
小批量反传播澄清
小批量反传播澄清
提问于 2021-11-02 03:37:39
读了很多文章,现在我在我的人才外流结束,需要一个新的观点的概念,迷你批。我是机器学习的新手,希望能就我的过程是否正确提出任何建议。这是我的前提:
我有一个355特征和8个类输出的数据集。总共有12200个数据。这是我的神经网络的一个粗略的可视化:
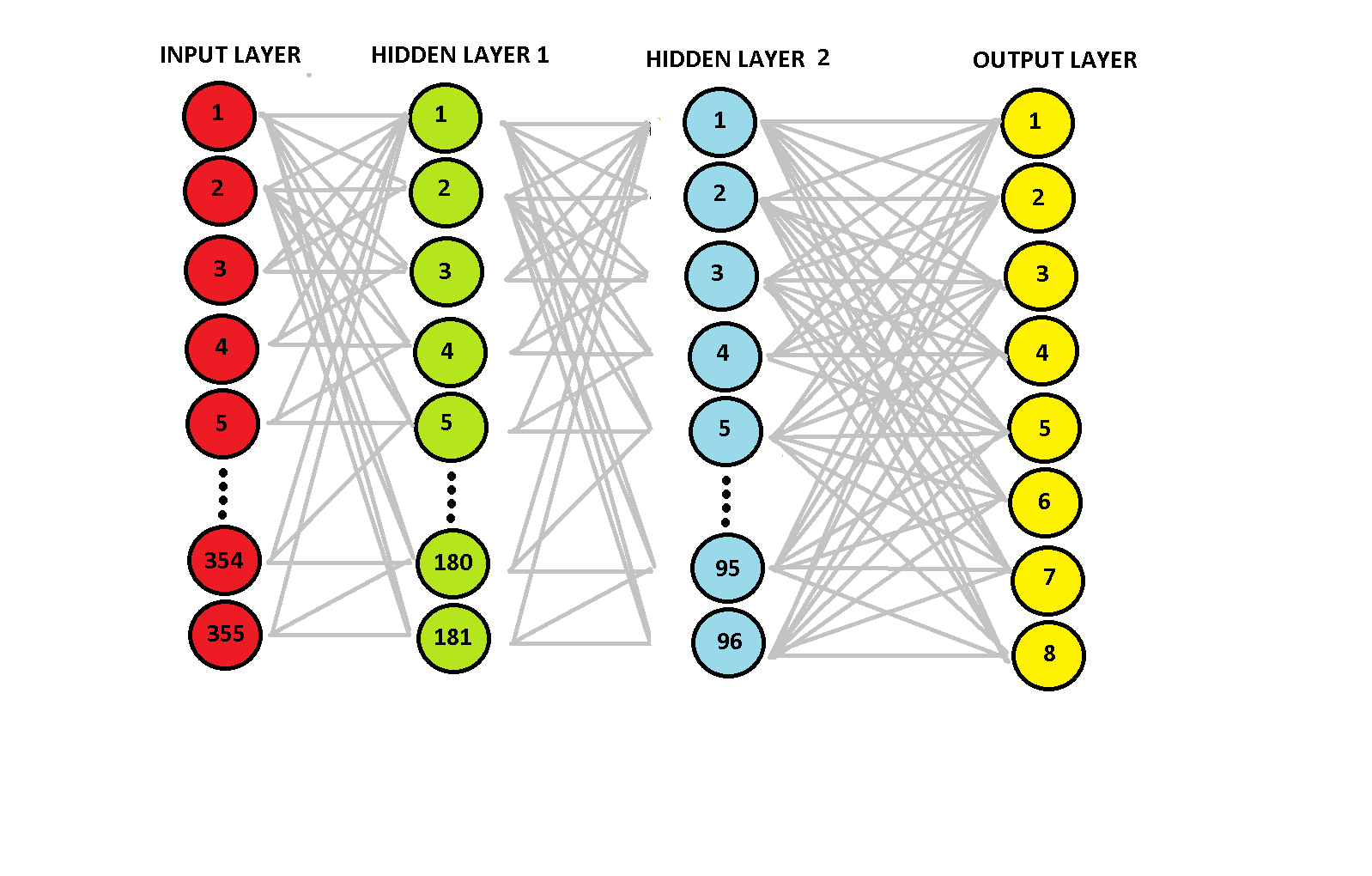
我决定将181个神经元用于隐层1,96个神经元用于隐层2,隐层采用ReLu激活,输出层采用Logistic激活。
为了完成小批处理,我将批次大小设置为8。因此,我总共有1525批,每批8个数据集。这是我的一步:
outputs).
- Forward
- 得到第一批数据(8组355个输入,8个传播),
- 得到误差,并计算误差平方和。对于平方和,我首先对批处理的误差进行平均,使用批处理的(1/8)*sum(error^2)
- Back传播公式SumError =
- ,得到了在返回weights.
- When后的加权值的平均值,新的权重作为下一批的权重,
- 得到下一批数据(8组355个输入,8组outputs).
- Repeat 2-7,使用新的weights.
- When all批处理完成,求出每个epoch.
- Repeat 1-9的平方和的SumError平均值,直到每一个时代的SumError都很小为止。
这是我的迷你批次的过程。这是正确的吗?我的意思是,对于权重,我是使用每一批之后计算的权重作为下一批的输入权重,还是先收集所有权重(所有批次将使用起始权重),然后将所有批次的权重平均?然后用平均权重作为下一个时代的输入?
回答 1
Stack Overflow用户
回答已采纳
发布于 2021-11-03 05:27:24
实际上,你必须定义你的时代,每个时代都应该把你所有的输入数据至少传播一次(而不仅仅是2-7次),在一个时期之后,更新一个权重,然后重复这些步骤,直到完成所有的时间。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69805144
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号