
用Pandas重采样函数实现多张纸片的OHLC
用Pandas重采样函数实现多张纸片的OHLC
提问于 2021-10-08 12:19:29
我有两个纸片的刻度数据(scrip_names是abc和xyz)。由于滴答的数据是在一个“第二个”水平,我想把这个转换为OHLC (开放,高,低,关闭)在1分钟的水平。
当蜱的数据只包含1张纸片时,我使用下面的代码(单个Scrip.py的OHLC )在1分钟的水平上得到OHLC。这段代码提供了所需的结果。
代码:
import os
import time
import datetime
import pandas as pd
import numpy as np
ticks=pd.read_csv(r'C:\Users\tech\Downloads\ticks.csv')
ticks=pd.DataFrame(ticks)
#ticks=ticks.where(ticks['scrip_name']=="abc")
#ticks=ticks.where(ticks['scrip_name']=="xyz")
ticks['timestamp'] = pd.to_datetime(ticks['timestamp'])
ticks=ticks.set_index(['timestamp'])
ohlc_prep=ticks.loc[:,['last_price']]
ohlc_1_min=ohlc_prep['last_price'].resample('1min').ohlc().dropna()
ohlc_1_min.to_csv(r'C:\Users\tech\Downloads\ohlc_1_min.csv')结果:
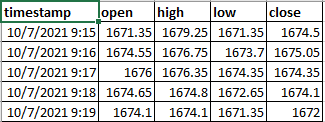
但是,当蜱的数据包含超过1张纸片时,这段代码就不能工作了。应该对代码进行哪些修改才能得到以下结果(文件名: expected_result.csv),这是由scrip_name分组的。
预期结果
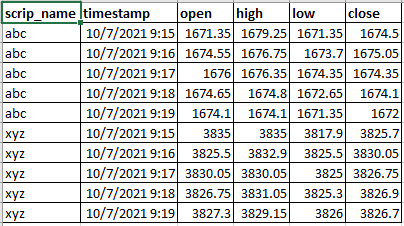
下面是到ticks数据的链接,单纸片的python代码,单纸片的结果,以及多个scrip的预期结果:https://drive.google.com/file/d/1Y3jngm94hqAW_IJm-FAsl3SArVhnjGJE/view?usp=sharing
任何帮助都是非常感谢的。
谢谢。
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-10-08 12:23:48
我想你需要groupby就像:
ticks['timestamp'] = pd.to_datetime(ticks['timestamp'])
ticks=ticks.set_index(['timestamp'])
ohlc_1_min=ticks.groupby('scrip_name')['last_price'].resample('1min').ohlc().dropna()或者:
ohlc_1_min=(ticks.groupby(['scrip_name',
pd.Grouper(freq='1min', level='timestamp')])['last_price']
.ohlc()
.dropna())页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69495734
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号