
推特情感得分的R分解
我试图分解R中twitter情绪评分的时间序列数据,这里是我的twitter情绪分析后的dput()数据。
dput(text_dfbtc$total_score)
c(-1, -2, 2, 2, -3, 2, 5, -5, -2, 2, 5, 1, 1, -2, 2, 3, 4, 1,
5, 1, 7, 3, 1, -6, 0, -1, 1, 3, -3, -12, -12, 1, -4, -18, 3,
1, 4, .... 0, 0, -4)共有3251个参赛作品。
我使用以下命令将其转换为时间序列数据:
ts_textdfbtc1 <- zoo(text_dfbtc$total_score,
order.by = seq(as.POSIXct("2022-09-18 00:00:00"), length=46019, by="min"))46019是起点到终点之间的分钟数。当我的Twitter数据在两个时间段之间每分钟返回一条消息时。
时间序列数据的以下命令head()结果为:
head(ts_textdfbtc1)
2022-09-18 00:00:00 2022-09-18 00:01:00 2022-09-18 00:02:00 2022-09-18 00:03:00 2022-09-18 00:04:00 2022-09-18 00:05:00
-1 -2 2 2 -3 2 但是,当我使用:
frequency(ts_textdfbtc1)
0.01666667对于分解函数,我最终得到的错误是,我的数据没有或少于两个句点。我该怎么纠正呢?否则,我在监督什么或者做错了什么?
回答 1
Stack Overflow用户
发布于 2022-11-20 20:43:24
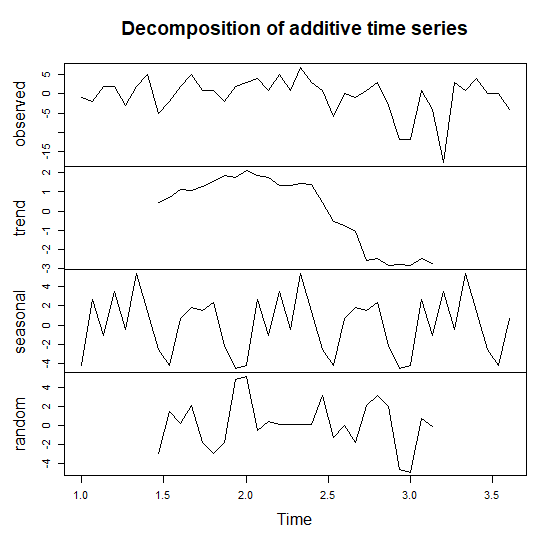
您不能将POSIXct与decompose结合使用,因为decompose要求将数据用循环表示。也就是说,decompose假定一个周期由1个单元表示,而POSIXct则有一个作为单元的第二个单元。假设我们希望一个循环是15个元素,在这种情况下是15分钟--将这个数字改为任何一个自然循环,以确保数据中至少有两个完整的循环,所以如果有40个点,如注释中的结尾,最大的循环可能是20个。如果循环长度为15,定义tt的tt语句将生成1+0/ 15,1+1/15,1+2/15等次数。通过删除点(请参阅下面的注释)来修正问题中显示的输入数据,我们有以下内容。不使用包装。plot输出的X轴对应于tt,处于循环状态,即前15点是从1.0开始的第一个周期,第二个15点是从2.0开始的第二个循环,等等。
tt <- ts(score, frequency = 15)
d <- decompose(tt)
plot(d)
备注
score <- c(-1, -2, 2, 2, -3, 2, 5, -5, -2, 2, 5, 1, 1, -2, 2, 3, 4, 1,
5, 1, 7, 3, 1, -6, 0, -1, 1, 3, -3, -12, -12, 1, -4, -18, 3,
1, 4, 0, 0, -4)https://stackoverflow.com/questions/74500250
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号