
如何根据熊猫中的其他几个栏过滤一个列?
几年来,我有各种水果品种的价格数据集。我希望根据多个其他列的值筛选列。dataframe如下所示:
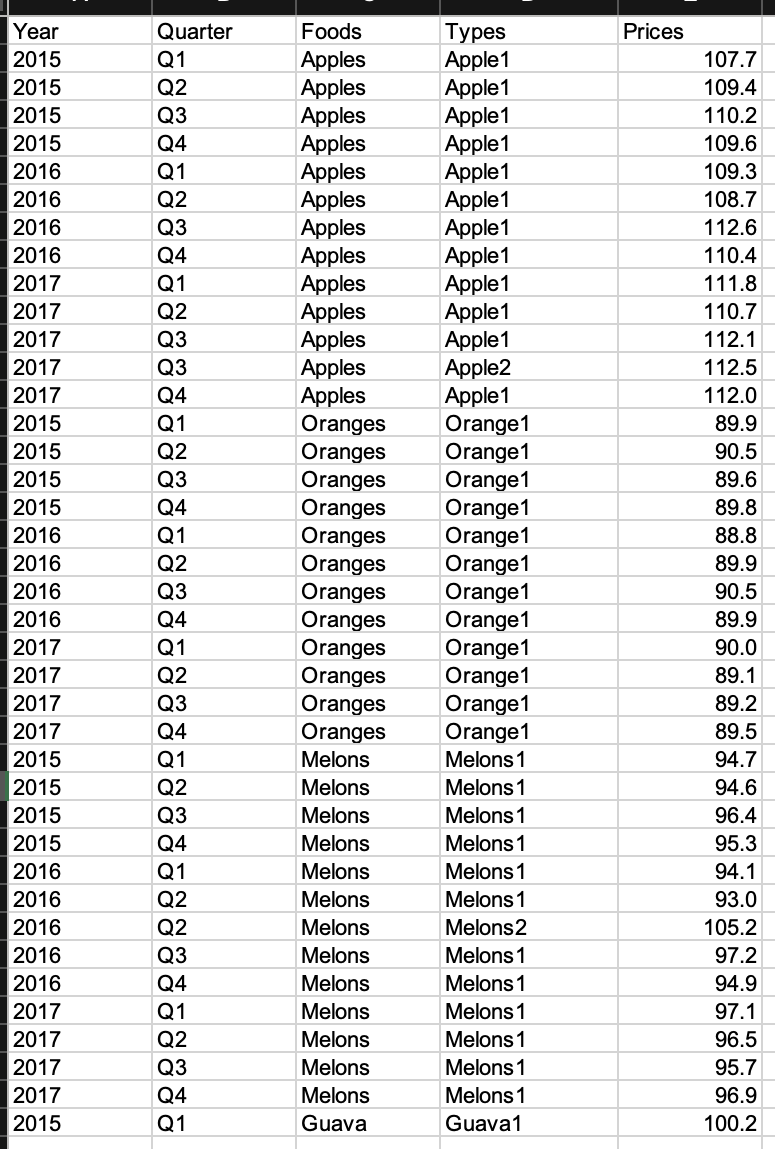
第一栏包含年份。列2可以包含4个季度的Q1、Q2、Q3和Q4。第3栏载有食物的名称。第4栏载有第3栏所列食物的种类/品种。最后,第5栏载列单位价格。
我只想考虑那些从2015-2017年每年4个季度都有价格数据的食品。所以,我只吃苹果、橘子和瓜,不吃番石榴。番石榴没有2015-2017年所有季度和所有年份的价格数据。
我想要的dataframe将有13列如下所示。第一栏将列出符合上述标准的食品。其余栏目将显示特定季度和年份的价格。有一个微妙之处。
对于给定的食物,如果有重复的季度和重复的年份,同时,那就意味着有超过一种食物。例如,对于第3栏中的Apple,同时有重复的Q3和重复的2017。这是因为在该季度的数据中有两种类型的苹果-- apple1和apple2。在这种情况下,我想在我需要的数据中取他们的算术平均价格(和/freq)。因此,苹果在Q3_2017的价格将是(112.1+112.5)/2=112.3。
我想要的数据格式是
Foods Q1_2015 Q2_2015 Q3_2015 Q4_2015 Q1_2016 Q2_2016 Q3_2016 Q4_2016 Q1_2017 Q2_2017 Q3_2017 Q4_2017
Apples
Oranges
Melons由于需要操作几个列,我无法使用groupby方法。我怎样才能得到上面的数据?任何帮助都是非常感谢的。
回答 2
Stack Overflow用户
发布于 2022-10-27 06:48:28
每年在GroupBy.transform中使用DataFrameGroupBy.nunique,只对Quarter中有4个唯一值的组和Year存在于Series.isin中的组使用食品,然后在boolean indexing中筛选
DataFrame.pivot_table与扁平MultiIndex的最后一次旋转
years = [2015,2016,2017]
mask = (df.groupby(['Foods','Year'])['Quarter'].transform('nunique').eq(4) &
df['Year'].isin(years))
df = df[mask]
#pivoting and aggregate mean
df1=df.pivot_table(index='Foods',columns=['Year','Quarter'],values='Prices',aggfunc='mean')
df1.columns = df1.columns.map(lambda x: f'{x[0]}_{x[1]}')
print (df1)
2015_Q1 2015_Q2 2015_Q3 2015_Q4 2016_Q1 2016_Q2 2016_Q3 \
Foods
Apples 107.7 109.4 110.2 109.6 109.3 108.7 112.6
Melons 94.7 94.6 96.4 95.3 94.1 99.1 97.2
Oranges 89.9 90.5 89.6 89.8 88.8 89.9 90.5
2016_Q4 2017_Q1 2017_Q2 2017_Q3 2017_Q4
Foods
Apples 110.4 111.8 110.7 112.3 112.0
Melons 94.9 97.1 96.5 95.7 96.9
Oranges 89.9 90.0 89.1 89.2 89.5 编辑:对于列Foods,请使用DataFrame.reset_index
df1 = df1.reset_index()Stack Overflow用户
发布于 2022-10-27 05:51:31
s ="""Year Quarter Foods Types Prices
2015 Q1 Apples Apple1 107.7
2015 Q2 Apples Apple1 109.4
2015 Q3 Apples Apple1 110.2
2015 Q4 Apples Apple1 109.6
2016 Q1 Apples Apple1 109.3
2016 Q2 Apples Apple1 108.7
2016 Q3 Apples Apple1 112.6
2016 Q4 Apples Apple1 110.4
2017 Q1 Apples Apple1 111.8
2017 Q2 Apples Apple1 110.7
2017 Q3 Apples Apple1 112.1
2017 Q3 Apples Apple2 112.5
2017 Q4 Apples Apple1 112.0
2015 Q1 Oranges Orange1 89.9
2015 Q2 Oranges Orange1 90.5
2015 Q3 Oranges Orange1 89.6
2015 Q4 Oranges Orange1 89.8
2016 Q1 Oranges Orange1 88.8
2016 Q2 Oranges Orange1 89.9
2016 Q3 Oranges Orange1 90.5
2016 Q4 Oranges Orange1 89.9
2017 Q1 Oranges Orange1 90.0
2017 Q2 Oranges Orange1 89.1
2017 Q3 Oranges Orange1 89.2
2017 Q4 Oranges Orange1 89.5
2015 Q1 Melons Melons 1 94.7
2015 Q2 Melons Melons 1 94.6
2015 Q3 Melons Melons 1 96.4
2015 Q4 Melons Melons 1 95.3
2016 Q1 Melons Melons 1 94.1
2016 Q2 Melons Melons 1 93.0
2016 Q2 Melons Melons 2 105.2
2016 Q3 Melons Melons 1 97.2
2016 Q4 Melons Melons 1 94.9
2017 Q1 Melons Melons 1 97.1
2017 Q2 Melons Melons 1 96.5
2017 Q3 Melons Melons 1 95.7
2017 Q4 Melons Melons 1 96.9
2015 Q1 Guava Guava1 100.2"""
df = pd.DataFrame([x.split('\t') for x in s.split('\n')])
df = df.rename(columns=df.iloc[0]).drop(df.index[0]).reset_index(drop=True)
df["Prices"] = pd.to_numeric(df["Prices"]) # ensuring prices are numeric我在这里使用年份作为字符串,因为这个问题没有特定于日期的操作。您可以根据需要对代码进行调整。
fy= ['2015', '2016', '2017'] # list of years interested in
ar = []
for name, group in df.groupby('Foods'):
if list(group['Year'].unique()) ==fy: # compare years with your year list
# aggreagrate multiple price enteries
temp = group.groupby(['Year','Foods','Quarter'], as_index=False)['Prices'].mean()
ar.append(temp)
df_temp = pd.concat(ar).reset_index(drop=True) # create a new dataframe
# restructure the dataframe with food as the index, and year and quater as columns
df_temp = df_temp.pivot(index='Foods',columns=['Year','Quarter'],values='Prices')
# format the column names
df_temp.columns = [f'{y}_{x}' for x,y in df_temp.columns] # x is year and y is quater
df_temp = df_temp.reset_index()
df_temp Foods Q1_2015 Q2_2015 Q3_2015 Q4_2015 Q1_2016 Q2_2016 Q3_2016 Q4_2016 Q1_2017 Q2_2017 Q3_2017 Q4_2017
0 Apples 107.7 109.4 110.2 109.6 109.3 108.7 112.6 110.4 111.8 110.7 112.3 112.0
1 Melons 94.7 94.6 96.4 95.3 94.1 99.1 97.2 94.9 97.1 96.5 95.7 96.9
2 Oranges 89.9 90.5 89.6 89.8 88.8 89.9 90.5 89.9 90.0 89.1 89.2 89.5https://stackoverflow.com/questions/74216550
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号