
如何从带有错误时间戳的YouTube字幕中生成有效的时间戳?(使用管)
如何从带有错误时间戳的YouTube字幕中生成有效的时间戳?(使用管)
提问于 2022-11-05 19:21:40
使用pytube,我尝试下载一个YouTube视频,翻译字幕并将翻译后的字幕嵌入到视频中,然后下载到我的PC上。
这是我代码的一部分,修改后的代码很容易理解。
from pytube import YouTube as YT
yt = YT("https://www.youtube.com/watch?v=ZFGAz6vZx1E")
caption_code = ''
try:
captions = yt.captions['en']
caption_code = 'en'
except:
try:
captions = yt.captions['a.en']
caption_code = 'a.en'
except Exception as e:
raise e
captions = yt.captions.get_by_language_code(caption_code)
test_captions(captions)### just a function to test how's the cations are structured.
def test_captions(captions):
caption_list = []
index = 0
for line in str(captions.generate_srt_captions()).split('\n'):
if index == 0:
caption_list.append({})
if index in (1, 2):
caption_list[len(caption_list)-1][('time', 'caption')[index-1]] = line
index += 1
if line == '':
index = 0
for dic in caption_list:
print('{} : {}'.format(dic['time'], dic['caption']))在最初的YouTube视频中,标题开始于第1秒(应在00:00:01,000左右)
第一次下载带有时间戳的说明句:"00:01:20,000 -> 00:52:00,000 :发生了什么,约翰·艾尔德
从控制台可以看到,根据SRT时间戳惯例,字幕有错误的时间戳。
(在https://www.3playmedia.com/上解释的SRT时间戳惯例)
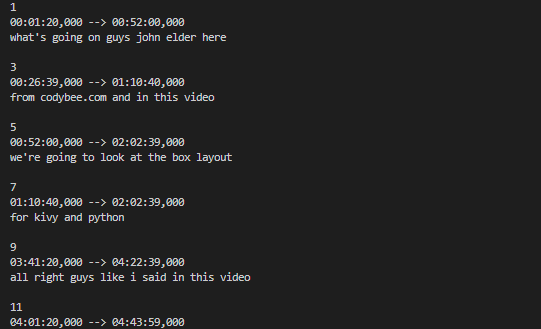
第一个时间戳基本上是说句子应该从1sr分钟20秒显示到52分钟,这显然是错误的。
是否有可能修复它,如果没有,我如何规范标题的时间戳以符合有效的SRT时间戳格式?
回答 1
Stack Overflow用户
发布于 2022-11-18 21:39:16
当以xml形式生成标题时,您会注意到由于某种原因,时间乘以1000。
"t=“之后的时间是文本以秒为单位出现的时间,"d=”是文本结束时的时间。
{kind=link}
所以我只是浪费了时间,除以1000,把它写成“小时:分钟:第二分钟”,把文字放到我的file.srt中。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74330836
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号