
股票数据缺口填补
股票数据缺口填补
提问于 2022-11-02 10:01:06
我在测试一种在填补缺口上交易的策略。
鉴于AAPL在2022-10-04年创造了一个向上的缺口,在2022-10-07年填补了这一缺口(而且将有多个缺口),那么如何确定最近的向上缺口是否以节奏式的方式填补?
代码:
import pandas_datareader as pdr
df = pdr.data.DataReader('AAPL', 'yahoo', start='2022-07-28', end='2022-09-01')
df['upward_gap'] = df['Low'] > df['High'].shift(1) # identify upward gap
df['upward_gap_no'] = df['upward_gap'].cumsum()当前产出:
High Low ... upward_gap upward_gap_no
Date ...
2022-08-08 167.809998 164.199997 ... False 0
2022-08-09 165.820007 163.250000 ... False 0
2022-08-10 169.339996 166.899994 ... True 1
2022-08-11 170.990005 168.190002 ... False 1
2022-08-12 172.169998 169.399994 ... False 1
2022-08-15 173.389999 171.350006 ... False 1
2022-08-16 173.710007 171.660004 ... False 1
2022-08-17 176.149994 172.570007 ... False 1
2022-08-18 174.899994 173.119995 ... False 1
2022-08-19 173.740005 171.309998 ... False 1
2022-08-22 169.860001 167.139999 ... False 1
2022-08-23 168.710007 166.649994 ... False 1
2022-08-24 168.110001 166.250000 ... False 1
2022-08-25 170.139999 168.350006 ... True 2
2022-08-26 171.050003 163.559998 ... False 2
2022-08-29 162.899994 159.820007 ... False 2
2022-08-30 162.559998 157.720001 ... False 2
2022-08-31 160.580002 157.139999 ... False 2预期产出(对任何更好的代表性开放):
High Low ... upward_gap upward_gap_no
Date ...
2022-08-08 167.809998 164.199997 ... False 0
2022-08-09 165.820007 163.250000 ... False 0
2022-08-10 169.339996 166.899994 ... True 1 - 1st upward gap
2022-08-11 170.990005 168.190002 ... False 1
2022-08-12 172.169998 169.399994 ... False 1
2022-08-15 173.389999 171.350006 ... False 1
2022-08-16 173.710007 171.660004 ... False 1
2022-08-17 176.149994 172.570007 ... False 1
2022-08-18 174.899994 173.119995 ... False 1
2022-08-19 173.740005 171.309998 ... False 1
2022-08-22 169.860001 167.139999 ... False 1
2022-08-23 168.710007 166.649994 ... False 1
2022-08-24 168.110001 166.250000 ... False 1
2022-08-25 170.139999 168.350006 ... True 2 - 2nd upward gap
2022-08-26 171.050003 163.559998 ... False 0 - Both 1st & 2nd gap filled
2022-08-29 162.899994 159.820007 ... False 0
2022-08-30 162.559998 157.720001 ... False 0
2022-08-31 160.580002 157.139999 ... False 0回答 1
Stack Overflow用户
发布于 2022-11-02 16:14:37
好吧--虽然这并不是你所期望的,但我想我有些东西能满足你的要求。但是,我还没有对其他层次的差距做过任何事情,但是,我已经考虑到了基本的差距(或者您所称的upward gap 1)。
<> check_gap值()用于标识包含high_check号的行。
- (
E 110黄色E 211)是d12值,用于标识空白何时填补。H 213H 114D 15编号(E 116绿色E 217/code>)一直保持d18,直到d19值下降到d20编号以下。H 221/code>代码H 122>代码<代码<<>代码> >代码>>代码><<225>代码>但是由于它们在另一个upward_gap.
中而被忽略。
import pandas_datareader as pdr
df = pdr.data.DataReader('AAPL', 'yahoo', start='2022-07-28', end='2022-09-01')
df['check_gap'] = (df['Low'] > df['High'].shift(1)).shift(-1).fillna(False) # identify upward gap
start_checking = False
previous = False
skip_one = False
high_check = 0
upward_gap = []
high_check_list = []
for (cg, low, high) in zip(df['check_gap'], df['Low'], df['High']):
if cg and not start_checking:
start_checking = True
high_check = high
skip_one = True
if start_checking and not skip_one:
if low < high_check:
start_checking = False
high_check = 0
elif skip_one:
skip_one = False
if start_checking and cg and not previous:
high_check_list.append(0)
upward_gap.append(False)
else:
upward_gap.append(start_checking)
high_check_list.append(high_check)
previous = start_checking
df['high_check'] = high_check_list
df['upward_gap'] = upward_gap
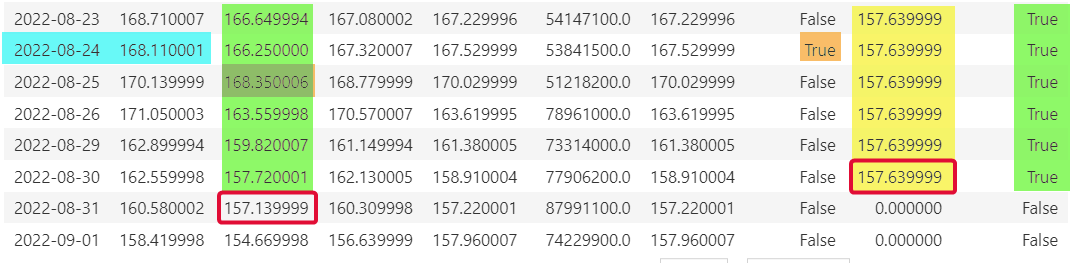
df输出:
..。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74287381
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号