
如何确定从txt文件中读取的项的频率,并打印项目的名称以及项目出现的次数?
我正在编写一个小程序,它从一个文本文件中读取,其中包含了我们在杂货店购买的许多物品。这个程序是一个更大的应用程序的一部分,其中我正在集成Python和C++,但是为了简单起见,我隔离了这个应用程序的这一部分,因为它似乎就是问题所在。
问题是文本文件(菠菜)中的第一项在txt文件中存在5次,但是程序会打印一些垃圾数据,然后是菠菜,然后作为表示该文件中存在多个单词菠菜的次数的数字1。但是应该是5。在项目列表中,您还可以看到单词菠菜再次被打印出来,但是这次用数字4表示它在txt文件中存在的次数。但是菠菜这个词应该只打印一次,数字5表示它在txt文件中存在的时间。例如,Spinash-5.查看下面的图像.
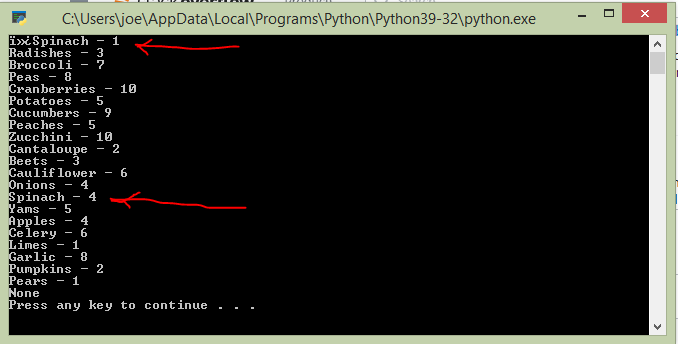
,
我不确定这个问题是否在freq = {}字典中。拜托,有人能帮我找出是什么引起的问题吗?请具体一点,因为我刚刚在学习蟒蛇。请查看.py文件的下面代码,并查看.txt文件中的项目列表。
提前谢谢你的帮助。
App.py
def wordFrequency(item): # This function gets called printed out by WordFrequency , it takes one argument which passes from cpp
count = 0 # this variable is use to count the frequency of the list iitem
with open('items.txt')as myfile: # opening file
lines = myfile.readlines() #reading all the lines of the file
for line in lines:
if(line.strip("\n") == item): # removing the \n from the last
count + 1
myfile.close()
return count
# Display only
def displayWordFrequency():
with open('items.txt')as myfile: # opening file
lines = myfile.readlines()
freq ={} # using dictionary to store the value of the list
for line in lines:
if(line.strip("\n") in freq): # put the condition if the value is present aleady then it will increment it otherwise it will put one for it
freq[line.strip("\n")] += 1 #strip to remove \n which passes as an argument
else:
freq[line.strip("\n")] = 1
for key , value in freq.items(): # loops through dictionary and prints the values
print(f"{key} - {value}") # Key is the string and the value is the integer
myfile.close()
print(displayWordFrequency())items.txt
Spinach
Radishes
Broccoli
Peas
Cranberries
Broccoli
Potatoes
Cucumbers
Radishes
Cranberries
Peaches
Zucchini
Potatoes
Cranberries
Cantaloupe
Beets
Cauliflower
Cranberries
Peas
Zucchini
Peas
Onions
Potatoes
Cauliflower
Spinach
Radishes
Onions
Zucchini
Cranberries
Peaches
Yams
Zucchini
Apples
Cucumbers
Broccoli
Cranberries
Beets
Peas
Cauliflower
Potatoes
Cauliflower
Celery
Cranberries
Limes
Cranberries
Broccoli
Spinach
Broccoli
Garlic
Cauliflower
Pumpkins
Celery
Peas
Potatoes
Yams
Zucchini
Cranberries
Cantaloupe
Zucchini
Pumpkins
Cauliflower
Yams
Pears
Peaches
Apples
Zucchini
Cranberries
Zucchini
Garlic
Broccoli
Garlic
Onions
Spinach
Cucumbers
Cucumbers
Garlic
Spinach
Peaches
Cucumbers
Broccoli
Zucchini
Peas
Celery
Cucumbers
Celery
Yams
Garlic
Cucumbers
Peas
Beets
Yams
Peas
Apples
Peaches
Garlic
Celery
Garlic
Cucumbers
Garlic
Apples
Celery
Zucchini
Cucumbers
Onions回答 2
Stack Overflow用户
发布于 2021-10-23 23:50:30
您可以通过在数据的set上循环以删除重复项来实现这一点。要遵守订单,你必须回顾原来的清单
# see question for full list
s = """Spinach
Radishes
Broccoli
Peas
Cranberries
Broccoli
Potatoes
Cucumbers
...
Celery
Zucchini
Cucumbers
Onions"""
s = s.split('\n') # get the data as list
s_dict = {k: s.count(k) for k in set(s)}
original_indices = sorted(map(s.index, set(s)))
print('\n'.join(' - '.join((s[i], str(s_dict[s[i]]))) for i in original_indices))编辑
如果您正在使用字典,并且顺序很重要,最好使用标准库集合中的实现。
import collections
s = # defined as above
d = collections.OrderedDict()
for i in s:
if i in d:
d[i] += 1
else:
d[i] = 1
for k, v in d.items():
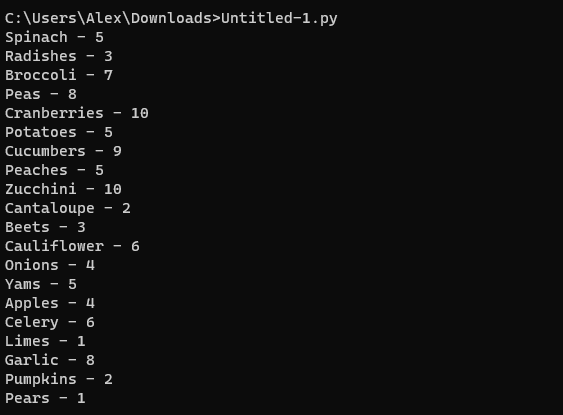
print(k, '-', v)输出
Spinach - 5
Radishes - 3
Broccoli - 7
Peas - 8
Cranberries - 10
Potatoes - 5
Cucumbers - 9
Peaches - 5
Zucchini - 10
Cantaloupe - 2
Beets - 3
Cauliflower - 6
Onions - 4
Yams - 5
Apples - 4
Celery - 6
Limes - 1
Garlic - 8
Pumpkins - 2
Pears - 1Stack Overflow用户
发布于 2021-10-23 16:56:01
您只需检查条目是否在dic中,如果是add 1,如果不是,则向dic中添加值为1的新项。
def Calculate():
dic = {}
with open("item.txt", "r") as f:
lines = f.readlines()
for l in lines:
try: # may cause KeyError
dic[l.replace("\n", "")] +=1 #If present in dic
except:
dic[l.replace("\n", "")] = 1 #If not present
return dic
result = Calculate()
for k,v in result.items():
print(f"{k} - {v}")
https://stackoverflow.com/questions/69690021
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号