
带有uvicorn的FastAPI不允许线程使用率超过65%
我编写了一个机器学习推理库,它有python绑定。在正常操作下,该库将使用8个线程进行推理,并将所有8个线程全部释放100%。这是所需的行为,因为模型非常重,我需要为低延迟进行优化(因此我需要使用所有的CPU资源)。
如果我编写一个python脚本并调用这个库中的推理函数(在一个无限循环中),这8个线程就会如预期的那样被最大化(这是htop命令的输出)。
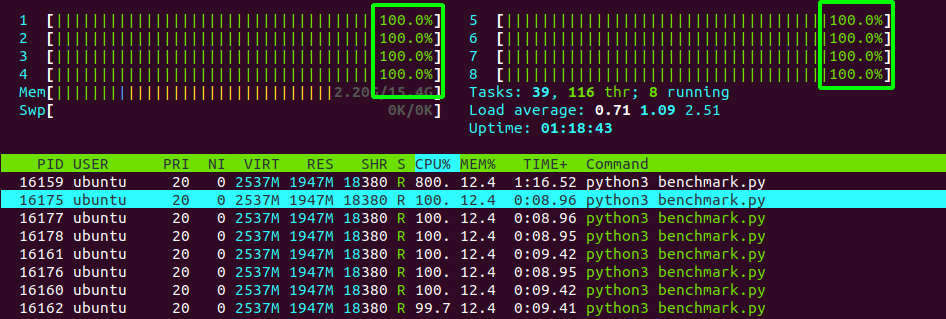
现在我有个问题。我需要在我编写的FastAPI服务器中调用这个机器学习库。我在我的docker容器中使用下面的命令来启动FastAPI服务器CMD uvicorn main:app --host 0.0.0.0 --port 8080。可以看到,我使用uvicorn。
现在,事情变得有趣了。如果我在机器学习库中调用相同的推理函数,再次在无限循环中调用,但这次是从我的FastAPI端点中调用的,那么每个线程的CPU使用量上限为65%,不会超过这个值。
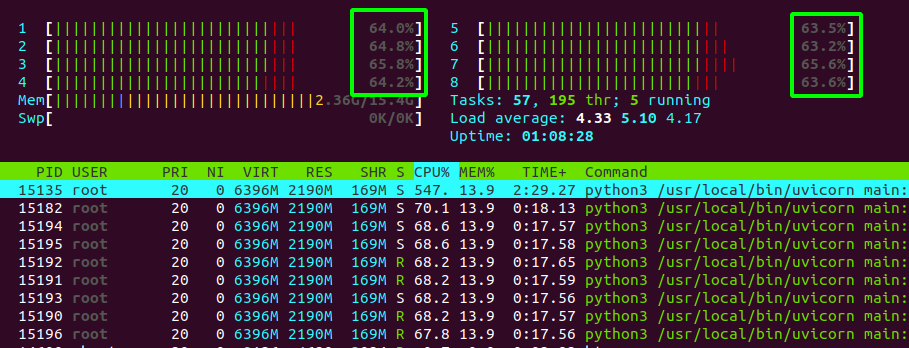
对CPU使用为什么被限制有任何想法吗?我想让它达到100%,充分利用CPU。由于CPU的使用被限制,我的性能下降了。
回答 1
Stack Overflow用户
发布于 2022-11-02 19:25:30
我能确定问题出在哪里。
我已经将我的端点定义为def,并且根据FastAPI文档,它将把请求分派给一个线程池。这肯定导致了某种类型的CPU争用,可能与Python有关。将端点切换到async def解决了问题,并允许每个线程达到100%的CPU使用率。因此,它减少了约30%的潜伏期。
https://stackoverflow.com/questions/74229072
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号