
如何在熊猫数据中只聚集几行?
如何在熊猫数据中只聚集几行?
提问于 2022-11-17 21:11:56
我正在开发一个包含一些交易信息的数百万行的熊猫数据仓库。
示例dataframe:
df = pd.DataFrame({'ProductID': ['Afiliates','Afiliates','Afiliates','Afiliates','Afiliates','Afiliates'],
'partner': ['Amazon','Awin','Amazon','Amazon','Amazon','Amazon'],
'date': [dt.date(2022,11,1),dt.date(2022,11,5),dt.date(2022,11,1),dt.date(2022,11,10),dt.date(2022,11,15),dt.date(2022,11,1)],
'customerID' : ['01','01','01','01','02','01'],
'brand' : ['Amazon','Ponto','Amazon','Amazon','Amazon','Amazon'],
'sku':['firetv','alexa','alexa','firetv','firetv','firetv'],
'transactionID': ['51000','55000','51000','53000','54000','51000'],
'gmv' : [10,50,30,40,50,60] })我正在研究一种方法来聚合一些相关的行(相同的transactionID),保留所有的列和结构。
我尝试在所有列上执行一个groupby,并对品牌(list)和gmv (sum)执行一些聚合函数。
df.groupby(['ProductID','partner','date','customerID','brand','transactionID']).aggregate({'sku':list, 'gmv':'sum'})我的问题是,如您所见,如何创建一个“唯一”itens列表,例如,聚合后'firetv‘可能会在同一行中出现几次。
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-11-17 21:16:46
可以使用set()删除重复项,例如:
x = df.groupby(
["ProductID", "partner", "date", "customerID", "brand", "transactionID"]
).aggregate({"sku": lambda x: list(set(x)), "gmv": "sum"})
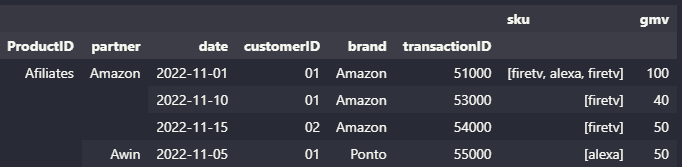
print(x)指纹:
sku gmv
ProductID partner date customerID brand transactionID
Afiliates Amazon 2022-11-01 01 Amazon 51000 [firetv, alexa] 100
2022-11-10 01 Amazon 53000 [firetv] 40
2022-11-15 02 Amazon 54000 [firetv] 50
Awin 2022-11-05 01 Ponto 55000 [alexa] 50页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74482145
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号