value <- enquo(value)
# Test whether the value variable is in .data
if (!(as_label(value) %in% names(.data))) {
stop(paste(
"The", as_label(value),
"variable does not exist in the .data table!"
))
}
# Dictionary attribute presence test
if (!("hashTab" %in% names(attributes(.data)))) {
stop(paste0(
"\nThere is no dictionary attribute in the .data table!\n",
"Use addHashTable or addHashTable2 to add a dictionary attribute."
))
}
txt <- .data %>% pull(!!value)
i <- sapply(strsplit(txt, ""), function(x) max(which(x == " ")))
txt <- paste0(
str_sub(txt, end = i),
ht.lookup(
attr(.data, "hashTab"),
str_sub(txt, start = i + 1)
)
)
.data %>% mutate(!!value := txt)
}
f_TIC1 <- function(x) {
sapply(
strsplit(x, " "),
function(x) {
with(USPS, {
idx <- match(x, common_abbrev)
paste0(ifelse(is.na(idx), x, usps_abbrev[idx]),
collapse = " "
)
})
}
)
}
f_TIC2 <- function(x) {
res <- c()
for (s in x) {
v <- unlist(strsplit(s, "\\W+"))
for (p in v) {
k <- match(p, USPS$common_abbrev)
if (!is.na(k)) {
s <- with(
USPS,
gsub(
sprintf("\\b%s\\b", common_abbrev[k]),
usps_abbrev[k],
s
)
)
}
}
res <- append(res, s)
}
res
}
f_TIC3 <- function(x) {
x.split <- strsplit(x, " ")
lut <- with(USPS, setNames(usps_abbrev, common_abbrev))
grp <- rep(seq_along(x.split), lengths(x.split))
xx <- unlist(x.split)
r <- lut[xx]
tapply(
replace(xx, !is.na(r), na.omit(r)),
grp,
function(s) paste0(s, collapse = " ")
)
}
f_TIC4 <- function(x) {
xb <- gsub("^.*\\s+", "", x)
rp <- with(USPS, usps_abbrev[match(xb, common_abbrev)])
paste0(gsub("\\w+$", "", x), replace(xb, !is.na(rp), na.omit(rp)))
}
f_JM <- function(x) {
x$abbreviation <- gsub("^.* ", "", x$addresses)
setDT(x)
setDT(USPS)
x[USPS, abbreviation := usps_abbrev, on = .(abbreviation = common_abbrev)]
x$usps_abbreviation <- paste(str_extract(x$addresses, "^.* "), x$abbreviation, sep = "")
}
set.seed(1111)
df <- randomAddresses(10000)
library(microbenchmark)
mb1 <- microbenchmark(
f_MK_conv2(df$addresses),
f_MK_replaceString(df, addresses),
f_JM(df),
f_TIC1(df$addresses),
f_TIC2(df$addresses),
f_TIC3(df$addresses),
f_TIC4(df$addresses),
times = 20L
)
ggplot2::autoplot(mb1)可能的解决办法
也许以下R基选项之一可能会有所帮助
- 解决方案1
f_TIC1 <- function(x) {
sapply(
strsplit(x, " "),
function(x) {
with(USPS, {
idx <- match(x, common_abbrev)
paste0(ifelse(is.na(idx), x, usps_abbrev[idx]),
collapse = " "
)
})
}
)
}- 解决方案2
f_TIC2 <- function(x) {
res <- c()
for (s in x) {
v <- unlist(strsplit(s, "\\W+"))
for (p in v) {
k <- match(p, USPS$common_abbrev)
if (!is.na(k)) {
s <- with(
USPS,
gsub(
sprintf("\\b%s\\b", common_abbrev[k]),
usps_abbrev[k],
s
)
)
}
}
res <- append(res, s)
}
res
}- 解决方案3
f_TIC3 <- function(x) {
x.split <- strsplit(x, " ")
lut <- with(USPS, setNames(usps_abbrev, common_abbrev))
grp <- rep(seq_along(x.split), lengths(x.split))
xx <- unlist(x.split)
r <- lut[xx]
tapply(
replace(xx, !is.na(r), na.omit(r)),
grp,
function(s) paste0(s, collapse = " ")
)
}- 解决方案4(--这是一个特例,即最后一个单词的缩写)
f_TIC4 <- function(x) {
xb <- gsub("^.*\\s+", "", x)
rp <- with(USPS, usps_abbrev[match(xb, common_abbrev)])
paste0(gsub("\\w+$", "", x), replace(xb, !is.na(rp), na.omit(rp)))
}输出
[1] "10900 harper ave" "12235 davis anx" "24 van cortland pkwy"Stack Overflow用户
发布于 2021-10-31 21:06:14
所以我们开始找乐子吧。
步骤1首先,我们将将您的数据加载到名为USPS的tibble中。
library(tidyverse)
USPS = tibble(
common_abbrev = c("allee", "alley", "ally", "aly",
"anex", "annex", "annx", "anx", "arc", "arcade", "av", "ave",
"aven", "avenu", "avenue", "avn", "avnue", "bayoo", "bayou",
"bch", "beach", "bend", "bnd", "blf", "bluf", "bluff", "bluffs",
"bot", "btm", "bottm", "bottom", "blvd", "boul", "boulevard",
"boulv", "br", "brnch", "branch", "brdge", "brg", "bridge", "brk",
"brook", "brooks", "burg", "burgs", "byp", "bypa", "bypas", "bypass",
"byps", "camp", "cp", "cmp", "canyn", "canyon", "cnyn", "cape",
"cpe", "causeway", "causwa", "cswy", "cen", "cent", "center",
"centr", "centre", "cnter", "cntr", "ctr", "centers", "cir",
"circ", "circl", "circle", "crcl", "crcle", "circles", "clf",
"cliff", "clfs", "cliffs", "clb", "club", "common", "commons",
"cor", "corner", "corners", "cors", "course", "crse", "court",
"ct", "courts", "cts", "cove", "cv", "coves", "creek", "crk",
"crescent", "cres", "crsent", "crsnt", "crest", "crossing", "crssng",
"xing", "crossroad", "crossroads", "curve", "dale", "dl", "dam",
"dm", "div", "divide", "dv", "dvd", "dr", "driv", "drive", "drv",
"drives", "est", "estate", "estates", "ests", "exp", "expr",
"express", "expressway", "expw", "expy", "ext", "extension",
"extn", "extnsn", "exts", "fall", "falls", "fls", "ferry", "frry",
"fry", "field", "fld", "fields", "flds", "flat", "flt", "flats",
"flts", "ford", "frd", "fords", "forest", "forests", "frst",
"forg", "forge", "frg", "forges", "fork", "frk", "forks", "frks",
"fort", "frt", "ft", "freeway", "freewy", "frway", "frwy", "fwy",
"garden", "gardn", "grden", "grdn", "gardens", "gdns", "grdns",
"gateway", "gatewy", "gatway", "gtway", "gtwy", "glen", "gln",
"glens", "green", "grn", "greens", "grov", "grove", "grv", "groves",
"harb", "harbor", "harbr", "hbr", "hrbor", "harbors", "haven",
"hvn", "ht", "hts", "highway", "highwy", "hiway", "hiwy", "hway",
"hwy", "hill", "hl", "hills", "hls", "hllw", "hollow", "hollows",
"holw", "holws", "inlt", "is", "island", "islnd", "islands",
"islnds", "iss", "isle", "isles", "jct", "jction", "jctn", "junction",
"junctn", "juncton", "jctns", "jcts", "junctions", "key", "ky",
"keys", "kys", "knl", "knol", "knoll", "knls", "knolls", "lk",
"lake", "lks", "lakes", "land", "landing", "lndg", "lndng", "lane",
"ln", "lgt", "light", "lights", "lf", "loaf", "lck", "lock",
"lcks", "locks", "ldg", "ldge", "lodg", "lodge", "loop", "loops",
"mall", "mnr", "manor", "manors", "mnrs", "meadow", "mdw", "mdws",
"meadows", "medows", "mews", "mill", "mills", "missn", "mssn",
"motorway", "mnt", "mt", "mount", "mntain", "mntn", "mountain",
"mountin", "mtin", "mtn", "mntns", "mountains", "nck", "neck",
"orch", "orchard", "orchrd", "oval", "ovl", "overpass", "park",
"prk", "parks", "parkway", "parkwy", "pkway", "pkwy", "pky",
"parkways", "pkwys", "pass", "passage", "path", "paths", "pike",
"pikes", "pine", "pines", "pnes", "pl", "plain", "pln", "plains",
"plns", "plaza", "plz", "plza", "point", "pt", "points", "pts",
"port", "prt", "ports", "prts", "pr", "prairie", "prr", "rad",
"radial", "radiel", "radl", "ramp", "ranch", "ranches", "rnch",
"rnchs", "rapid", "rpd", "rapids", "rpds", "rest", "rst", "rdg",
"rdge", "ridge", "rdgs", "ridges", "riv", "river", "rvr", "rivr",
"rd", "road", "roads", "rds", "route", "row", "rue", "run", "shl",
"shoal", "shls", "shoals", "shoar", "shore", "shr", "shoars",
"shores", "shrs", "skyway", "spg", "spng", "spring", "sprng",
"spgs", "spngs", "springs", "sprngs", "spur", "spurs", "sq",
"sqr", "sqre", "squ", "square", "sqrs", "squares", "sta", "station",
"statn", "stn", "stra", "strav", "straven", "stravenue", "stravn",
"strvn", "strvnue", "stream", "streme", "strm", "street", "strt",
"st", "str", "streets", "smt", "suite", "sumit", "sumitt", "summit",
"ter", "terr", "terrace", "throughway", "trace", "traces", "trce",
"track", "tracks", "trak", "trk", "trks", "trafficway", "trail",
"trails", "trl", "trls", "trailer", "trlr", "trlrs", "tunel",
"tunl", "tunls", "tunnel", "tunnels", "tunnl", "trnpk", "turnpike",
"turnpk", "underpass", "un", "union", "unions", "valley", "vally",
"vlly", "vly", "valleys", "vlys", "vdct", "via", "viadct", "viaduct",
"view", "vw", "views", "vws", "vill", "villag", "village", "villg",
"villiage", "vlg", "villages", "vlgs", "ville", "vl", "vis",
"vist", "vista", "vst", "vsta", "walk", "walks", "wall", "wy",
"way", "ways", "well", "wells", "wls"),
usps_abbrev = c("aly",
"aly", "aly", "aly", "anx", "anx", "anx", "anx", "arc", "arc",
"ave", "ave", "ave", "ave", "ave", "ave", "ave", "byu", "byu",
"bch", "bch", "bnd", "bnd", "blf", "blf", "blf", "blfs", "btm",
"btm", "btm", "btm", "blvd", "blvd", "blvd", "blvd", "br", "br",
"br", "brg", "brg", "brg", "brk", "brk", "brks", "bg", "bgs",
"byp", "byp", "byp", "byp", "byp", "cp", "cp", "cp", "cyn", "cyn",
"cyn", "cpe", "cpe", "cswy", "cswy", "cswy", "ctr", "ctr", "ctr",
"ctr", "ctr", "ctr", "ctr", "ctr", "ctrs", "cir", "cir", "cir",
"cir", "cir", "cir", "cirs", "clf", "clf", "clfs", "clfs", "clb",
"clb", "cmn", "cmns", "cor", "cor", "cors", "cors", "crse", "crse",
"ct", "ct", "cts", "cts", "cv", "cv", "cvs", "crk", "crk", "cres",
"cres", "cres", "cres", "crst", "xing", "xing", "xing", "xrd",
"xrds", "curv", "dl", "dl", "dm", "dm", "dv", "dv", "dv", "dv",
"dr", "dr", "dr", "dr", "drs", "est", "est", "ests", "ests",
"expy", "expy", "expy", "expy", "expy", "expy", "ext", "ext",
"ext", "ext", "exts", "fall", "fls", "fls", "fry", "fry", "fry",
"fld", "fld", "flds", "flds", "flt", "flt", "flts", "flts", "frd",
"frd", "frds", "frst", "frst", "frst", "frg", "frg", "frg", "frgs",
"frk", "frk", "frks", "frks", "ft", "ft", "ft", "fwy", "fwy",
"fwy", "fwy", "fwy", "gdn", "gdn", "gdn", "gdn", "gdns", "gdns",
"gdns", "gtwy", "gtwy", "gtwy", "gtwy", "gtwy", "gln", "gln",
"glns", "grn", "grn", "grns", "grv", "grv", "grv", "grvs", "hbr",
"hbr", "hbr", "hbr", "hbr", "hbrs", "hvn", "hvn", "hts", "hts",
"hwy", "hwy", "hwy", "hwy", "hwy", "hwy", "hl", "hl", "hls",
"hls", "holw", "holw", "holw", "holw", "holw", "inlt", "is",
"is", "is", "iss", "iss", "iss", "isle", "isle", "jct", "jct",
"jct", "jct", "jct", "jct", "jcts", "jcts", "jcts", "ky", "ky",
"kys", "kys", "knl", "knl", "knl", "knls", "knls", "lk", "lk",
"lks", "lks", "land", "lndg", "lndg", "lndg", "ln", "ln", "lgt",
"lgt", "lgts", "lf", "lf", "lck", "lck", "lcks", "lcks", "ldg",
"ldg", "ldg", "ldg", "loop", "loop", "mall", "mnr", "mnr", "mnrs",
"mnrs", "mdw", "mdws", "mdws", "mdws", "mdws", "mews", "ml",
"mls", "msn", "msn", "mtwy", "mt", "mt", "mt", "mtn", "mtn",
"mtn", "mtn", "mtn", "mtn", "mtns", "mtns", "nck", "nck", "orch",
"orch", "orch", "oval", "oval", "opas", "park", "park", "park",
"pkwy", "pkwy", "pkwy", "pkwy", "pkwy", "pkwy", "pkwy", "pass",
"psge", "path", "path", "pike", "pike", "pne", "pnes", "pnes",
"pl", "pln", "pln", "plns", "plns", "plz", "plz", "plz", "pt",
"pt", "pts", "pts", "prt", "prt", "prts", "prts", "pr", "pr",
"pr", "radl", "radl", "radl", "radl", "ramp", "rnch", "rnch",
"rnch", "rnch", "rpd", "rpd", "rpds", "rpds", "rst", "rst", "rdg",
"rdg", "rdg", "rdgs", "rdgs", "riv", "riv", "riv", "riv", "rd",
"rd", "rds", "rds", "rte", "row", "rue", "run", "shl", "shl",
"shls", "shls", "shr", "shr", "shr", "shrs", "shrs", "shrs",
"skwy", "spg", "spg", "spg", "spg", "spgs", "spgs", "spgs", "spgs",
"spur", "spur", "sq", "sq", "sq", "sq", "sq", "sqs", "sqs", "sta",
"sta", "sta", "sta", "stra", "stra", "stra", "stra", "stra",
"stra", "stra", "strm", "strm", "strm", "st", "st", "st", "st",
"sts", "smt", "ste", "smt", "smt", "smt", "ter", "ter", "ter",
"trwy", "trce", "trce", "trce", "trak", "trak", "trak", "trak",
"trak", "trfy", "trl", "trl", "trl", "trl", "trlr", "trlr", "trlr",
"tunl", "tunl", "tunl", "tunl", "tunl", "tunl", "tpke", "tpke",
"tpke", "upas", "un", "un", "uns", "vly", "vly", "vly", "vly",
"vlys", "vlys", "via", "via", "via", "via", "vw", "vw", "vws",
"vws", "vlg", "vlg", "vlg", "vlg", "vlg", "vlg", "vlgs", "vlgs",
"vl", "vl", "vis", "vis", "vis", "vis", "vis", "walk", "walk",
"wall", "way", "way", "ways", "wl", "wls", "wls"))
USPS输出
# A tibble: 503 x 2
common_abbrev usps_abbrev
<chr> <chr>
1 allee aly
2 alley aly
3 ally aly
4 aly aly
5 anex anx
6 annex anx
7 annx anx
8 anx anx
9 arc arc
10 arcade arc
# ... with 493 more rows步骤2现在我们将把您的USPS表转换成一个带有命名元素的向量。
USPSv = array(data = USPS$usps_abbrev,
dimnames= list(USPS$common_abbrev))让我们看看它给了我们什么
USPSv['viadct']
# viadct
# "via"
USPSv['coves']
# coves
# "cvs" 看起来很诱人。
步骤3现在让我们创建一个转换(向量化)函数,它使用我们的USPSv向量和命名的元素。
USPS_conv = function(x) {
comm = str_split(x, " ") %>% .[[1]] %>% .[length(.)]
str_replace(x, comm, USPSv[comm])
}
USPS_conv = Vectorize(USPS_conv)让我们看看我们的USPS_conv是如何工作的。
USPS_conv("10900 harper coves")
# 10900 harper coves
# "10900 harper cvs"
USPS_conv("10900 harper viadct")
# 10900 harper viadct
# "10900 harper via"很好,但是它能处理向量吗?
USPS_conv(c("10900 harper coves", "10900 harper viadct", "10900 harper ave"))
# 10900 harper coves 10900 harper viadct 10900 harper ave
# "10900 harper cvs" "10900 harper via" "10900 harper ave" 到目前为止一切都很顺利。
步骤4现在是在mutate函数中使用USPS_conv函数的时候了。然而,我们需要一些输入数据。我们将自己创造它们。
n=10
set.seed(1111)
df = tibble(
addresses = paste(
sample(10:10000, n, replace = TRUE),
sample(c("harper", "davis", "van cortland", "marry", "von brown"), n, replace = TRUE),
sample(USPS$common_abbrev, n, replace = TRUE)
)
)
df输出
# A tibble: 10 x 1
addresses
<chr>
1 8995 davis crk
2 8527 davis tunnl
3 7663 von brown wall
4 3043 harper lake
5 9192 von brown grdn
6 120 marry rvr
7 72 von brown locks
8 8752 marry gardn
9 7754 davis corner
10 3745 davis jcts 让我们做一个突变
df %>% mutate(addresses = USPS_conv(addresses))输出
# A tibble: 10 x 1
addresses
<chr>
1 8995 davis crk
2 8527 davis tunl
3 7663 von brown wall
4 3043 harper lk
5 9192 von brown gdn
6 120 marry riv
7 72 von brown lcks
8 8752 marry gdn
9 7754 davis cor
10 3745 davis jcts 看上去还好吗?似乎是最棒的。
步骤5,所以是时候进行1,000,000个地址的测试了!我们将像以前一样生成数据。
n=1000000
set.seed(1111)
df = tibble(
addresses = paste(
sample(10:10000, n, replace = TRUE),
sample(c("harper", "davis", "van cortland", "marry", "von brown"), n, replace = TRUE),
sample(USPS$common_abbrev, n, replace = TRUE)
)
)
df输出
# A tibble: 1,000,000 x 1
addresses
<chr>
1 8995 marry pass
2 8527 davis spng
3 7663 marry loaf
4 3043 davis common
5 9192 marry bnd
6 120 von brown corner
7 72 van cortland plains
8 8752 van cortland crcle
9 7754 von brown sqrs
10 3745 marry key
# ... with 999,990 more rows所以我们走吧。但让我们立即衡量一下需要多长时间。
start_time =Sys.time()
df %>% mutate(addresses = USPS_conv(addresses))
Sys.time()-start_time
#Time difference of 3.610211 mins如你所见,我花了不到4分钟。我不知道你是否期待更快的事情,你是否对这一次感到满意。我将等待你的评论。
最后一分钟更新
事实证明,如果我们稍微修改USPS_conv的代码,它可以稍微加快速度。
USPS_conv2 = function(x) {
t = str_split(x, " ")
comm = t[[1]][length(t[[1]])]
str_replace(x, comm, USPSv[comm])
}
USPS_conv2 = Vectorize(USPS_conv2)新的USPS_conv2函数工作得稍微快一些。
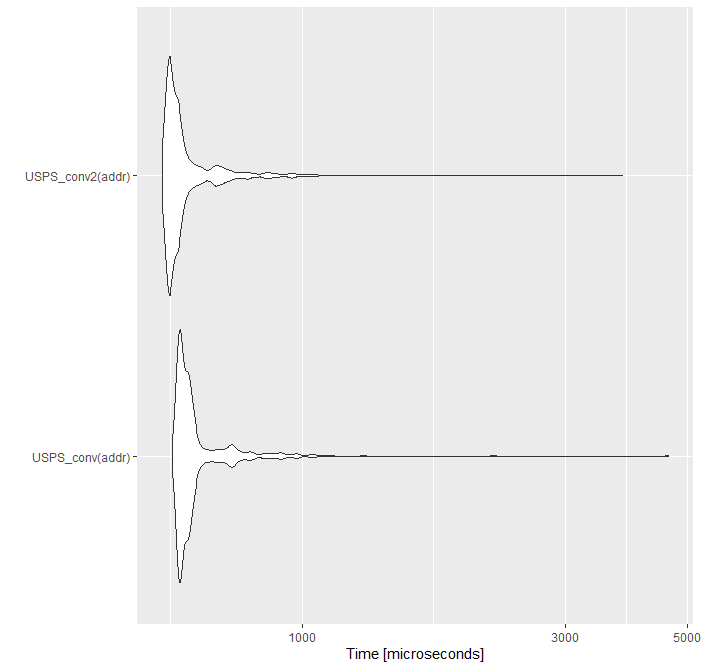
所有这一切都转化为将一百万个记录的突变时间缩短到3.3分钟。
超级速度的大更新!!
我意识到,我的第一个答案,虽然结构简单,但有点慢。所以我决定想出更快的办法。我将在这里分享我的想法,但请注意,一些解决方案将是有点“神奇”。
魔法词典-环境
为了加快操作速度,我们需要创建一个字典,它将快速地将键转换为值。我们将使用R中的环境创建它。
这是我们字典的一个小接口。
#Simple Dictionary (hash Table) Interface for R
ht.create = function() new.env()
ht.insert = function(ht, key, value) ht[[key]] <- value
ht.insert = Vectorize(ht.insert, c("key", "value"))
ht.lookup = function(ht, key) ht[[key]]
ht.lookup = Vectorize(ht.lookup, "key")
ht.delete = function(ht, key) rm(list=key,envir=ht,inherits=FALSE)
ht.delete = Vectorize(ht.delete, "key")是怎么发生的。我已经出现了。下面我将创建一个新的字典--环境ht.create(),我将在其中添加两个元素"a1“和"a2”ht.insert,其值分别为"va1“和"va2”。最后,我将使用这些ht.lookup键的值询问我的环境字典。
ht1 = ht.create()
ht.insert(ht1, "a1", "va1" )
ht1 %>% ht.insert("a2", "va2")
ht.lookup(ht1, "a1")
# a1
# "va1"
ht1 %>% ht.lookup("a2")
# a2
# "va2"请注意,函数ht.insert和ht.lookup是矢量化的,这意味着我将能够将整个向量添加到字典中。同样,我也可以通过给出完整的向量来查询我的字典。
ht.insert(ht1, paste0("a", 1:10),paste0("va", 1:10))
ht1 %>% ht.insert( paste0("a", 11:20),paste0("va", 11:20))
ht.lookup(ht1, paste0("a", 10:1))
# a10 a9 a8 a7 a6 a5 a4 a3 a2 a1
# "va10" "va9" "va8" "va7" "va6" "va5" "va4" "va3" "va2" "va1"
ht1 %>% ht.lookup(paste0("a", 20:11))
# a20 a19 a18 a17 a16 a15 a14 a13 a12 a11
# "va20" "va19" "va18" "va17" "va16" "va15" "va14" "va13" "va12" "va11"幻象属性
现在,我们将执行一个函数,该函数将向所选的字典-环境表添加一个附加属性。
#Functions that add a dictionary attribute to tibble
addHashTable = function(.data, key, value){
key = enquo(key)
value = enquo(value)
if (!all(c(as_label(key), as_label(value)) %in% names(.data))) {
stop(paste0("`.data` must contain `", as_label(key),
"` and `", as_label(value), "` columns"))
}
if((.data %>% distinct(!!key, !!value) %>% nrow)!=
(.data %>% distinct(!!key) %>% nrow)){
warning(paste0(
"\nThe number of unique values of the ", as_label(key),
" variable is different\n",
" from the number of unique values of the ",
as_label(key), " and ", as_label(value)," pairs!\n",
"The dictionary will only return the last values for a given key!"))
}
ht = ht.create()
ht %>% ht.insert(.data %>% distinct(!!key, !!value) %>% pull(!!key),
.data %>% distinct(!!key, !!value) %>% pull(!!value))
attr(.data, "hashTab") = ht
.data
}
addHashTable2 = function(.x, .y, key, value){
key = enquo(key)
value = enquo(value)
if (!all(c(as_label(key), as_label(value)) %in% names(.y))) {
stop(paste0("`.y` must contain `", as_label(key),
"` and `", as_label(value), "` columns"))
}
if((.y %>% distinct(!!key, !!value) %>% nrow)!=
(.y %>% distinct(!!key) %>% nrow)){
warning(paste0(
"\nThe number of unique values of the ", as_label(key),
" variable is different\n",
" from the number of unique values of the ",
as_label(key), " and ", as_label(value)," pairs!\n",
"The dictionary will only return the last values for a given key!"))
}
ht = ht.create()
ht %>% ht.insert(.y %>% distinct(!!key, !!value) %>% pull(!!key),
.y %>% distinct(!!key, !!value) %>% pull(!!value))
attr(.x, "hashTab") = ht
.x
}实际上有两种功能。addHashTable函数将字典环境属性添加到获取键值对的同一表中。addHashTable2函数同样添加到字典环境表中,但从另一个表中检索密钥对。
让我们看看addHashTable是如何工作的。
USPS = USPS %>% addHashTable(common_abbrev, usps_abbrev)
str(USPS)
# tibble [503 x 2] (S3: tbl_df/tbl/data.frame)
# $ common_abbrev: chr [1:503] "allee" "alley" "ally" "aly" ...
# $ usps_abbrev : chr [1:503] "aly" "aly" "aly" "aly" ...
# - attr(*, "hashTab")=<environment: 0x000000001591bbf0>如您所见,已经向指向USPS环境的0x000000001591bbf0表添加了一个属性。
替换函数
我们需要创建一个函数,它将使用以这种方式添加的字典环境来用字典中的相应值替换指定变量的最后一个单词。这就是了。
replaceString = function(.data, value){
value = enquo(value)
#Test whether the value variable is in .data
if(!(as_label(value) %in% names(.data))){
stop(paste("The", as_label(value),
"variable does not exist in the .data table!"))
}
#Dictionary attribute presence test
if(!("hashTab" %in% names(attributes(.data)))) {
stop(paste0(
"\nThere is no dictionary attribute in the .data table!\n",
"Use addHashTable or addHashTable2 to add a dictionary attribute."))
}
txt = .data %>% pull(!!value)
i = sapply(strsplit(txt, ""), function(x) max(which(x==" ")))
txt = paste0(str_sub(txt, end=i),
ht.lookup(attr(.data, "hashTab"),
str_sub(txt, start=i+1)))
.data %>% mutate(!!value := txt)
}首次试验
现在是第一篇课文的时候了。为了避免复制代码,我添加了一个小函数,它返回一个具有随机选择地址的表。
randomAddresses = function(n){
tibble(
addresses = paste(
sample(10:10000, n, replace = TRUE),
sample(c("harper", "davis", "van cortland", "marry", "von brown"), n, replace = TRUE),
sample(USPS$common_abbrev, n, replace = TRUE)
)
)
}
set.seed(1111)
df = randomAddresses(10)
df
# # A tibble: 10 x 1
# addresses
# <chr>
# 1 74 marry forges
# 2 787 von brown knol
# 3 2755 van cortland summit
# 4 9405 harper plaza
# 5 5376 marry pass
# 6 1857 marry trailer
# 7 9810 von brown drv
# 8 7984 davis garden
# 9 9110 marry alley
# 10 6458 von brown row是时候使用我们神奇的文本替换功能了。但是,请记住先将字典环境添加到表中。
df = df %>% addHashTable2(USPS, common_abbrev, usps_abbrev)
df %>% replaceString(addresses)
# A tibble: 10 x 1
# addresses
# <chr>
# 1 74 marry frgs
# 2 787 von brown knl
# 3 2755 van cortland smt
# 4 9405 harper plz
# 5 5376 marry pass
# 6 1857 marry trlr
# 7 9810 von brown dr
# 8 7984 davis gdn
# 9 9110 marry aly
# 10 6458 von brown row看起来很管用!
大试验
没什么好等的。现在,让我们在一个具有百万行的表上试一试。让我们立即测量绘制地址和添加字典环境所需的时间。
start_time =Sys.time()
df = randomAddresses(1000000)
df = df %>% addHashTable2(USPS, common_abbrev, usps_abbrev)
Sys.time()-start_time
#Time difference of 1.56609 secs耳垂
df
# A tibble: 1,000,000 x 1
# addresses
# <chr>
# 1 8995 marry pass
# 2 8527 davis spng
# 3 7663 marry loaf
# 4 3043 davis common
# 5 9192 marry bnd
# 6 120 von brown corner
# 7 72 van cortland plains
# 8 8752 van cortland crcle
# 9 7754 von brown sqrs
# 10 3745 marry key
# # ... with 999,990 more rows1.6秒可能不算太多。然而,最大的问题是替换缩写需要多长时间。
start_time =Sys.time()
df = df %>% replaceString(addresses)
Sys.time()-start_time
#Time difference of 8.316476 secs输出
# A tibble: 1,000,000 x 1
# addresses
# <chr>
# 1 8995 marry pass
# 2 8527 davis spg
# 3 7663 marry lf
# 4 3043 davis cmn
# 5 9192 marry bnd
# 6 120 von brown cor
# 7 72 van cortland plns
# 8 8752 van cortland cir
# 9 7754 von brown sqs
# 10 3745 marry ky
# # ... with 999,990 more rows砰!!我们还有8秒!!
我相信在R中不能建立更快的机制。
@ThomasIsCoding的小更新
下面是一个小的基准。注意,我从@ThomasIsCoding借用了函数f_MK_conv2、f_TIC1和f_TIC2的代码。
set.seed(1111)
df = randomAddresses(10000)
df = df %>% addHashTable2(USPS, common_abbrev, usps_abbrev)
library(microbenchmark)
mb1 = microbenchmark(
f_MK_conv2(df$addresses),
f_TIC1(df$addresses),
f_TIC2(df$addresses),
replaceString(df, addresses),
times = 20L
)
ggplot2::autoplot(mb1)
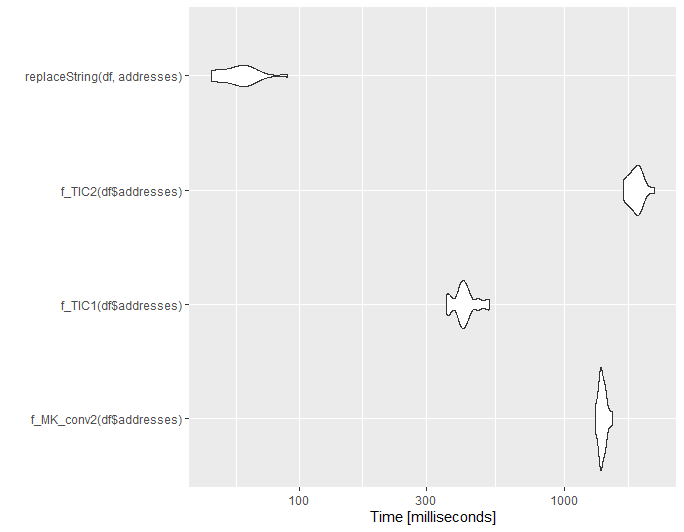
Stack Overflow用户
发布于 2021-11-04 19:58:38
特别是@jvalenti
这是一个特殊的答案,您将在其中找到修改过的函数和任务所需的所有代码。
library(tidyverse)
USPS = tibble(
common_abbrev = c("allee", "alley", "ally", "aly",
"anex", "annex", "annx", "anx", "arc", "arcade", "av", "ave",
"aven", "avenu", "avenue", "avn", "avnue", "bayoo", "bayou",
"bch", "beach", "bend", "bnd", "blf", "bluf", "bluff", "bluffs",
"bot", "btm", "bottm", "bottom", "blvd", "boul", "boulevard",
"boulv", "br", "brnch", "branch", "brdge", "brg", "bridge", "brk",
"brook", "brooks", "burg", "burgs", "byp", "bypa", "bypas", "bypass",
"byps", "camp", "cp", "cmp", "canyn", "canyon", "cnyn", "cape",
"cpe", "causeway", "causwa", "cswy", "cen", "cent", "center",
"centr", "centre", "cnter", "cntr", "ctr", "centers", "cir",
"circ", "circl", "circle", "crcl", "crcle", "circles", "clf",
"cliff", "clfs", "cliffs", "clb", "club", "common", "commons",
"cor", "corner", "corners", "cors", "course", "crse", "court",
"ct", "courts", "cts", "cove", "cv", "coves", "creek", "crk",
"crescent", "cres", "crsent", "crsnt", "crest", "crossing", "crssng",
"xing", "crossroad", "crossroads", "curve", "dale", "dl", "dam",
"dm", "div", "divide", "dv", "dvd", "dr", "driv", "drive", "drv",
"drives", "est", "estate", "estates", "ests", "exp", "expr",
"express", "expressway", "expw", "expy", "ext", "extension",
"extn", "extnsn", "exts", "fall", "falls", "fls", "ferry", "frry",
"fry", "field", "fld", "fields", "flds", "flat", "flt", "flats",
"flts", "ford", "frd", "fords", "forest", "forests", "frst",
"forg", "forge", "frg", "forges", "fork", "frk", "forks", "frks",
"fort", "frt", "ft", "freeway", "freewy", "frway", "frwy", "fwy",
"garden", "gardn", "grden", "grdn", "gardens", "gdns", "grdns",
"gateway", "gatewy", "gatway", "gtway", "gtwy", "glen", "gln",
"glens", "green", "grn", "greens", "grov", "grove", "grv", "groves",
"harb", "harbor", "harbr", "hbr", "hrbor", "harbors", "haven",
"hvn", "ht", "hts", "highway", "highwy", "hiway", "hiwy", "hway",
"hwy", "hill", "hl", "hills", "hls", "hllw", "hollow", "hollows",
"holw", "holws", "inlt", "is", "island", "islnd", "islands",
"islnds", "iss", "isle", "isles", "jct", "jction", "jctn", "junction",
"junctn", "juncton", "jctns", "jcts", "junctions", "key", "ky",
"keys", "kys", "knl", "knol", "knoll", "knls", "knolls", "lk",
"lake", "lks", "lakes", "land", "landing", "lndg", "lndng", "lane",
"ln", "lgt", "light", "lights", "lf", "loaf", "lck", "lock",
"lcks", "locks", "ldg", "ldge", "lodg", "lodge", "loop", "loops",
"mall", "mnr", "manor", "manors", "mnrs", "meadow", "mdw", "mdws",
"meadows", "medows", "mews", "mill", "mills", "missn", "mssn",
"motorway", "mnt", "mt", "mount", "mntain", "mntn", "mountain",
"mountin", "mtin", "mtn", "mntns", "mountains", "nck", "neck",
"orch", "orchard", "orchrd", "oval", "ovl", "overpass", "park",
"prk", "parks", "parkway", "parkwy", "pkway", "pkwy", "pky",
"parkways", "pkwys", "pass", "passage", "path", "paths", "pike",
"pikes", "pine", "pines", "pnes", "pl", "plain", "pln", "plains",
"plns", "plaza", "plz", "plza", "point", "pt", "points", "pts",
"port", "prt", "ports", "prts", "pr", "prairie", "prr", "rad",
"radial", "radiel", "radl", "ramp", "ranch", "ranches", "rnch",
"rnchs", "rapid", "rpd", "rapids", "rpds", "rest", "rst", "rdg",
"rdge", "ridge", "rdgs", "ridges", "riv", "river", "rvr", "rivr",
"rd", "road", "roads", "rds", "route", "row", "rue", "run", "shl",
"shoal", "shls", "shoals", "shoar", "shore", "shr", "shoars",
"shores", "shrs", "skyway", "spg", "spng", "spring", "sprng",
"spgs", "spngs", "springs", "sprngs", "spur", "spurs", "sq",
"sqr", "sqre", "squ", "square", "sqrs", "squares", "sta", "station",
"statn", "stn", "stra", "strav", "straven", "stravenue", "stravn",
"strvn", "strvnue", "stream", "streme", "strm", "street", "strt",
"st", "str", "streets", "smt", "suite", "sumit", "sumitt", "summit",
"ter", "terr", "terrace", "throughway", "trace", "traces", "trce",
"track", "tracks", "trak", "trk", "trks", "trafficway", "trail",
"trails", "trl", "trls", "trailer", "trlr", "trlrs", "tunel",
"tunl", "tunls", "tunnel", "tunnels", "tunnl", "trnpk", "turnpike",
"turnpk", "underpass", "un", "union", "unions", "valley", "vally",
"vlly", "vly", "valleys", "vlys", "vdct", "via", "viadct", "viaduct",
"view", "vw", "views", "vws", "vill", "villag", "village", "villg",
"villiage", "vlg", "villages", "vlgs", "ville", "vl", "vis",
"vist", "vista", "vst", "vsta", "walk", "walks", "wall", "wy",
"way", "ways", "well", "wells", "wls"),
usps_abbrev = c("aly",
"aly", "aly", "aly", "anx", "anx", "anx", "anx", "arc", "arc",
"ave", "ave", "ave", "ave", "ave", "ave", "ave", "byu", "byu",
"bch", "bch", "bnd", "bnd", "blf", "blf", "blf", "blfs", "btm",
"btm", "btm", "btm", "blvd", "blvd", "blvd", "blvd", "br", "br",
"br", "brg", "brg", "brg", "brk", "brk", "brks", "bg", "bgs",
"byp", "byp", "byp", "byp", "byp", "cp", "cp", "cp", "cyn", "cyn",
"cyn", "cpe", "cpe", "cswy", "cswy", "cswy", "ctr", "ctr", "ctr",
"ctr", "ctr", "ctr", "ctr", "ctr", "ctrs", "cir", "cir", "cir",
"cir", "cir", "cir", "cirs", "clf", "clf", "clfs", "clfs", "clb",
"clb", "cmn", "cmns", "cor", "cor", "cors", "cors", "crse", "crse",
"ct", "ct", "cts", "cts", "cv", "cv", "cvs", "crk", "crk", "cres",
"cres", "cres", "cres", "crst", "xing", "xing", "xing", "xrd",
"xrds", "curv", "dl", "dl", "dm", "dm", "dv", "dv", "dv", "dv",
"dr", "dr", "dr", "dr", "drs", "est", "est", "ests", "ests",
"expy", "expy", "expy", "expy", "expy", "expy", "ext", "ext",
"ext", "ext", "exts", "fall", "fls", "fls", "fry", "fry", "fry",
"fld", "fld", "flds", "flds", "flt", "flt", "flts", "flts", "frd",
"frd", "frds", "frst", "frst", "frst", "frg", "frg", "frg", "frgs",
"frk", "frk", "frks", "frks", "ft", "ft", "ft", "fwy", "fwy",
"fwy", "fwy", "fwy", "gdn", "gdn", "gdn", "gdn", "gdns", "gdns",
"gdns", "gtwy", "gtwy", "gtwy", "gtwy", "gtwy", "gln", "gln",
"glns", "grn", "grn", "grns", "grv", "grv", "grv", "grvs", "hbr",
"hbr", "hbr", "hbr", "hbr", "hbrs", "hvn", "hvn", "hts", "hts",
"hwy", "hwy", "hwy", "hwy", "hwy", "hwy", "hl", "hl", "hls",
"hls", "holw", "holw", "holw", "holw", "holw", "inlt", "is",
"is", "is", "iss", "iss", "iss", "isle", "isle", "jct", "jct",
"jct", "jct", "jct", "jct", "jcts", "jcts", "jcts", "ky", "ky",
"kys", "kys", "knl", "knl", "knl", "knls", "knls", "lk", "lk",
"lks", "lks", "land", "lndg", "lndg", "lndg", "ln", "ln", "lgt",
"lgt", "lgts", "lf", "lf", "lck", "lck", "lcks", "lcks", "ldg",
"ldg", "ldg", "ldg", "loop", "loop", "mall", "mnr", "mnr", "mnrs",
"mnrs", "mdw", "mdws", "mdws", "mdws", "mdws", "mews", "ml",
"mls", "msn", "msn", "mtwy", "mt", "mt", "mt", "mtn", "mtn",
"mtn", "mtn", "mtn", "mtn", "mtns", "mtns", "nck", "nck", "orch",
"orch", "orch", "oval", "oval", "opas", "park", "park", "park",
"pkwy", "pkwy", "pkwy", "pkwy", "pkwy", "pkwy", "pkwy", "pass",
"psge", "path", "path", "pike", "pike", "pne", "pnes", "pnes",
"pl", "pln", "pln", "plns", "plns", "plz", "plz", "plz", "pt",
"pt", "pts", "pts", "prt", "prt", "prts", "prts", "pr", "pr",
"pr", "radl", "radl", "radl", "radl", "ramp", "rnch", "rnch",
"rnch", "rnch", "rpd", "rpd", "rpds", "rpds", "rst", "rst", "rdg",
"rdg", "rdg", "rdgs", "rdgs", "riv", "riv", "riv", "riv", "rd",
"rd", "rds", "rds", "rte", "row", "rue", "run", "shl", "shl",
"shls", "shls", "shr", "shr", "shr", "shrs", "shrs", "shrs",
"skwy", "spg", "spg", "spg", "spg", "spgs", "spgs", "spgs", "spgs",
"spur", "spur", "sq", "sq", "sq", "sq", "sq", "sqs", "sqs", "sta",
"sta", "sta", "sta", "stra", "stra", "stra", "stra", "stra",
"stra", "stra", "strm", "strm", "strm", "st", "st", "st", "st",
"sts", "smt", "ste", "smt", "smt", "smt", "ter", "ter", "ter",
"trwy", "trce", "trce", "trce", "trak", "trak", "trak", "trak",
"trak", "trfy", "trl", "trl", "trl", "trl", "trlr", "trlr", "trlr",
"tunl", "tunl", "tunl", "tunl", "tunl", "tunl", "tpke", "tpke",
"tpke", "upas", "un", "un", "uns", "vly", "vly", "vly", "vly",
"vlys", "vlys", "via", "via", "via", "via", "vw", "vw", "vws",
"vws", "vlg", "vlg", "vlg", "vlg", "vlg", "vlg", "vlgs", "vlgs",
"vl", "vl", "vis", "vis", "vis", "vis", "vis", "walk", "walk",
"wall", "way", "way", "ways", "wl", "wls", "wls"))
randomAddresses = function(n){
tibble(
addresses =
replicate(
n,
sample(c(sample(10:10000, 1, replace = TRUE) %>% paste0,
sample(c("harper", "davis", "van cortland", "marry", "von brown"), 1),
sample(USPS$common_abbrev, 1)), 3) %>% paste(collapse = " ")
)
)
}
ht.create <- function() new.env()
ht.insert <- function(ht, key, value) ht[[key]] <- value
ht.insert <- Vectorize(ht.insert, c("key", "value"))
ht.lookup <- function(ht, key) ht[[key]]
ht.lookup <- Vectorize(ht.lookup, "key")
addHashTable2 = function(.x, .y, key, value){
key = enquo(key)
value = enquo(value)
if (!all(c(as_label(key), as_label(value)) %in% names(.y))) {
stop(paste0("`.y` must contain `", as_label(key),
"` and `", as_label(value), "` columns"))
}
if((.y %>% distinct(!!key, !!value) %>% nrow)!=
(.y %>% distinct(!!key) %>% nrow)){
warning(paste0(
"\nThe number of unique values of the ", as_label(key),
" variable is different\n",
" from the number of unique values of the ",
as_label(key), " and ", as_label(value)," pairs!\n",
"The dictionary will only return the last values for a given key!"))
}
ht = ht.create()
ht %>% ht.insert(.y %>% distinct(!!key, !!value) %>% pull(!!key),
.y %>% distinct(!!key, !!value) %>% pull(!!value))
attr(.x, "hashTab") = ht
.x
}
replaceString = function(.data, value){
value = enquo(value)
#Test whether the value variable is in .data
if(!(as_label(value) %in% names(.data))){
stop(paste("The", as_label(value),
"variable does not exist in the .data table!"))
}
#Dictionary attribute presence test
if(!("hashTab" %in% names(attributes(.data)))) {
stop(paste0(
"\nThere is no dictionary attribute in the .data table!\n",
"Use addHashTable or addHashTable2 to add a dictionary attribute."))
}
ht = attr(.data, "hashTab")
txtRep = function(txt){
txt = str_split(txt, " ")[[1]]
httxt = ht.lookup(ht, txt)
txt[httxt!="NULL"] = httxt[httxt!="NULL"]
paste(txt, collapse = " ")
}
.data %>% rowwise(!!value) %>%
mutate(:= txtRep(value))
}replaceString函数已经被修改,以替换缩写,而不管它们在句子中的位置。看看如何使用它。
set.seed(1111)
df=randomAddresses(10)
df输出
# A tibble: 10 x 1
addresses
<chr>
1 marry wall 8995
2 cen 9192 marry
3 bayoo 3745 davis
4 marry hollows 4104
5 grdn 7162 marry
6 lck harper 1211
7 9405 van cortland knol
8 7984 von brown viadct
9 4365 von brown rue
10 6399 von brown mssn 现在我们将修改这个tibble。
df %>% addHashTable2(USPS, common_abbrev, usps_abbrev) %>%
replaceString(addresses)输出
# A tibble: 10 x 1
# Rowwise: addresses
addresses
<chr>
1 marry wall 8995
2 ctr 9192 marry
3 byu 3745 davis
4 marry holw 4104
5 gdn 7162 marry
6 lck harper 1211
7 9405 van cortland knl
8 7984 von brown via
9 4365 von brown rue
10 6399 von brown msn 祝你好运和大数据的快速突变!
https://stackoverflow.com/questions/69467651
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号