
为什么我的强化算法不学习?
为什么我的强化算法不学习?
提问于 2022-10-26 20:44:57
我正在CartPole环境上训练一个增强算法。由于环境的简单性质,我希望它能很快学习。然而,这种情况并没有发生。
这是算法的主要部分-
for i in range(episodes):
print("i = ", i)
state = env.reset()
done = False
transitions = []
tot_rewards = 0
while not done:
act_proba = model(torch.from_numpy(state))
action = np.random.choice(np.array([0,1]), p = act_proba.data.numpy())
next_state, reward, done, info = env.step(action)
tot_rewards += 1
transitions.append((state, action, tot_rewards))
state = next_state
if i%50==0:
print("i = ", i, ",reward = ", tot_rewards)
score.append(tot_rewards)
reward_batch = torch.Tensor([r for (s,a,r) in transitions])
disc_rewards = discount_rewards(reward_batch)
nrml_disc_rewards = normalize_rewards(disc_rewards)
state_batch = torch.Tensor([s for (s,a,r) in transitions])
action_batch = torch.Tensor([a for (s,a,r) in transitions])
pred_batch = model(state_batch)
prob_batch = pred_batch.gather(dim=1, index=action_batch.long().view(-1, 1)).squeeze()
loss = -(torch.sum(torch.log(prob_batch)*nrml_disc_rewards))
opt.zero_grad()
loss.backward()
opt.step()这是整个算法-
#I referred to this when writing the code - https://github.com/DeepReinforcementLearning/DeepReinforcementLearningInAction/blob/master/Chapter%204/Ch4_book.ipynb
import numpy as np
import gym
import torch
from torch import nn
env = gym.make('CartPole-v0')
learning_rate = 0.0001
episodes = 10000
def discount_rewards(reward, gamma = 0.99):
return torch.pow(gamma, torch.arange(len(reward)))*reward
def normalize_rewards(disc_reward):
return disc_reward/(disc_reward.max())
class NeuralNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(NeuralNetwork, self).__init__()
self.state_size = state_size
self.action_size = action_size
self.linear_relu_stack = nn.Sequential(
nn.Linear(state_size, 300),
nn.ReLU(),
nn.Linear(300, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, action_size),
nn.Softmax()
)
def forward(self,x):
x = self.linear_relu_stack(x)
return x
model = NeuralNetwork(env.observation_space.shape[0], env.action_space.n)
opt = torch.optim.Adam(params = model.parameters(), lr = learning_rate)
score = []
for i in range(episodes):
print("i = ", i)
state = env.reset()
done = False
transitions = []
tot_rewards = 0
while not done:
act_proba = model(torch.from_numpy(state))
action = np.random.choice(np.array([0,1]), p = act_proba.data.numpy())
next_state, reward, done, info = env.step(action)
tot_rewards += 1
transitions.append((state, action, tot_rewards))
state = next_state
if i%50==0:
print("i = ", i, ",reward = ", tot_rewards)
score.append(tot_rewards)
reward_batch = torch.Tensor([r for (s,a,r) in transitions])
disc_rewards = discount_rewards(reward_batch)
nrml_disc_rewards = normalize_rewards(disc_rewards)
state_batch = torch.Tensor([s for (s,a,r) in transitions])
action_batch = torch.Tensor([a for (s,a,r) in transitions])
pred_batch = model(state_batch)
prob_batch = pred_batch.gather(dim=1, index=action_batch.long().view(-1, 1)).squeeze()
loss = -(torch.sum(torch.log(prob_batch)*nrml_disc_rewards))
opt.zero_grad()
loss.backward()
opt.step()回答 1
Stack Overflow用户
回答已采纳
发布于 2022-10-27 01:05:00
你计算的折扣奖励是你的错误所在。
在增强(和许多其他算法)中,您需要计算未来折扣报酬的和的每一步。
这意味着,第一步的折扣奖励的总和应是:
G_1 = r_1 + gamma * r_2 + gamma ^ 2 * r_3 + ... + gamma ^ (T-1) * r_T
G_2 = r_2 + gamma * r_3 + gamma ^ 2 * r_4 + ... + gamma ^ (T-1) * r_T
等等..。
这将为您提供一个数组,该数组包含每个步骤(即[G_1, G_2, G_3, ... , G_T])的所有未来奖励之和。
但是,您目前计算的只是对当前步骤的奖励应用折扣:
G_1 = r_1
G_2 = gamma * r_2
G_3 = gamma ^ 2 * r_3
等等..。
下面是解决您的问题的Python代码。我们从奖励列表的后面计算到前面,这样计算效率更高。
def discount_rewards(reward, gamma=0.99):
R = 0
returns = []
reward = reward.tolist()
for r in reward[::-1]:
R = r + gamma * R
returns.append(R)
returns = torch.tensor(returns[::-1])
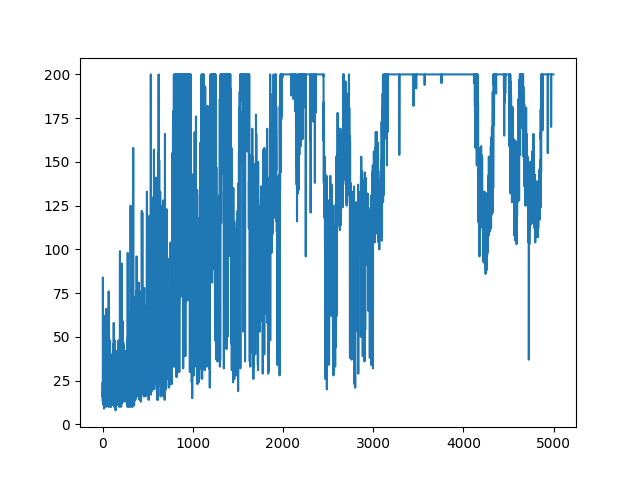
return returns这是一个图表,显示了算法得分在前5000步中的进展情况。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74214034
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号