
除了几列之外,我如何合并包含相同数据的3个Pandas DataFrames?
除了几列之外,我如何合并包含相同数据的3个Pandas DataFrames?
提问于 2022-11-14 22:05:31
我有3个pd.DataFrame需要合并。除最后5列外,每个列包含相同的数据,每个列为9276行x67cols。从原理上看,它们是这样的:
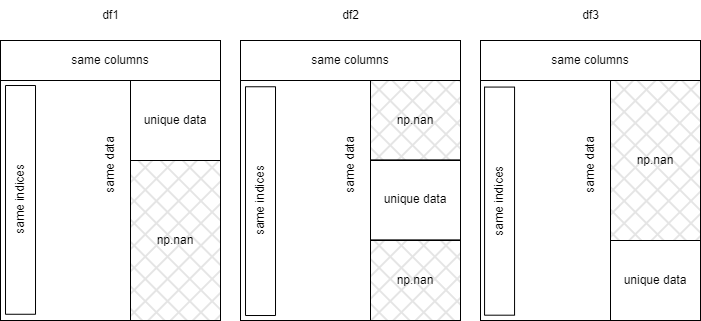
MWE的数据:
df1 = pd.DataFrame({"A": [4, 5, 6, 7, 8, 9], "B": [2, 2, 2, 3, 3, 3], "C": [np.nan, np.nan, 5, 5, 6, 6]})
df2 = pd.DataFrame({"A": [4, 5, 6, 7, 8, 9], "B": [2, 2, 2, 3, 3, 3], "C": [4, 4, np.nan, np.nan, 6, 6]})
df3 = pd.DataFrame({"A": [4, 5, 6, 7, 8, 9], "B": [2, 2, 2, 3, 3, 3], "C": [4, 4, 5, 5, np.nan, np.nan]})
expectation = pd.DataFrame({"A": [4, 5, 6, 7, 8, 9], "B": [2, 2, 2, 3, 3, 3], "C": [4.0, 4.0, 5.0, 5.0, 6.0, 6.0]})
print(expectation)
A B C
0 4 2 4.0
1 5 2 4.0
2 6 2 5.0
3 7 3 5.0
4 8 3 6.0
5 9 3 6.0我试过pd.merge,pd.concat,他们有不同的论点,但他们不做这件事。我看过的文档和其他问题都没有数据的相同结构;它们都使用具有唯一索引或唯一列的示例。而且,在实践中,我的数据仍将包含np.nan的其他部分的数据,我需要保存,所以我不能dropna或任何类似的东西。如何在维护数据库结构的同时合并数据文件?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-11-14 22:46:05
由于您的所有索引都是相同的,所以最简单的方法是带有dataframe参数的DataFrame.fillna():
df1.fillna(df2).fillna(df3)输出:
A B C
0 4 2 4.0
1 5 2 4.0
2 6 2 5.0
3 7 3 5.0
4 8 3 6.0
5 9 3 6.0页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74438393
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号