
scikit学习培训和测试拆分返回NaNs
scikit学习培训和测试拆分返回NaNs
提问于 2022-11-16 06:54:30
我的样本数据如下所示
customer_id revenue_m10 revenue_m9 revenue_m8 target
1 1234 1231 1256 1239
2 5678 3425 3255 2345我正在尝试将我的数据集分割成基于scikit-learn的train_test_split模块的训练和测试。
所以,我尝试了下面的代码
X_train,X_test,y_train, y_test = train_test_split(
sample_set_df[all_features],
sample_set_df[target_var],
test_size=0.3
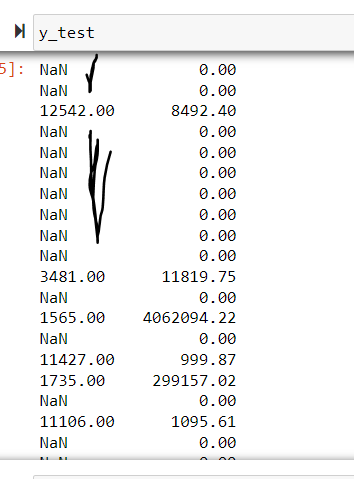
)但是当我查看y_test时,它看起来如下所示,NaNs如下所示。不知道是什么问题。是否缺少索引号或其他问题?
如果索引是个问题,我知道我们该如何解决这个问题?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-11-16 11:54:20
y_test是一个熊猫系列,打印它显示它的索引和数据。sample_set_df的索引中似乎包含了NaNs。
索引中包含NaNs并不影响train_test_split如何分割数据。不过,您可能对实际数据有问题。当您有NaNs时,目标是0。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74456312
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号