
KNN Python实现
KNN Python实现
提问于 2022-11-11 18:46:39
当我尝试运行我的代码时,如下所示:
FutureWarning:与其他还原函数(例如
skew、kurtosis)不同,mode的默认行为通常保持它所遵循的轴。在SciPy 1.11.0中,此行为将发生变化:keepdims的默认值将变为False,统计数据所经过的axis将被消除,而None值将不再被接受。将keepdims设置为True或False以避免此警告。lab =模式(标签)
这是我的Python代码,我发现在寻找合适的解决方案时遇到了一些困难:
# Importing the required modules
import numpy as np
from scipy.stats import mode
# Euclidean Distance
def eucledian(p1, p2):
dist = np.sqrt(np.sum((p1 - p2) ** 2))
return dist
# Function to calculate KNN
def predict(x_train, y, x_input, k):
op_labels = []
# Loop through the Datapoints to be classified
for item in x_input:
# Array to store distances
point_dist = []
# Loop through each training Data
for j in range(len(x_train)):
distances = eucledian(np.array(x_train[j, :]), item)
# Calculating the distance
point_dist.append(distances)
point_dist = np.array(point_dist)
# Sorting the array while preserving the index
# Keeping the first K datapoints
dist = np.argsort(point_dist)[:k]
# Labels of the K datapoints from above
labels = y[dist]
** # Majority voting
lab = mode(labels)
lab = lab.mode[0]
op_labels.append(lab)**
return op_labels
# Importing the required modules
# Importing required modules
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
from numpy.random import randint
# Loading the Data
iris= load_iris()
# Store features matrix in X
X= iris.data
# Store target vector in
y = iris.target
# Creating the training Data
train_idx = xxx = randint(0, 150, 100)
X_train = X[train_idx]
y_train = y[train_idx]
# Creating the testing Data
test_idx = xxx = randint(0, 150, 50) # taking 50 random samples
X_test = X[test_idx]
y_test = y[test_idx]
# Applying our function
y_pred = predict(X_train, y_train, X_test, 7)
# Checking the accuracy
accuracy_score(y_test, y_pred)我期待一个预测/准确的提示。
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-11-11 20:24:19
KNN可以这样做。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data"
# Assign colum names to the dataset
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'Class']
# Read dataset to pandas dataframe
dataset = pd.read_csv(url, names=names)
dataset.head()
X = dataset.iloc[:, :-1].values
y = dataset.iloc[:, 4].values
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)
from sklearn.neighbors import KNeighborsClassifier
classifier = KNeighborsClassifier(n_neighbors=5, metric='minkowski')
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
from sklearn.metrics import classification_report, confusion_matrix
print(confusion_matrix(y_test, y_pred))
print(classification_report(y_test, y_pred))
# Result:
precision recall f1-score support
Iris-setosa 1.00 1.00 1.00 13
Iris-versicolor 1.00 0.89 0.94 9
Iris-virginica 0.89 1.00 0.94 8
accuracy 0.97 30
macro avg 0.96 0.96 0.96 30
weighted avg 0.97 0.97 0.97 30
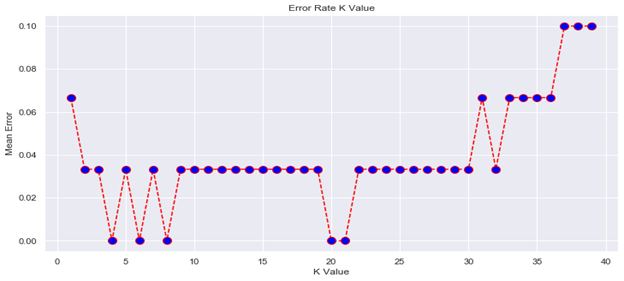
error = []
# Calculating error for K values between 1 and 40
for i in range(1, 40):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train, y_train)
pred_i = knn.predict(X_test)
error.append(np.mean(pred_i != y_test))
plt.figure(figsize=(12, 6))
plt.plot(range(1, 40), error, color='red', linestyle='dashed', marker='o',
markerfacecolor='blue', markersize=10)
plt.title('Error Rate K Value')
plt.xlabel('K Value')
plt.ylabel('Mean Error')
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74406936
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号