
基于自定义数据集的YOLOV7对象检测
基于自定义数据集的YOLOV7对象检测
提问于 2022-11-20 10:48:31
我试图使用yolov7预训练模型上的传输学习来预测自定义数据集上的边界框。
我的数据集包含34个训练场景,2个验证场景和5个测试场景。现场什么都没发生,只是摄像机在桌子/平面上的物体周围移动60-70度,鳞片/倾斜一点。所以,即使我有大约20k的训练图像(从34个场景中提取),从每个场景中,我得到的图像几乎是一样的,具有一种增强效果(缩放、旋转、遮挡和倾斜来自摄像机运动)。
这里是一个场景的例子(第一帧和最后一帧)


现在,我尝试了不同的东西。
- 基于预训练yolov7 p5模型的迁移学习
- 用预训练的yolov7 p5模型进行迁移学习(冻结提取器,50层)
- 基于预训练yolov7微模型的迁移学习
- 用预先训练过的yolov7微型模型进行转移学习(用冷冻提取器,28层)
- 全训练yolov7 p5网络
- 全训练yolov7微型网络。
其中一些工作(准确地预测包围框的准确率为100%,但召回率较低,有时使用错误的类标签),但我面临的最大问题是,对于验证,对象丢失永远不会下降(无论我尝试哪种方法)。这甚至从一开始就发生了,所以我不确定我是否过分适应。
下面的图是从传输学习的微小模型冻结骨干。
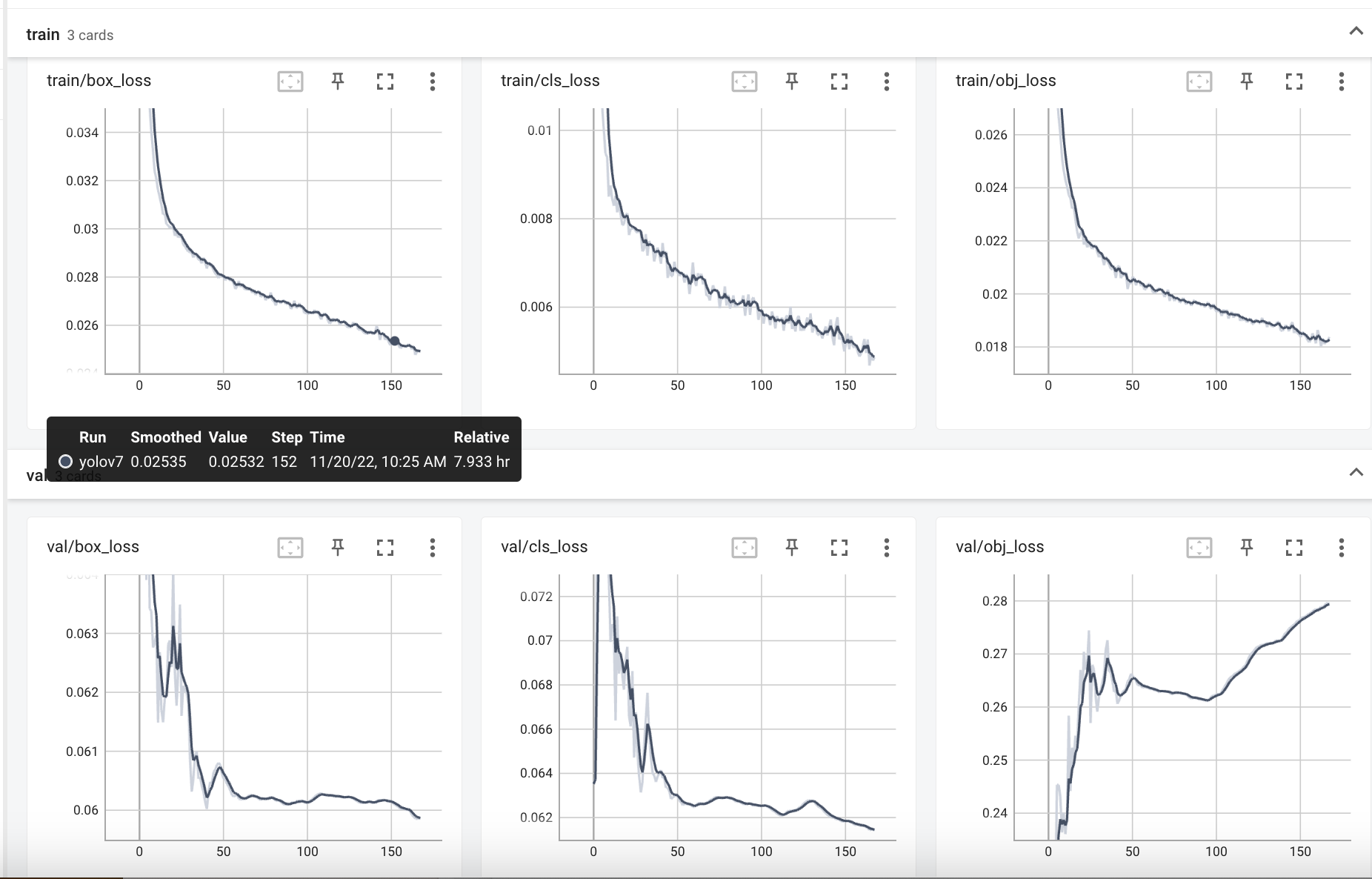
对于如何解决问题和取得更好的效果,有什么建议吗?
回答 1
Stack Overflow用户
发布于 2022-11-20 13:08:57
首先,我建议您彻底检查您的数据集。
- 检查类分布。
- How many classes do you have, and what are the counts of the objects of these classes in the training set?
- What are the counts in the validation set? Are the ratios approximately similar or different?
- Is any class lacking examples (i.e. is too few by proportion)?
- Do you have enough background samples? (Images where no desired object is present)- 检查数据集的注释。你的物品贴上正确的标签吗?如果你有时间,随机抽取1000张图片,画出它们上的包围框,并手动检查标签。这是一种理智检查,有时你会发现错误的画框和不正确的标签。
- 另一个问题可能是缺乏多样性,正如你所提到的。你的训练集中有20K的图像,但可能最多只有34个独特的杯子(假设杯子是一个类)。也许所有这些杯子的颜色都是白色、蓝色或棕色,但在你的验证中,杯子是鲜红色的。(我希望你明白这个想法)。
- 试着玩一下超参数。探索一个略低或稍长的学习率,较长的热身时间,较强的体重衰减。我假设这些是您正在使用的设置;尝试增加马赛克、复制粘贴、翻转等概率。如果更强的增强参数正在产生积极的效果,这可能是一个提示,即问题在于数据集是冗余的,并且缺乏多样性。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74507437
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号