
我正在尝试使用python和漂亮的汤从一个网站获取表数据,但它返回脚本。
我正在尝试使用python和漂亮的汤从一个网站获取表数据,但它返回脚本。
提问于 2021-11-12 14:59:30
我尝试了BeautifulSoup,但它从URL中擦去了脚本。
url = 'https://ekartlogistics.com/shipmenttrack/FMPP0944216480'
from bs4 import BeautifulSoup
from urllib import request, parse
read = request.urlopen(url)
soup = BeautifulSoup(read, 'html.parser')
print(soup.prettify())它与其他HTML脚本一起返回脚本。
我正在尝试从这个URL获取这个表数据
回答 3
Stack Overflow用户
回答已采纳
发布于 2021-11-12 16:19:51
url由javascript动态加载数据。所以你不能只使用漂亮的汤来获取数据。您可以使用类似selenium之类的自动化工具。在这里,我使用selenium模拟javascript并通过使用熊猫获取表数据,如下所示:
代码:
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
driver = webdriver.Chrome('chromedriver.exe')
driver.maximize_window()
time.sleep(5)
driver.get("https://ekartlogistics.com/shipmenttrack/FMPP0944216480")
time.sleep(3)
table = driver.find_element(By.CSS_SELECTOR, 'table.table').get_attribute('outerHTML')
df = pd.read_html(table)[0]
print(df)输出:
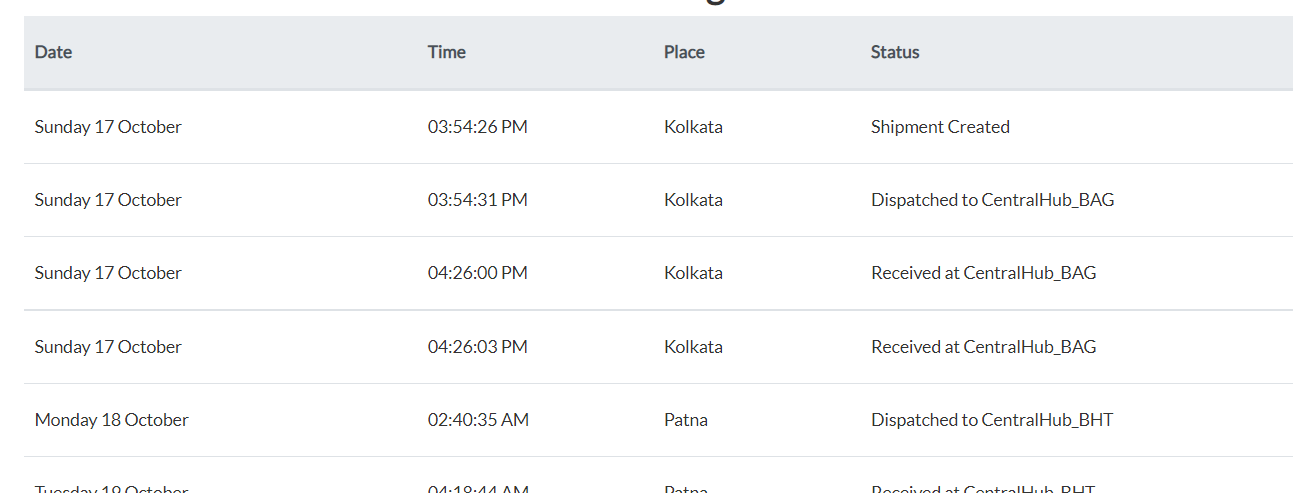
Date Time Place Status
0 Sunday 17 October 04:24:26 PM Kolkata Shipment Created
1 Sunday 17 October 04:24:31 PM Kolkata Dispatched to CentralHub_BAG
2 Sunday 17 October 04:56:00 PM Kolkata Received at CentralHub_BAG
3 Sunday 17 October 04:56:03 PM Kolkata Received at CentralHub_BAG
4 Monday 18 October 03:10:35 AM Patna Dispatched to CentralHub_BHT
5 Tuesday 19 October 04:48:44 AM Patna Received at CentralHub_BHT
6 Tuesday 19 October 05:03:44 PM Samastipur Dispatched to SatelliteHub_SAMA
7 Wednesday 20 October 02:47:44 AM Samastipur Received at SatelliteHub_SAMA
8 Thursday 21 October 09:21:52 AM Samastipur Out For Delivery
9 Friday 22 October 07:38:36 AM Samastipur DeliveredStack Overflow用户
发布于 2021-11-12 17:42:28
注意到:下面的解决方案是针对GOOGLE的。
学分:https://stackoverflow.com/users/12848411/fazlul
!pip install selenium
!apt-get update # to update ubuntu to correctly run apt install
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
import sys
sys.path.insert(0,'/usr/lib/chromium-browser/chromedriver') # ChromeDriver Path
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage') # All above commands to install Selenium on Colab
wd = webdriver.Chrome('chromedriver',chrome_options=chrome_options)
from selenium.webdriver.common.by import By
import pandas as pd
wd.get("https://ekartlogistics.com/shipmenttrack/FMPP0944216480")
table = wd.find_element(By.CSS_SELECTOR, 'table.table').get_attribute('outerHTML')
df = pd.read_html(table)[0]
print(df)输出:
Date Time Place Status
0 Sunday 17 October 04:24:26 PM Kolkata Shipment Created
1 Sunday 17 October 04:24:31 PM Kolkata Dispatched to CentralHub_BAG
2 Sunday 17 October 04:56:00 PM Kolkata Received at CentralHub_BAG
3 Sunday 17 October 04:56:03 PM Kolkata Received at CentralHub_BAG
4 Monday 18 October 03:10:35 AM Patna Dispatched to CentralHub_BHT
5 Tuesday 19 October 04:48:44 AM Patna Received at CentralHub_BHT
6 Tuesday 19 October 05:03:44 PM Samastipur Dispatched to SatelliteHub_SAMA
7 Wednesday 20 October 02:47:44 AM Samastipur Received at SatelliteHub_SAMA
8 Thursday 21 October 09:21:52 AM Samastipur Out For Delivery
9 Friday 22 October 07:38:36 AM Samastipur DeliveredStack Overflow用户
发布于 2021-11-12 15:32:02
也许尝试用Selenium加载页面无头,然后提取html?我也无法让它只处理请求。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69944896
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号