
将关键字转换为python dataframe列中的列表
我从另一列中提取关键字,创建一个新的列(硬技能),如下所示:(https://i.stack.imgur.com/XNOIK.png)
{kind=link}
但我想让每个关键字成为一个列表格式,在“硬着陆技能”栏。例如,对于“硬技能”列的第一行,我希望得到的结果是:
“'Python编程”,“机器学习”,“数据分析”。
而不是
Python编程,机器学习,数据分析。
这就是我如何将关键词过滤到新的“硬技能”专栏中。
#筛选并创建新专栏,介绍硬技能hard_skills =“Python编程”、“统计”、“统计假设测试”、“数据清理”、“Tensorflow”、“机器学习”、“数据分析”、“数据可视化”、“云计算”、“R编程”、“数据科学”、“计算机编程”、“深度学习”、“数据分析”、“SQL”、“回归分析”、“算法”、“JavaScript”、“Python”
def get_hard_skills(技能):return_hard_skills =“hard_skill in hard_skills: if skills.find( hard_skill ) >= 0: if return_hard_skills ==”:return_hard_skills = hard_skill hard_skills: return_hard_skills = return_hard_skills +,“+hard_skill if return_hard_skills ==”:返回(未找到)
课程名称技能‘硬技能’=“
#循环数据帧以获得硬技能
对于范围内的I(0,len(course_name_skills)-1):#数据科学课程的每一行技能= course_name_skills.loci,“技能”如果不是isNaN(技能):#如果不是空的course_name_skills.loci,“硬技能”=get_hard_skills(技能)
course_name_skills =course_name_skills.replace(未找到,np.NaN) only_hardskills =course_name_skills.dropna(子集=‘难技能’)
是否有办法更改筛选关键字数据框架的代码?还是有更有效的方法?
我试过脱衣舞(),甚至试过我的运气。
return_hard_skills = "[" + return_hard_skills + "," + hard_skill + "]"但没能通过。
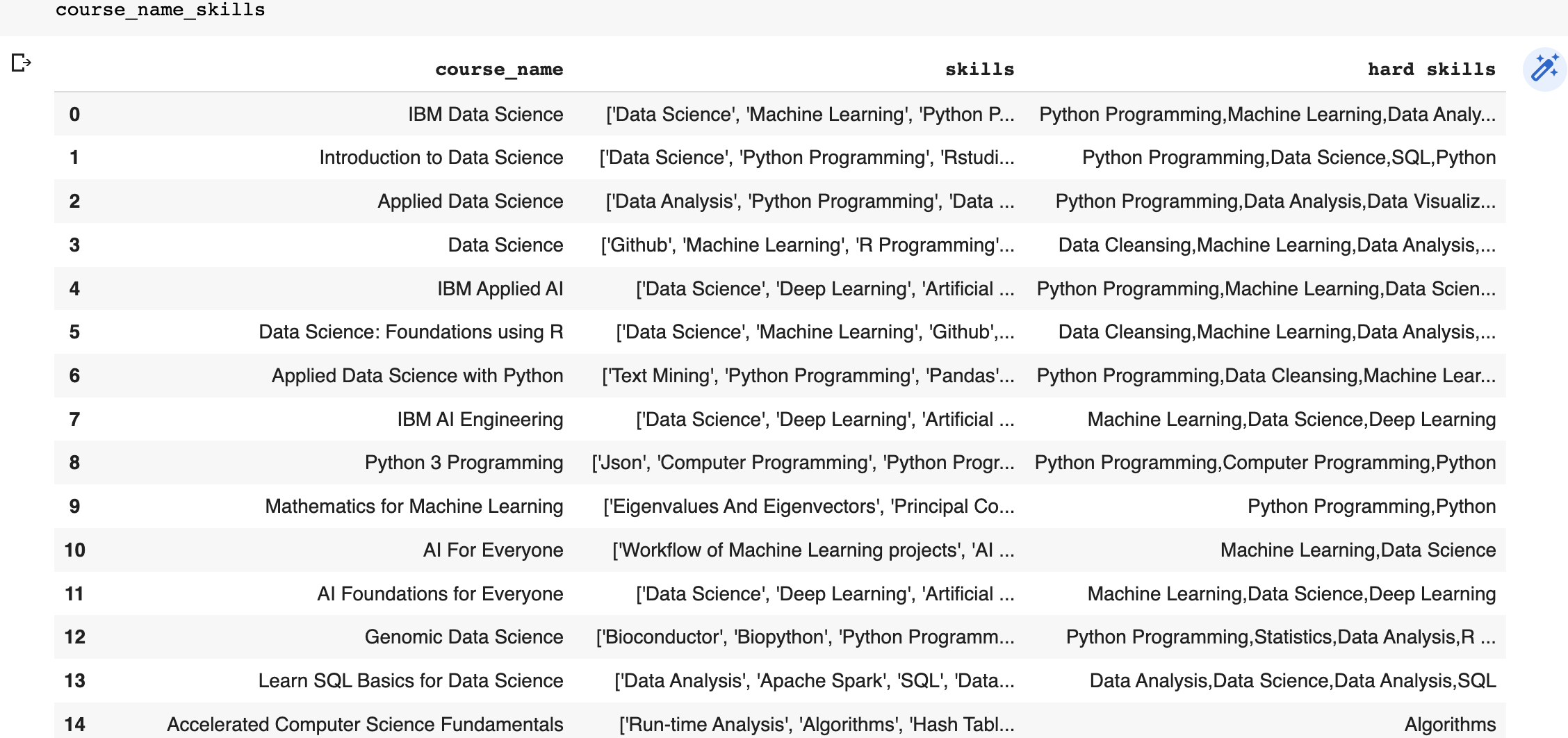
带有原始列的Dataframe
{kind=link}
回答 2
Stack Overflow用户
发布于 2022-11-25 17:41:55
IIUC,这里不需要函数和/或循环,因为您可以使用pandas.Series.str.join获得预期的列/输出:
course_name_skills["hard skills"]= course_name_skills["skills"].str.join(",")注意:上面的行假设列hard skills保存列表,否则(如果字符串)使用如下:
course_name_skills["hard skills"]= (
course_name_skills["skills"]
.str.strip("[]")
.replace({"'": "", "\s+": ""}, regex=True)
)Stack Overflow用户
发布于 2022-11-25 17:44:20
df['skills'] = df['hard skills'].str.split(',').apply(
lambda skills: [skill.strip() for skill in skills]
)如果您想要添加过滤:
skills = list(set(df['skills'].sum()))
for skill in skills:
df[skill] = df['skills'].apply(lambda x: skill in x)
df.loc[df['Data Analysis']==True]['course_name']https://stackoverflow.com/questions/74576129
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号