
更改pdf文本编码
我有一个PDF文档(那是我的教科书),问题是,虽然文本是正常打印的,但它是以一些随机符号的形式复制的。我发现,这是因为文本在cp1251上被编码,但试图被解码为cp1252 (反之亦然,但复制的符号属于1252)。将文本粘贴到解码器,从1252到1251 i可以得到原始文本(与图片相关)

为了解决我的文本搜索和复制问题,我只是使用了OCR,但是也许有一种方法可以改变它在某些pdf头中的编码?此外,我确实需要复制一些学校研讨会的插图,但Inkscape和AI仍然输出1252年的图形。
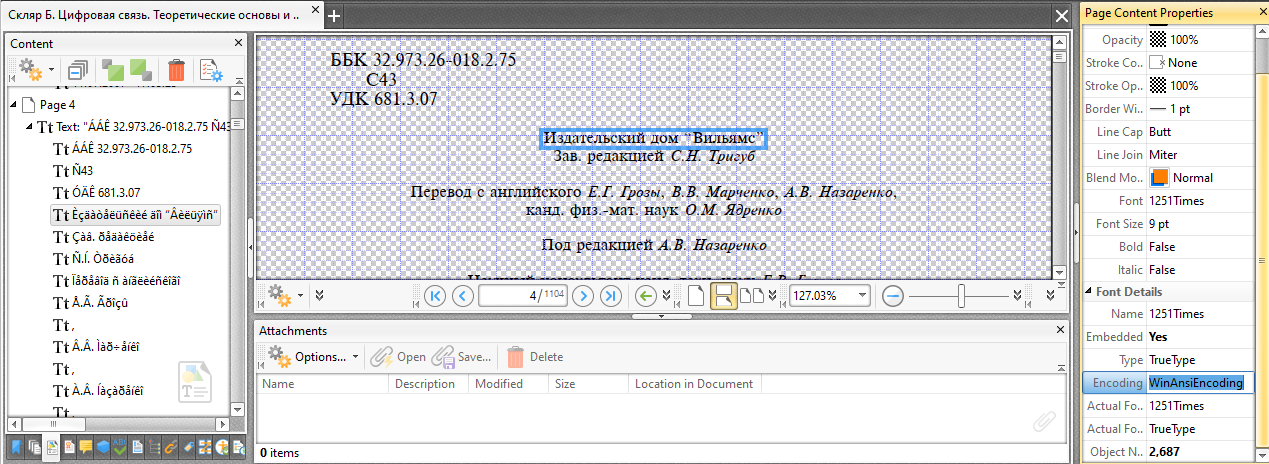
打开Acrobat中的文本,我看到他在抱怨1251字体。在Npp中,我发现了这样的一个
1146 0 obj
<<
/Ascent 756
/CapHeight 750
/Descent -195
/Flags 32
/FontBBox [-91 -224 1237 943]
/FontFamily (1251 Times)
/FontFile2 1147 0 R
/FontName /OGAHOK+1251Times
/FontStretch /Normal
/FontWeight 400
/ItalicAngle 0
/StemV 90
/Type /FontDescriptor
>>
endobj
1145 0 obj
<<
/BaseFont /OGAHOK+1251Times
/Encoding /WinAnsiEncoding
/FirstChar 32
/FontDescriptor 1146 0 R
/LastChar 255
/Subtype /TrueType
/Type /Font
/Widths [351 0 0 0 0 0 828 0 392 392 0 0 326 448 288 455 531 533 532 532 532 532 532 531 531 532 288 0 0 0 0 0 864 724 714 776 0 706 0 0 875 417 0 0 0 0 882 0 661 0 770 599 678 0 0 983 0 0 0 0 0 0 0 0 0 495 539 499 565 489 322 491 583 294 0 532 287 887 590 566 563 0 376 385 332 568 486 729 0 503 476 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 554 554 0 952 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 896 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 699 714 0 747 0 0 597 886 0 812 0 1034 875 0 877 0 776 678 729 0 0 858 0 0 0 0 0 0 759 0 0 495 559 523 434 539 489 757 449 622 622 577 550 715 636 566 622 563 499 468 503 764 500 621 553 880 880 0 760 501 517 820 546]
>>
endobj
1150 0 obj
<<
/Filter /FlateDecode
/Length1 32416
/Length 24094
>>
stream通过用1252替换1251的所有事件,我没有取得任何成就。什么是正确的方法来处理这件事?有这么一条正确的路吗?
回答 1
Stack Overflow用户
发布于 2021-12-02 15:05:23
OGAHOK+1251Times (或类似的6个随机字符和一个字体的名称标记)
经常表示源被识别为OCR (一个字符相对于另一个字符),因此每一个字母、一行字母或一页字母都可以有自己的字体,就像你发现的那样,这里的字体就像Times 1251风格的字体。
所以把名字改到1252就像说时报是Verdana,它不能改变原始数据。
我很惊讶,但为您感到高兴的是,您可以获得一些可读的1251来转换为1252,但是在可能损坏的字体度量范围内的合理转换几乎不可能一次替换一个符号到另一个符号,并保持字符串形状--参见可变的/Widths。
但是,如果没有您的基本PDF文件,这是基于经验的,而不是您的源代码失败。
更新
哇!那个文件有600个字体!有些东西处理得很差
问题似乎源于WinAnsiEncoding的使用,而不是一些UTF-8或兼容的编码方法。我想看看是否有任何修改的方法,但不确定它是否能帮助或使事情变得更糟。在这里,我可以尝试编辑设置,但在这个截图来自跟踪器PDF更改编辑器做改变没有帮助,除非文本被剪切,转换和粘贴回来。
https://stackoverflow.com/questions/70200980
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号