
AttributeError:非类型对象没有属性“查找”
AttributeError:非类型对象没有属性“查找”
提问于 2022-10-27 21:01:32
from bs4 import BeautifulSoup
import requests
job_request = requests.get('https://www.google.com/search?q=Software+engineer+&sxsrf'
'=ALiCzsaeLLjcCHZk46ernxCkoay7ldkDsA:1666897166012&source=hp&ei=DdVaY-CHOvvgkPIPxc2m6Ag'
'&iflsig=AJiK0e8AAAAAY1rjHgG0CdqkcKPC3aVnmBvSGuZgc6Py&uact=5&oq=Job+listings&gs_lcp'
'=Cgdnd3Mtd2l6EAMyBwgjEMkDECcyCggAEIAEEIcCEBQyDQgAEIAEELEDEIMBEAoyDQgAEIAEELEDEIMBEAo'
'yBQgAEIAEMgUIABCABDIFCAAQgAQyCggAEIAEELEDEAoyDQgAEIAEELEDEIMBEAoyDQgAEIAEELEDEIMBEAo6BAg'
'jECc6BQgAEJECOgsILhCABBCxAxCDAToLCAAQgAQQsQMQgwE6CwguEIAEEMcBENEDOg4ILhCABBCxAxCDARDUAjoLCC'
'4QgAQQsQMQ1AI6EQguEIAEELEDEIMBEMcBEK8BOggIABCABBCxAzoHCAAQgAQQCjoICAAQyQMQkQI6EAgAEIAEEIcCE'
'LEDEIMBEBQ6DQgAEIAEEIcCELEDEBQ6CwguELEDEMcBENEDOhMILhCABBCHAhCxAxDHARDRAxAUOgsILhCABBDHARCv'
'AToICC4QgAQQ5QRQAFjbFGDEFWgCcAB4AYABoQGIAcYLkgEEMy4xMJgBAKABAQ&sclient=gws-wiz&ibp=htl;jobs'
'&sa=X&ved=2ahUKEwijh7Dti4H7AhXzkWoFHddJCAMQudcGKAJ6BAgNEC8#fpstate=tldetail&htivrt=jobs&ht'
'idocid=4XlU2-oL0UgAAAAAAAAAAA%3D%3D').text
beautify = BeautifulSoup(job_request, 'lxml')
listing = beautify.find('li', class_ = 'iFjolb gws-plugins-horizon-jobs__li-ed')
company = listing.find('div', class_ = 'oNwCmf').text我是新的HTML和网页抓取,我不确定'div‘标签是如何找到确切的BS4。任何帮助都将不胜感激。最终的目标是从站点中抓取列表,并最终将其导入DB。
回答 1
Stack Overflow用户
发布于 2022-10-28 02:28:41
错误可能是因为listing的值为None --因为第一个find没有返回任何内容。在使用requests+beautifulsoup时,您应该养成一种习惯,即当您的代码没有按照预期的方式运行时,检查requests返回的内容。使用
with open('x.html', 'w', encoding="utf8") as f:
f.write(str(job_request))若要将job_request保存到名为"x.html“的文件中,可以打开该文件以查看您收到的响应类型。对我来说,就像
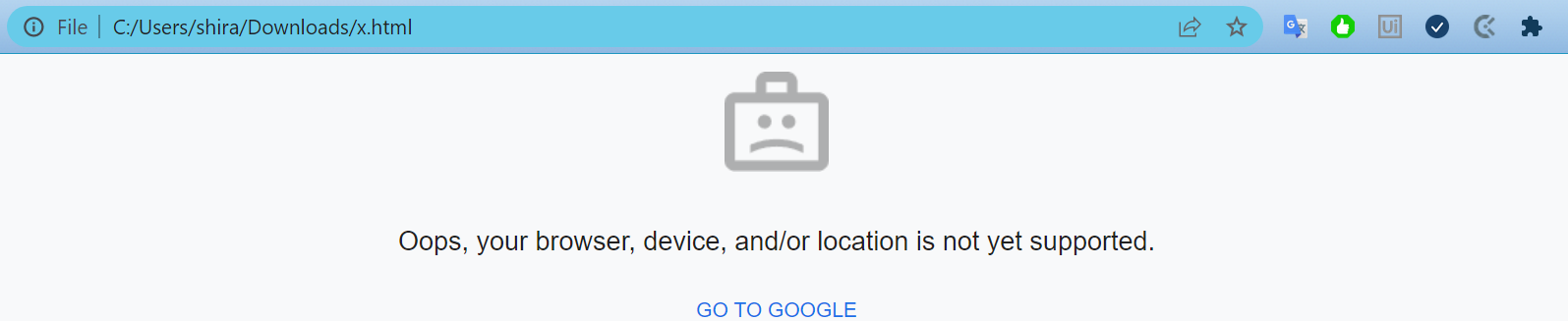
如果您看到了同样的事情,您可能只需在请求中添加一些标头就可以解决它--对我来说,仅仅添加用户代理就足够了。
headers = {"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.79 Safari/537.36"}但我认为,最接近于模仿浏览器的是从浏览器复制请求,然后使用卷曲转换器获取您可以粘贴到自己浏览器中的python代码。
{kind=link}
即便如此,您可能还是会注意到,只有前10个结果位于获取的html中-其余的都是用JavaScript填充的,而且可能是API;如果您想要超过前十个-和/或者如果添加头对您不起作用-您可能不得不求助于类似硒.
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74228268
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号