
从电子邮件中解析数据--我需要提取未知数量的元素的最佳解决方案
我还在Power Automate社区论坛上提出了这个问题,希望能找到我的问题的最佳解决方案,即使我没有得到一个明确的答案,我也很乐意就如何克服我的问题提出任何建议。
我目前有一个Power,它包括将电子邮件的正文转换为文本(HTML到文本),将文本转换为一行,然后使用数组中的对应行提取相关的值。然后将提取的值添加到Excel表中,每次都添加一个新行。例如,电子邮件可能包含:
名称:全称Name1
年龄: 20岁
地点:南部
名称: FullName2
年龄: 21岁
地点:北
转换为数组的如下所示:
1名:
2全Name1
3岁
4. 20
5地点:
6南方
7姓名:
8全Name2
9岁
10 21
11地点:
12北
从上述电子邮件中提取的值为2.4.6.8.10和12。
我遇到的问题是,电子邮件可能只包含一组数据,或者可能包含10组数据--在只接收一组数据的情况下,当前数组将无法运行或记录来自不相关行的不必要值。或者在另一边,如果接收到了2组以上的数据,则不能考虑第14行和第14行以后的数据。每封电子邮件的格式总是相同的,但是文本的数量,因此所需的数据量和行数都会因电子邮件的不同而有所不同。这是由于我操纵一个电子邮件发送从外部来源,我没有权力限制一组数据,每个电子邮件等。
显然,我的做法是不正确的,似乎试图创建一个数组的未知数量的元素,可以不同的电子邮件,但我希望任何人指导我正确的路线,如何管理这个问题。
回答 1
Stack Overflow用户
发布于 2022-10-27 10:52:09
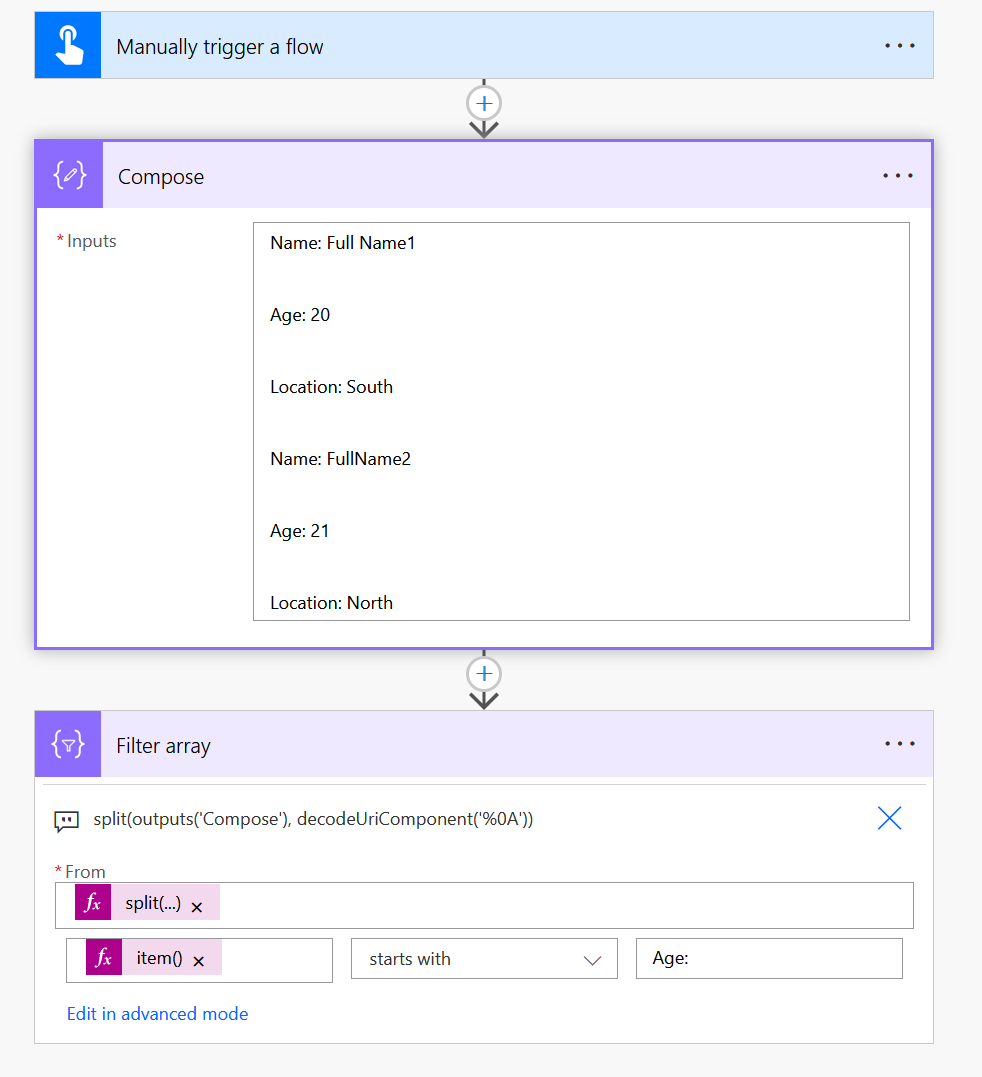
我会用新的行字符(0A)来分割文本。之后,您可以在筛选器数组操作中对以年龄:开始的项进行检查。
下面是一个例子
split(outputs('Compose'), decodeUriComponent('%0A'))在你可以使用的地方
item()从年龄开始:
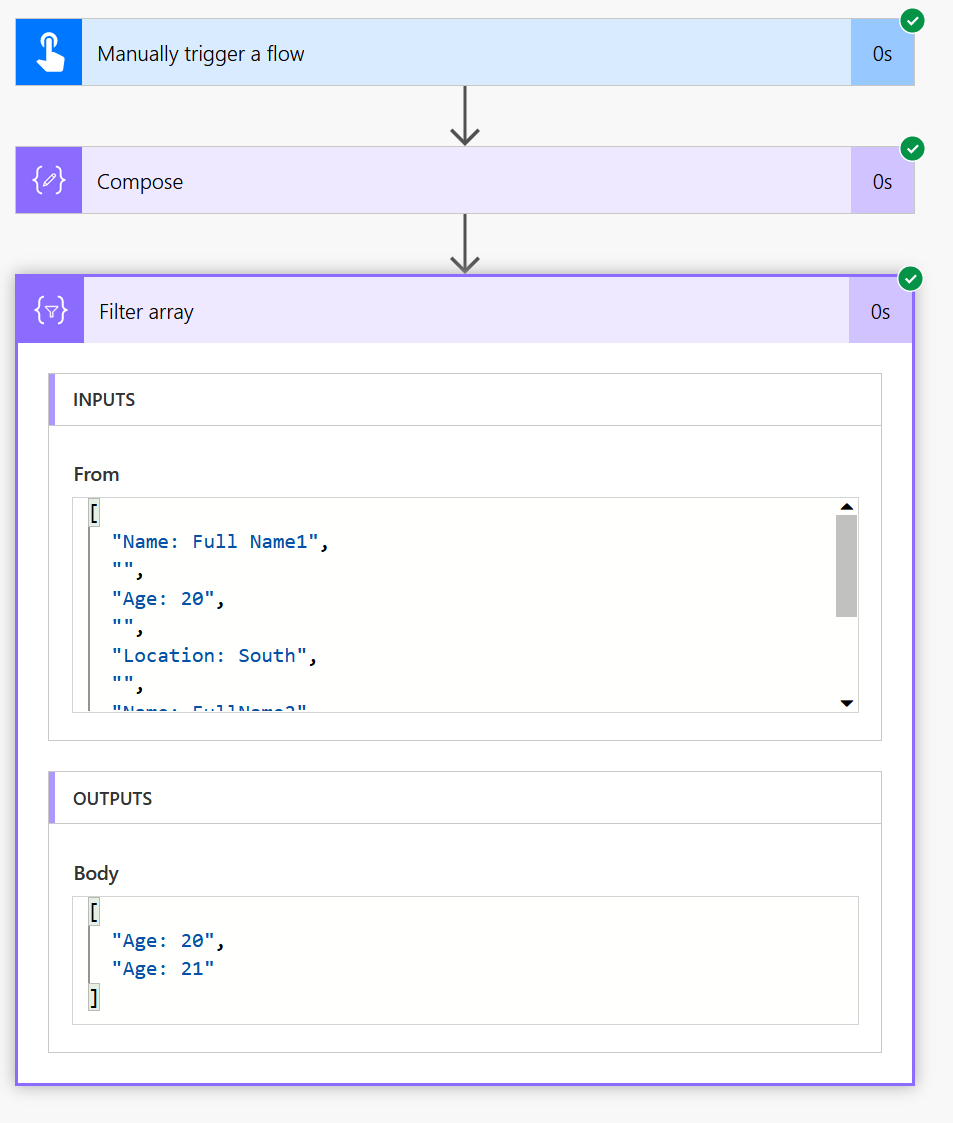
这将是测试运行的输出:
https://stackoverflow.com/questions/74212600
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号