
在Weka中训练多层感知器
我正在使用Weka实现分类算法。我在和多层脉冲加速器打交道。我在训练模特的时候有些怀疑。我使用了Weka中已有的玩具数据集。数据集的名称是contact-lenses.arff和weather.nominal.arff。
我正在附上一些截图。
]
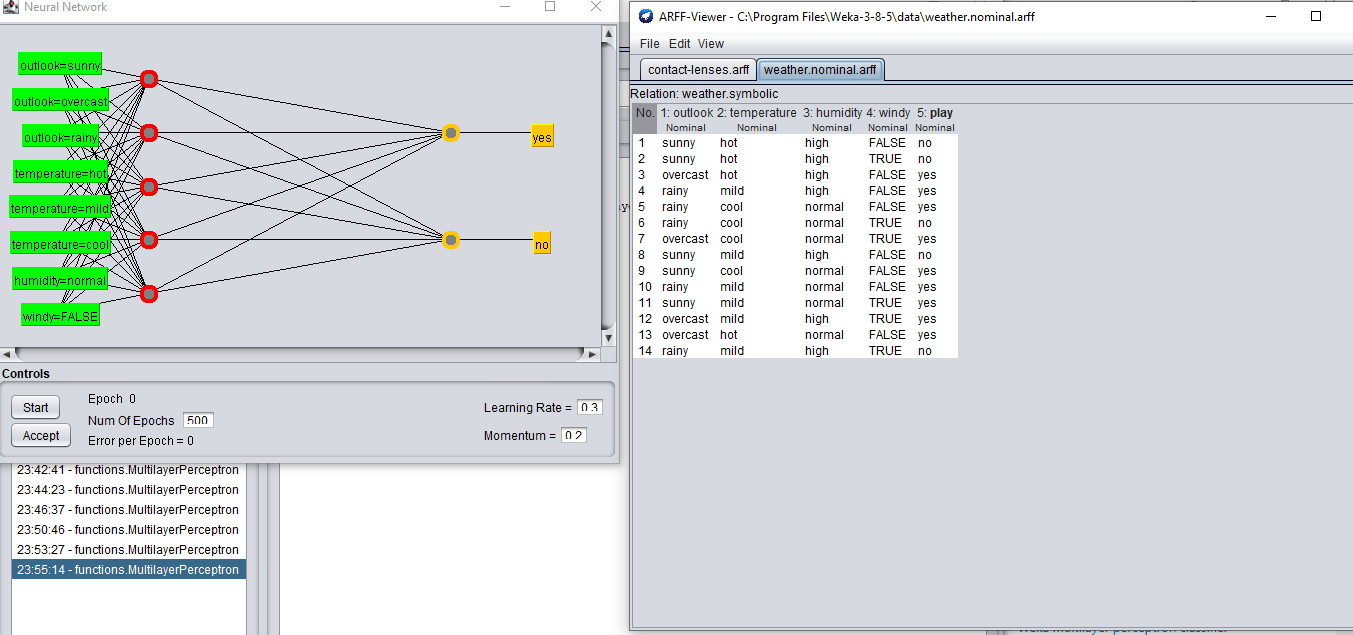
我采用了5倍交叉验证法。
根据weka中用于隐藏层的定义,There are also wildcard values: 'a' = (attribs + classes) / 2, 'i' = attribs, 'o' = classes , 't' = attribs + classes.
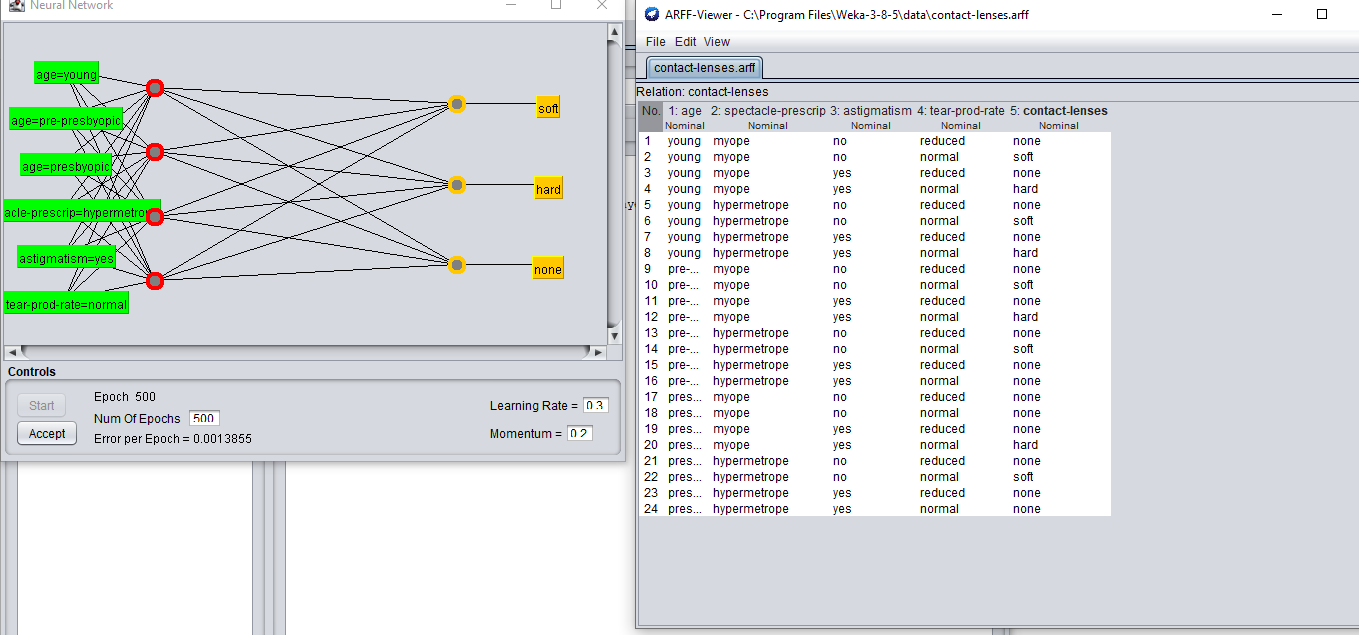
对于第一张截图,a应该是(No.)/2= (4+3)/2 = 7/2 = 3.5 =4
所以我们可以看到隐藏层中的4个节点。
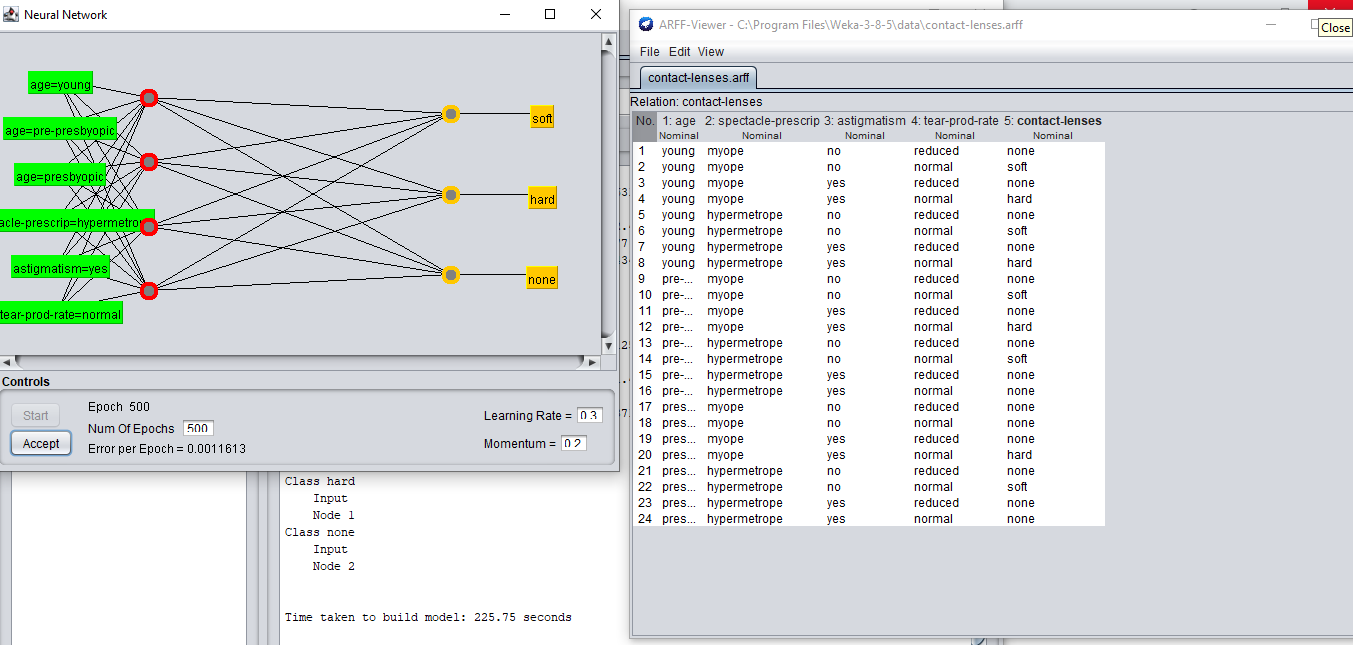
现在对于屏幕截图3,(4+2)/2 = 3。但是我们可以看到隐藏层中的5个节点。为什么实际节点和计算节点之间存在不匹配?
其次,如果我们考虑前两个截图,我们可以看到年龄在模型中使用了三个不同的值,即年轻,预早熟,早熟。然而,属性眼镜处方有两个不同的值,即myope和hypermetrope,但用于训练模型的值只有一个。其他值myope呢?对其他属性也提出了同样的疑问。
一个简短的解释是有帮助的。
回答 1
Stack Overflow用户
发布于 2021-10-31 21:13:56
默认情况下,MultilayerPerceptron将无监督NominalToBinary筛选器应用于输入数据,这将增加非二进制名义属性的属性数。这就解释了隐藏层中节点的不同数量。
另外,二进制标称属性可以仅用一个节点建模(阈值以下是一个标签,高于阈值则是另一个)-- NominalToBinary及其默认设置不会更改这些类型的属性。
https://stackoverflow.com/questions/69784144
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号