
KSQLDB拉拔性能
KSQLDB拉拔性能
提问于 2022-11-14 21:59:06
我知道KSQLDB中的每个分区都生成一个RocksDbTable。另外,KSQLDB重新分区,以便将相同的密钥存储在同一个分区中。
但是我找不到任何关于查询性能的答案。KSQLDB拉出的效率有多高?它扫描整张桌子吗?它是否查询在RocksDb中具有与其关联的索引的键?您可以禁用表扫描,但默认行为是什么?
既然它有RocksDB (它是一个键/值存储),那么它不需要任何中间的ksqldb操作就可以查找密钥,并且不需要扫描,这样做安全吗?
回答 1
Stack Overflow用户
发布于 2022-11-14 22:49:43
RocksDB建立在LSM树(和SSTables)上。它是一个键值数据存储。
任何基于LSM的数据库都将数据存储在两个级别上。
- 红黑树在内存中
- 排序集表在磁盘
中
对于磁盘中的ups,它使用稀疏索引,如下所示。顾名思义,SSTable是一个保存在磁盘上的已排序的键数组。这一点在下面的图片中很明显。
如果在下面的片段中查找关键的“美元”。
查找步骤-
如果不存在,
- 在红黑树(或memtable)中查找“美元”,然后继续使用磁盘。磁盘处的
- :在稀疏索引上执行二进制搜索,以发现键“美元”介于"dog“和”
- “之间,从偏移量17208到19504,以便找到值。(这个偏移号映射到SSTable或驱动器上的物理文件)。一旦我们知道文件号,
- 。对SSTables中的所有条目进行排序。因此,再次应用二进制搜索。
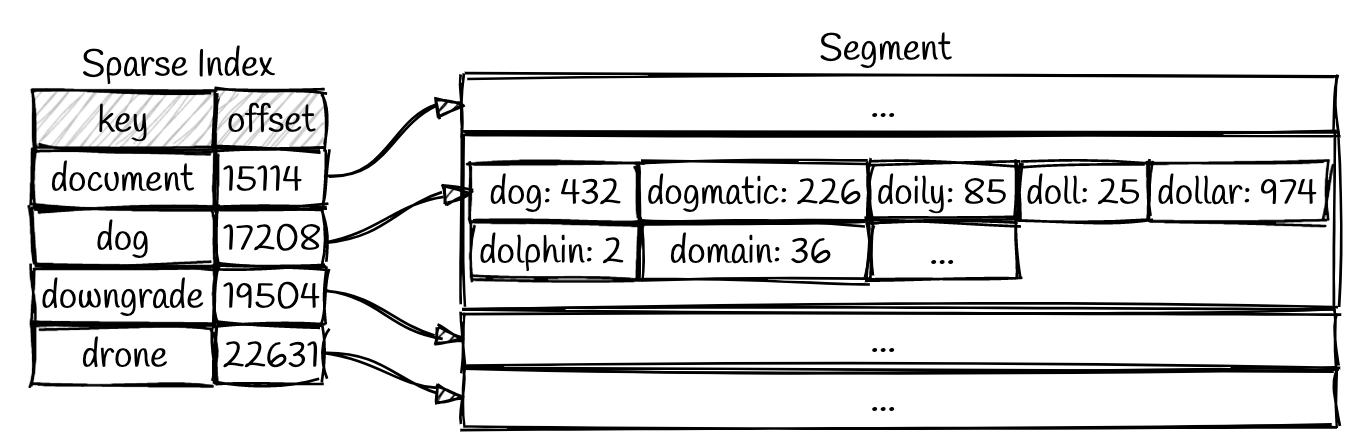
所以,你可以看到,没有扫描。
对于不存在的键,它使用“布卢姆-过滤器”来推断键不存在,因此它不会扫描所有段。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74438337
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号