
当字符串被复制时,填充Pandas列中的相邻值
当字符串被复制时,填充Pandas列中的相邻值
提问于 2022-11-26 15:21:06
当名为‘关键字’的列中的值与相邻值重复时,我试图覆盖在名为'Group‘的列中命名的值。
例如,由于字符串‘商业办公清洁服务’是重复的,所以我想将相邻的列覆盖到‘商业清洁服务’。
示例数据
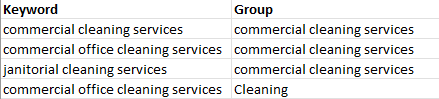
期望输出
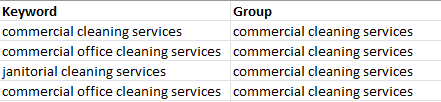
最小可重现性示例
import pandas as pd
data = [
["commercial cleaning services", "commercial cleaning services"],
["commercial office cleaning services", "commercial cleaning services"],
["janitorial cleaning services", "commercial cleaning services"],
["commercial office services", "commercial cleaning"],
]
df = pd.DataFrame(data, columns=["Keyword", "Group"])
print(df)我对熊猫很陌生,不知道从哪里开始,我已经到了一个死胡同,谷歌和搜索堆叠溢出。
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-11-26 15:26:22
IIUC,使用duplicated与mask和ffill:
#is the keyword duplicated ?
m = df['Keyword'].duplicated()
df['Group'] = df['Group'].mask(m).ffill()#产出:
print(df)
Keyword Group
0 commercial cleaning services commercial cleaning services
1 commercial office cleaning services commercial cleaning services
2 janitorial cleaning services commercial cleaning services
3 commercial office cleaning services commercial cleaning services注意:可复制的示例与输入的图像()不匹配。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74583388
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号