
如何从需要使用scrapy-selenium单击的选项卡中爬行页
如何从需要使用scrapy-selenium单击的选项卡中爬行页
提问于 2021-10-25 21:11:41
因此,我想从这个网站,特别是从公司的详细信息部分的数据:
我得到了一个人的帮助,让它与python剧作家一起工作,但是我需要用python的scrapy-selenium来完成这个任务。
我想把答案中的代码重写成一种刮除硒的方法。
我试着这样做,就像在这个问题上建议的那样。
但运气不佳
我的守则:
资源/搜索结果_searchpage.yml:
products:
css: 'div[data-content="productItem"]'
multiple: true
type: Text
children:
link:
css: a.elements-title-normal
type: Linkcrawler.py:
import scrapy
import csv
from scrapy_selenium import SeleniumRequest
import os
from selectorlib import Extractor
from scrapy import Selector
class Spider(scrapy.Spider):
name = 'alibaba_crawler'
allowed_domains = ['alibaba.com']
start_urls = ['http://alibaba.com/']
link_extractor = Extractor.from_yaml_file(os.path.join(os.path.dirname(__file__), "../resources/search_results_searchpage.yml"))
def start_requests(self):
search_text="Headphones"
url="https://www.alibaba.com/trade/search?fsb=y&IndexArea=product_en&CatId=&SearchText={0}&viewtype=G".format(search_text)
yield SeleniumRequest(url=url, callback = self.parse, meta = {"search_text": search_text})
def parse(self, response):
data = self.link_extractor.extract(response.text, base_url=response.url)
for product in data['products']:
parsed_url=product["link"]
yield SeleniumRequest(url=parsed_url, callback=self.crawl_mainpage)
def crawl_mainpage(self, response):
driver = response.request.meta['driver']
button = driver.find_element_by_xpath( "//span[@title='Company Profile']")
button.click()
driver.quit()
yield {
'name': response.xpath("//h1[@class='module-pdp-title']/text()").extract(),
'Year of Establishment': response.xpath("//td[contains(text(), 'Year Established')]/following-sibling::td/div/div/div/text()").extract()
}使用以下代码运行代码:
scrapy crawl alibaba_crawler -o out.csv -t csv公司名称将正确返回。成立之年仍然是空的,应该还一年。
回答 2
Stack Overflow用户
发布于 2021-10-26 08:38:30
我没有正确使用选择器。这件事现在是正确的
def crawl_mainpage(self, response):
driver = response.request.meta['driver']
driver.find_element_by_xpath( "//span[@title='Company Profile']").click()
sel = Selector(text=driver.page_source)
driver.quit()
yield {
sel.xpath("//td[contains(text(), 'Year Established')]/following-sibling::td/div/div/div/text()").extract()
}Stack Overflow用户
发布于 2021-10-26 17:51:32
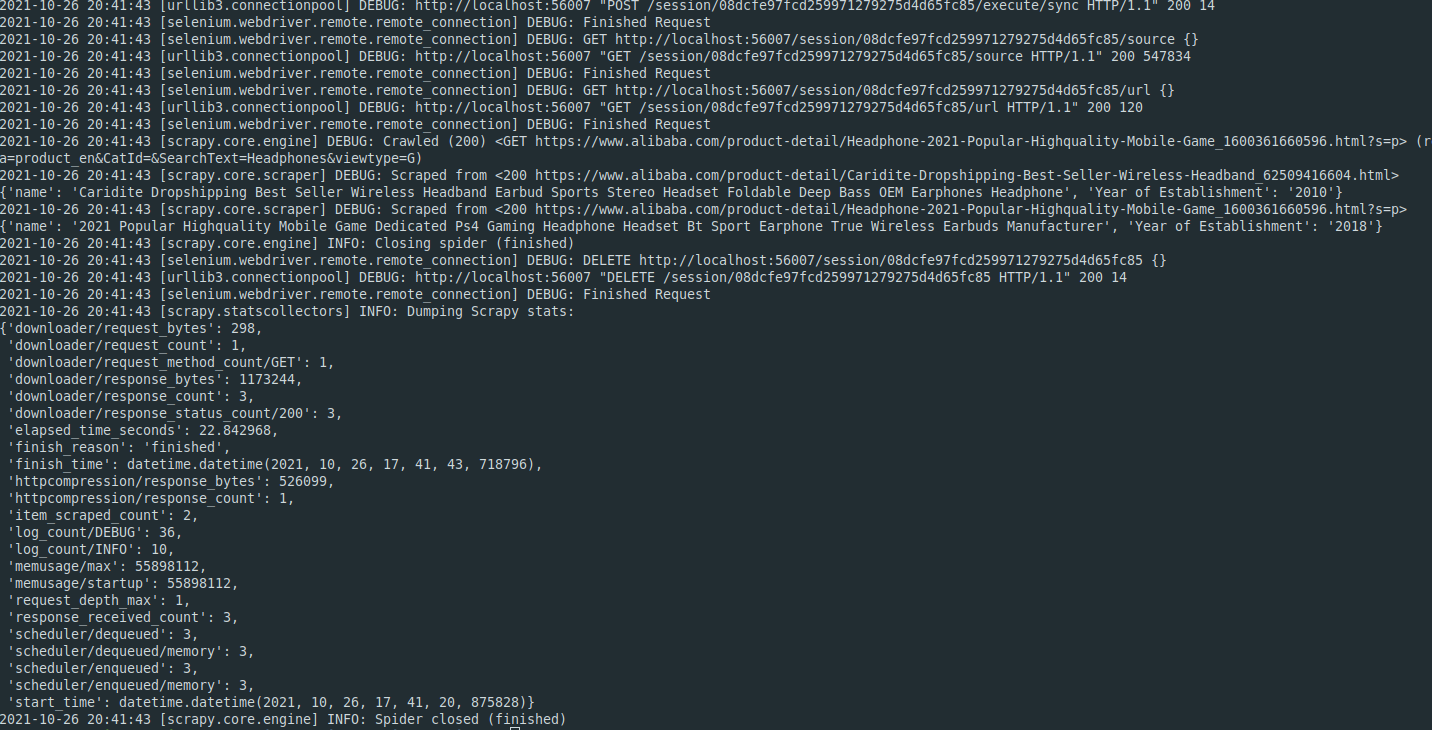
请参见下面使用刮硒库实现。Selenium对于for抓取来说非常慢。最好使用替代方法,如scrapy-splash或scrapy-playwright。只刮两页,就花了22秒钟,而剧作家只花了不到5秒。
import scrapy
from scrapy.crawler import CrawlerProcess
import os
from selectorlib import Extractor
from scrapy_selenium import SeleniumRequest
from shutil import which
class Spider(scrapy.Spider):
name = 'alibaba_crawler'
allowed_domains = ['alibaba.com']
start_urls = ['http://alibaba.com/']
link_extractor = Extractor.from_yaml_file(os.path.join(
os.path.dirname(__file__), "../resources/search_results_searchpage.yml"))
def start_requests(self):
search_text = "Headphones"
url = "https://www.alibaba.com/trade/search?fsb=y&IndexArea=product_en&CatId=&SearchText={0}&viewtype=G".format(
search_text)
yield scrapy.Request(url, callback=self.parse, meta={"search_text": search_text})
def parse(self, response):
data = self.link_extractor.extract(
response.text, base_url=response.url)
for product in data['products']:
parsed_url = product["link"]
yield SeleniumRequest(url=parsed_url, callback=self.crawl_mainpage, script='document.querySelector("span[title=\'Company Profile\']").click();')
def crawl_mainpage(self, response):
yield {
'name': response.xpath("//h1[@class='module-pdp-title']/text()").extract_first(),
'Year of Establishment': response.xpath("//td[contains(text(), 'Year Established')]/following-sibling::td/div/div/div/text()").extract_first()
}
if __name__ == "__main__":
process = CrawlerProcess(settings={'DOWNLOADER_MIDDLEWARES': {
'scrapy_selenium.SeleniumMiddleware': 800
},
'SELENIUM_DRIVER_NAME': 'chrome',
'SELENIUM_DRIVER_EXECUTABLE_PATH': which('chromedriver'),
'SELENIUM_DRIVER_ARGUMENTS': ['--headless']
})
process.crawl(Spider)
process.start()下面是一个样例爬行作业。注意,为了返回字符串而不是列表,我将您的extract()方法更改为extract_first()。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69714821
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号