
计算R中多列的毒性特征变量,并在数据集中维护该信息
我有一个包含药物毒性数据的数据集。行是观察(病人)和列包含一种类型的毒性(这些是多列,例如。tox1,tox2,tox3.),发生的时间和严重程度。
例如:
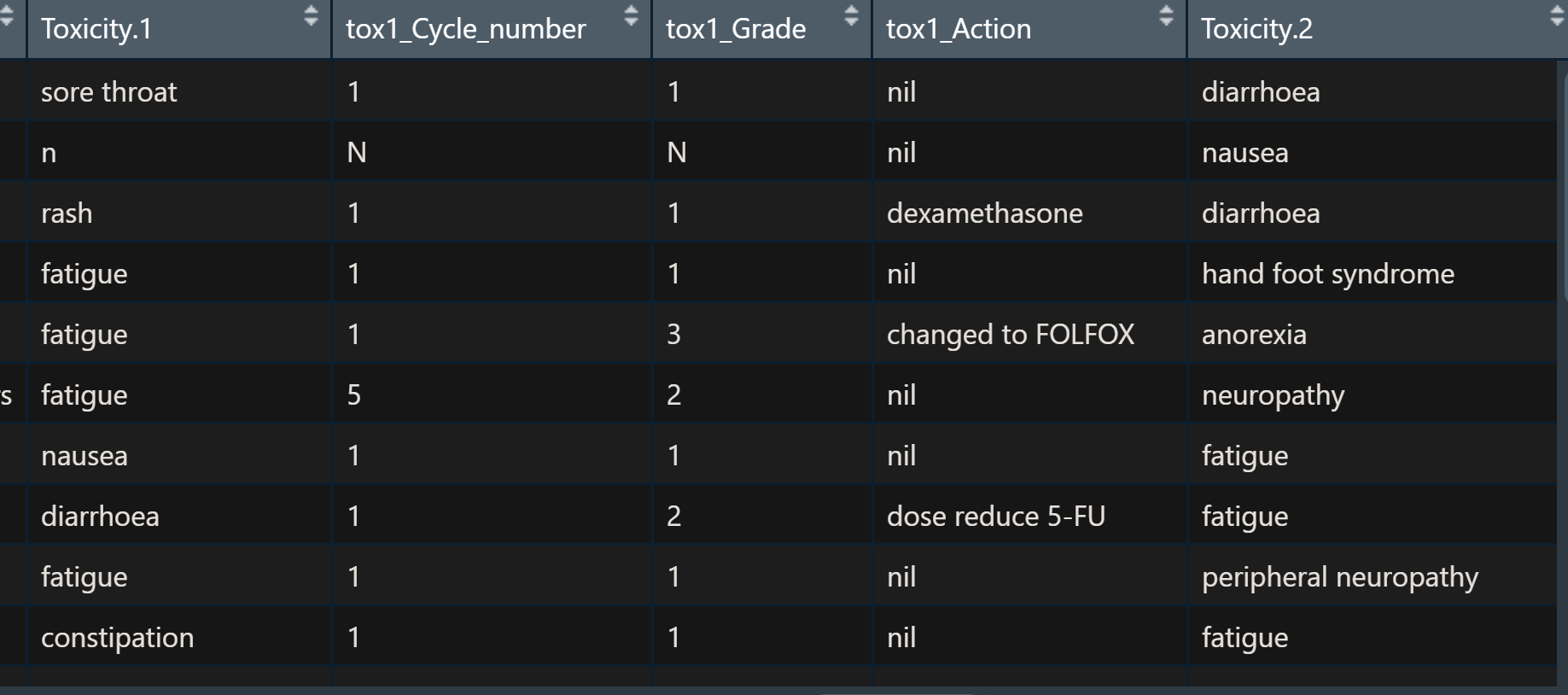
侧重于假设疲劳行4和5,6,9在Tox 1行中有疲劳,7,8,10有疲劳列在Tox 2中。
我认为收集这些毒物数据的最好方法是为每种毒性创建一个列。
因此,我想创建一个具有“是”和“否”响应的疲劳列,我使用了以下方法:
Dataset$Fatigue.any.grade <- ifelse(Dataset$Toxicity.1 == "Fatigue", "Yes","No")对于1列来说很好。
但我不能做多列,
Dataset$Fatigue.any.grade <- ifelse(Dataset$Toxicity.1|Dataset$Toxicity.2|Dataset$Toxicity.3|Dataset$Toxicity.4|Datase$Toxicity.4 == "Fatigue", "Yes","No")我是否可以从这5个毒性柱中创建一个疲劳毒性柱?
例如,我的目标是:
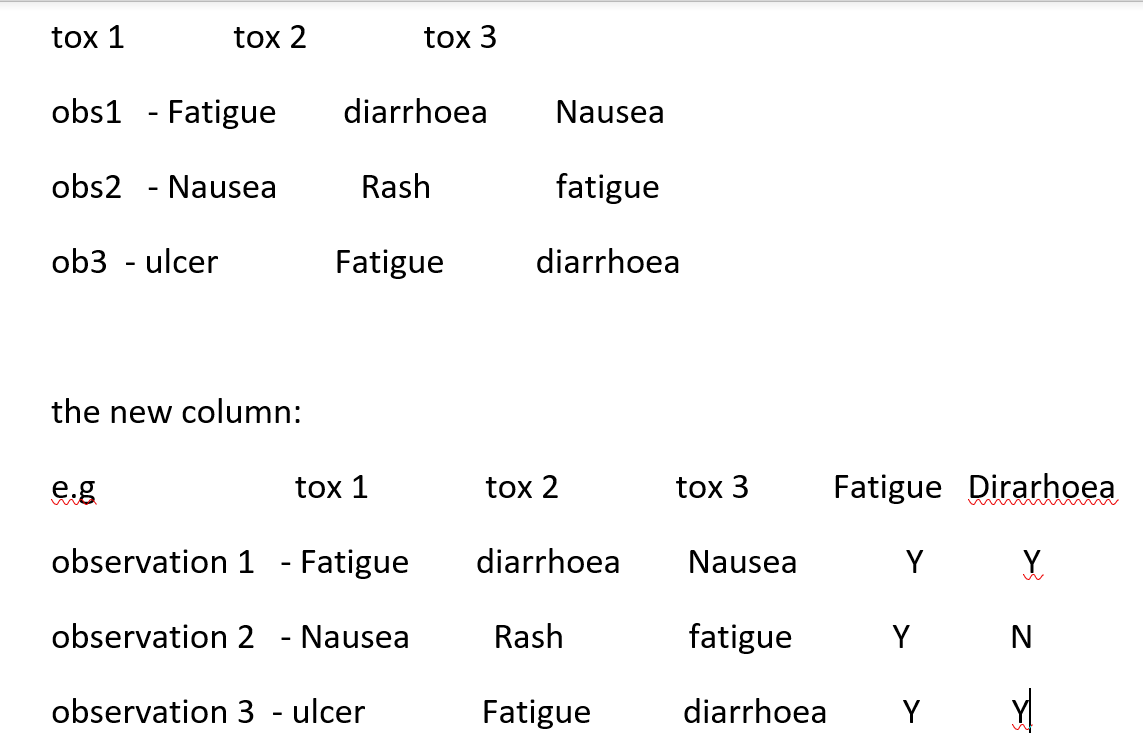
回答 2
Stack Overflow用户
发布于 2021-10-26 15:01:01
你哪里出错了
不出所料,您的条件在一列上的工作方式与预期的一样:
Dataset$Toxicity.1 == "Fatigue"毕竟,您只需将(使用==) character列Dataset$Toxicity.1与character值"Fatigue"进行比较。因此,Dataset$Toxicity.1 == "Fatigue"操作将生成一个logical列,其中TRUE Dataset$Toxicity.1包含"Fatigue",而FALSE则不包含"Fatigue"。
但是,在尝试使用多列时,确实误解了 |的用法。逻辑|运算符工作在TRUEs和FALSEs的logical列(或更一般的"vectors")上,并使用OR来比较它们的相应值:
c(TRUE, FALSE, TRUE, FALSE) | c(TRUE, TRUE, FALSE, FALSE)
# [1] TRUE TRUE TRUE FALSE所以如果你期待你的病情
Dataset$Toxicity.1 | Dataset$Toxicity.2 | Dataset$Toxicity.3 | Dataset$Toxicity.4 | Dataset$Toxicity.5 == "Fatigue"扩展成这样的东西
(Dataset$Toxicity.1 == "Fatigue") | (Dataset$Toxicity.2 == "Fatigue") | (Dataset$Toxicity.3 == "Fatigue") | (Dataset$Toxicity.4 == "Fatigue") | (Dataset$Toxicity.5 == "Fatigue"),你错了,。根据运算顺序,首先对|s的块进行计算。
# |------------------------------------------------------------------------------------------------------|
(Dataset$Toxicity.1 | Dataset$Toxicity.2 | Dataset$Toxicity.3 | Dataset$Toxicity.4 | Dataset$Toxicity.5) == "Fatigue"并将结果与字符串"Fatigue"进行比较。
问题是,您的Dataset$Toxicity.* character 列是character而不是 logical**,,所以使用** |**.将它们相互比较是没有意义的。即使您使用_could_,,结果也是一个逻辑向量,可以将_而不是_与字符串** "Fatigue"**.**进行相等性比较。
如何修复它
如果要正确地执行实现,需要写出每个character比较,然后在logical结果上使用|:
Dataset$Fatigue.any.grade <- ifelse(
Dataset$Toxicity.1 == "Fatigue" | Dataset$Toxicity.2 == "Fatigue" | Dataset$Toxicity.3 == "Fatigue" | Dataset$Toxicity.4 == "Fatigue" | Dataset$Toxicity.5 == "Fatigue",
"Yes","No"
)如何做得更好
德普利包提供了mutate()来创建(或转换)列,across()可以一次操作多个列。
您可以使用一个临时的across() ~. == "Fatigue"来操作所有的Toxicity.*列,它将这些列中的每一个(.)与字符串"Fatigue"进行比较;然后您可以使用Reduce()来使用|合并这些(logical)结果。
library(dplyr)
Dataset <- Dataset %>%
mutate(
# Create a new column: 'Fatigue.any.grade'.
Fatigue.any.grade = across(
# Look across all the columns whose names start with "Toxicity."...
starts_with("Toxicity."),
# ...and compare each column against the string "Fatigue".
~. == "Fatigue"
) %>%
# Consolidate those logical results using OR (|), to show (TRUE) where ANY of
# those columns contained "Fatigue".
Reduce(f = `|`) %>%
# Change the TRUEs and FALSEs into "Yes"s and "No"s.
if_else("Yes", "No")
)备注
我已经写了很多注释,但是您可以很容易地缩短这个mutate()
mutate(
Fatigue.any.grade = across(starts_with("Toxicity."), ~. == "Fatigue") %>% Reduce(f = `|`) %>% if_else("Yes", "No")
)自然,你可以做同样的腹泻和疲劳。只需复制上面的mutate(),但是使用列名Diarrhoea.any.grade和公式~. == "diarhhoea"。
您还可以通过修改类似于:的公式使比较不区分大小写。因此,除了检测"FATIGUE"、"fatigue"和"fATigUe"之外,还可以检测"Fatigue"。
更新
由请求
...say,现在,我想看看被分类为2级或更高的毒性,即Fatige 2级,占柱数。最好的编码方法是什么?
下面是一个更高级的解决方案,它以年级(tox*_Grade)为条件:
# Define a grade range: 2 and higher.
min_grade <- 2
max_grade <- Inf
Dataset <- Dataset %>%
mutate(
Fatigue_Grade_n = (
# Count fatigues...
across(starts_with("Toxicity."), ~. == "Fatigue") &
# ...whose grades are in a certain range.
across(matches("tox\\d+_Grade"), ~ . >= min_grade & . <= max_grade)
# ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
# CUSTOM FORMULA: Just use '.'
) %>%
# Consolidate those logical results, to show (TRUE) where 'any()' of those columns
# contained "Fatigue".
apply(MARGIN = 1, FUN = any)
# ...
)备注
您可以使tox*_Grade 公式任意复杂,以满足您的需要。请记住以下几点:
- 在公式前面加上
~符号。 - 将
tox*_Grade列表示为.符号。 - 将
.列视为它的向量。所以使用矢量化操作(比如&而不是&&)。
Stack Overflow用户
发布于 2021-10-26 13:56:45
melt和dcast应该做您想做的事情:
library(data.table)
dt <- setnames(cbind(data.table(obs = sample(10, 10)), as.data.table(t(replicate(10, sample(c("fatigue", "diarrhoea", "nausia", "rash", "ulcer"), 3))))), new = c("obs", "tox1", "tox2", "tox3"))
> dt
obs tox1 tox2 tox3
1: 4 fatigue diarrhoea rash
2: 5 fatigue rash ulcer
3: 10 rash ulcer nausia
4: 9 rash nausia ulcer
5: 8 ulcer nausia diarrhoea
6: 3 ulcer diarrhoea nausia
7: 6 nausia ulcer fatigue
8: 2 nausia ulcer fatigue
9: 7 diarrhoea fatigue ulcer
10: 1 diarrhoea rash nausia
> cbind(setorder(dt, obs), dcast(melt(dt, id.var = "obs"), obs ~ value, value.var = "variable")[, -1])
obs tox1 tox2 tox3 diarrhoea fatigue nausia rash ulcer
1: 1 diarrhoea rash nausia tox1 <NA> tox3 tox2 <NA>
2: 2 nausia ulcer fatigue <NA> tox3 tox1 <NA> tox2
3: 3 ulcer diarrhoea nausia tox2 <NA> tox3 <NA> tox1
4: 4 fatigue diarrhoea rash tox2 tox1 <NA> tox3 <NA>
5: 5 fatigue rash ulcer <NA> tox1 <NA> tox2 tox3
6: 6 nausia ulcer fatigue <NA> tox3 tox1 <NA> tox2
7: 7 diarrhoea fatigue ulcer tox1 tox2 <NA> <NA> tox3
8: 8 ulcer nausia diarrhoea tox3 <NA> tox2 <NA> tox1
9: 9 rash nausia ulcer <NA> <NA> tox2 tox1 tox3
10: 10 rash ulcer nausia <NA> <NA> tox3 tox1 tox2NA值表示在该行中找不到毒性类型。否则,fatigue等下的值指示它来自哪个毒性柱。
更新:如果您希望在毒性类型列中只有TRUE/FALSE,那么这是一个简单的修改:
> cbind(setorder(dt, obs), dcast(melt(dt, id.var = "obs")[, present := TRUE], obs ~ value, value.var = "present")[, -1])
obs tox1 tox2 tox3 diarrhoea fatigue nausia rash ulcer
1: 1 diarrhoea rash nausia TRUE NA TRUE TRUE NA
2: 2 nausia ulcer fatigue NA TRUE TRUE NA TRUE
3: 3 ulcer diarrhoea nausia TRUE NA TRUE NA TRUE
4: 4 fatigue diarrhoea rash TRUE TRUE NA TRUE NA
5: 5 fatigue rash ulcer NA TRUE NA TRUE TRUE
6: 6 nausia ulcer fatigue NA TRUE TRUE NA TRUE
7: 7 diarrhoea fatigue ulcer TRUE TRUE NA NA TRUE
8: 8 ulcer nausia diarrhoea TRUE NA TRUE NA TRUE
9: 9 rash nausia ulcer NA NA TRUE TRUE TRUE
10: 10 rash ulcer nausia NA NA TRUE TRUE TRUEhttps://stackoverflow.com/questions/69695053
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号