
计数唯一值,忽略拼写
计数唯一值,忽略拼写
提问于 2021-11-15 09:43:27
我有个问题。我有以下数据。我想数数所有唯一的价值。正如您所看到的,问题是,一些单词是大写或小写,但完全相同,我想数。所以在我的例子中,"Wifi“和"wifi”应该算作2,其他的也是一样的。有什么方法可以做到,例如,忽略上下大小写吗?正如你所看到的,对于wifi有不同的文章(例如"Wifi 230 mb/s"),当wifi在字符串中时,有方法计算wifi吗?
d = {'host_id': [1, 1, 1, 2, 2, 3, 3, 3, 3],
'value': ['Hot Water', 'Wifi', 'Kitchen',
'Wifi', 'Hot Water',
'Coffe Maker', 'wifi', 'hot Water', 'Wifi 230 mb/s']}
df = pd.DataFrame(data=d)
print(df)
print(len(df[df['value'].str.contains("Wifi", case=False)]))
print(df['value'].unique())
print(len(df['value'].unique()))[out]
host_id value
0 1 Hot Water
1 1 Wifi
2 1 Kitchen
3 2 Wifi
4 2 Hot Water
5 3 Coffe Maker
6 3 wifi
7 3 hot Water
8 3 Wifi 230 mb/s
4 # count wifi
['Hot Water' 'Wifi' 'Kitchen' 'Coffe Maker' 'wifi' 'hot Water'] # unique values
6 # len unique valuesout应该是什么样子:
value count
0 Hot Water 3
1 Wifi 4
2 Kitchen 1
3 Coffe Maker 1

回答 2
Stack Overflow用户
回答已采纳
发布于 2021-11-15 09:51:57
如果只存在wifi的问题--可能的另一个子字符串使用:
df['value'] = (df['value'].mask(df['value'].str.contains("Wifi", case=False), 'wifi')
.str.title())
print (df)
host_id value
0 1 Hot Water
1 1 Wifi
2 1 Kitchen
3 2 Wifi
4 2 Hot Water
5 3 Coffe Maker
6 3 Wifi
7 3 Hot Water
8 3 Wifi
print(df['value'].value_counts())
Wifi 4
Hot Water 3
Kitchen 1
Coffe Maker 1
Name: value, dtype: int64
print(df.groupby('value', sort=False).size().reset_index(name='count'))
value count
0 Hot Water 3
1 Wifi 4
2 Kitchen 1
3 Coffe Maker 1编辑:
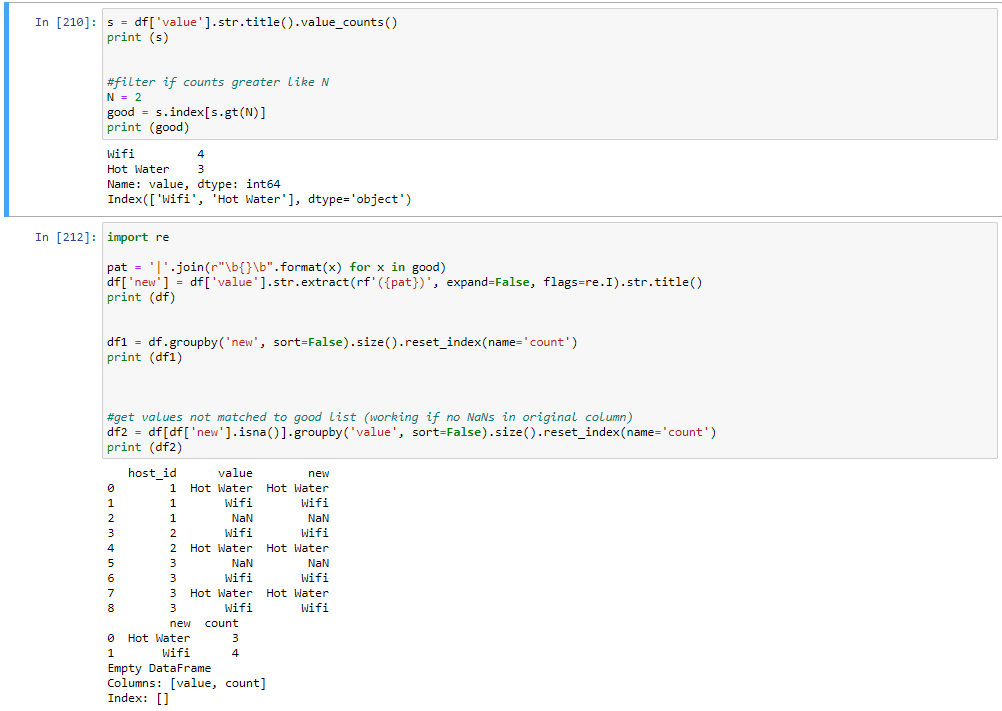
#counts original values wit hconvert to uppercase first latters
s = df['value'].str.title().value_counts()
print (s)
Wifi 3
Hot Water 3
Wifi 230 Mb/S 1
Kitchen 1
Coffe Maker 1
Name: value, dtype: int64
#filter if counts greater like N
N = 2
good = s.index[s.gt(N)]
print (good)
Index(['Wifi', 'Hot Water'], dtype='object')#extract values by list good
import re
pat = '|'.join(r"\b{}\b".format(x) for x in good)
df['new'] = df['value'].str.extract(rf'({pat})', expand=False, flags=re.I).str.title()
print (df)
host_id value new
0 1 Hot Water Hot Water
1 1 Wifi Wifi
2 1 Kitchen NaN
3 2 Wifi Wifi
4 2 Hot Water Hot Water
5 3 Coffe Maker NaN
6 3 wifi Wifi
7 3 hot Water Hot Water
8 3 Wifi 230 mb/s Wifi
df1 = df.groupby('new', sort=False).size().reset_index(name='count')
print (df1)
new count
0 Hot Water 3
1 Wifi 4
#get values not matched to good list (working if no NaNs in original column)
df2 = df[df['new'].isna()].groupby('value', sort=False).size().reset_index(name='count')
print (df2)
value count
0 Kitchen 1
1 Coffe Maker 1如果两者都需要的话:
df = pd.concat([df1, df2], ignore_index=True)Stack Overflow用户
发布于 2021-11-15 09:48:48
在比较列表中的str.lower()或str.upper()方法之前,请使用它们。这应该可以消除重复。如果您希望消除键入或其他类似的字符串,可以使用python计算距离并设置“断点”https://pypi.org/project/python-Levenshtein/。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/69972257
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号