
KEGG药品数据库Python脚本
KEGG药品数据库Python脚本
提问于 2022-10-25 06:30:23
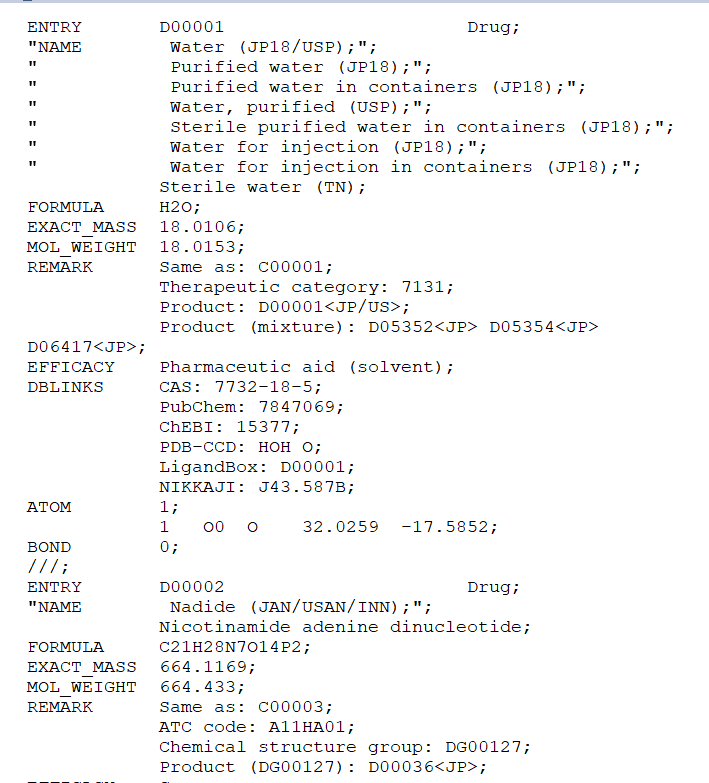
我有一个药物数据库保存在CSV文件中的一个列中,我可以用Pandas读取。该文件包含750000行,其元素由“/”分隔。该列还以“/”结尾。似乎每一行都以";“结尾。
为了创建结构化数据库,我希望将其拆分为多个列。大写词(药物信息)如“条目”、“名称”等将是这些新列的标题。
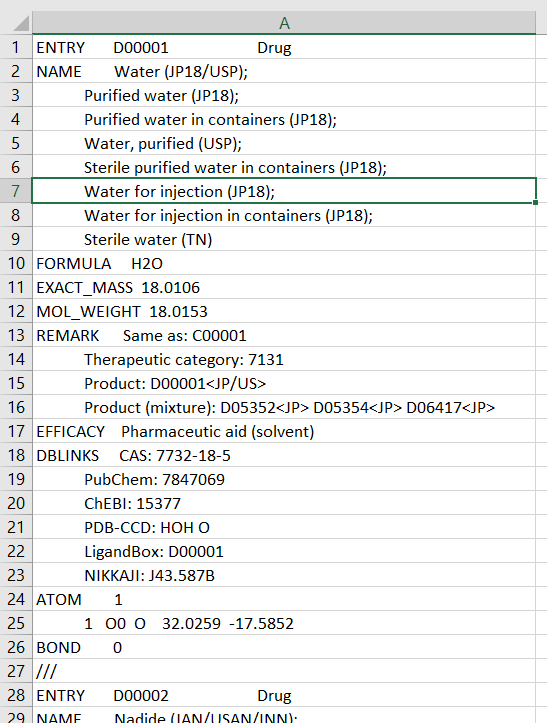
因此,它有一定的结构,虽然元素可以用不同的数量和信息来描述。这意味着某些元素在某些单元格中只会有NaN。我从未使用过类似SQL的格式,也很难将其复制为Pandas代码。请参阅PrtScs以获得更多信息。
所需输出的示例如下所示:
df = pd.DataFrame({
"ENTRY":["001", "002", "003"],
"NAME":["water", "ibuprofen", "paralen"],
"FORMULA":["H2O","C5H16O85", "C14H24O8"],
"COMPONENT":[NaN, NaN, "paracetamol"]})我猜会有基于大写单词的.split()吗?最好使用Python 3代码解决方案。它能帮助很多人。谢谢!
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-10-26 10:06:18
尽他所能,他帮助了:
import pandas as pd
cols = ['ENTRY', 'NAME', 'FORMULA', 'COMPONENT']
# We create an additional dataframe.
dfi = pd.DataFrame()
# We read the file, get two columns and leave only the necessary lines.
df = pd.read_fwf(r'drug', header=None, names=['Key', 'Value'])
df = df[df['Key'].isin(cols)]
# To "flip" the dataframe, we first prepare an additional column
# with indexing by groups from one 'ENTRY' row to another.
dfi['Key1'] = dfi['Key'] = df[(df['Key'] == 'ENTRY')].index
dfi = dfi.set_index('Key1')
df = df.join(dfi, lsuffix='_caller', rsuffix='_other')
df.fillna(method="ffill", inplace=True)
df = df.astype({"Key_other": "Int64"})
# Change the shape of the table.
df = df.pivot(index='Key_other', columns='Key_caller', values='Value')
df = df.reindex(columns=cols)
# We clean up the resulting dataframe a little.
df['ENTRY'] = df['ENTRY'].str.split(r'\s+', expand=True)[0]
df.reset_index(drop=True, inplace=True)
pd.set_option('display.max_columns', 10)小代码重构:
import pandas as pd
cols = ['ENTRY', 'NAME', 'FORMULA', 'COMPONENT']
# We read the file, get two columns and leave only the necessary lines.
df = pd.read_fwf(r'C:\Users\ф\drug\drug', header=None, names=['Key', 'Value'])
df = df[df['Key'].isin(cols)]
# To "flip" the dataframe, we first prepare an additional column
# with indexing by groups from one 'ENTRY' row to another.
df['Key_other'] = None
df.loc[(df['Key'] == 'ENTRY'), 'Key_other'] = df[(df['Key'] == 'ENTRY')].index
df['Key_other'].fillna(method="ffill", inplace=True)
# Change the shape of the table.
df = df.pivot(index='Key_other', columns='Key', values='Value')
df = df.reindex(columns=cols)
# We clean up the resulting dataframe a little.
df['ENTRY'] = df['ENTRY'].str.split(r'\s+', expand=True)[0]
df['NAME'] = df['NAME'].str.split(r'\(', expand=True)[0]
df.reset_index(drop=True, inplace=True)
pd.set_option('display.max_columns', 10)
print(df)
Key ENTRY NAME FORMULA \
0 D00001 Water H2O
1 D00002 Nadide C21H28N7O14P2
2 D00003 Oxygen O2
3 D00004 Carbon dioxide CO2
4 D00005 Flavin adenine dinucleotide C27H33N9O15P2
... ... ... ...
11983 D12452 Fostroxacitabine bralpamide hydrochloride C22H30BrN4O8P. HCl
11984 D12453 Guretolimod C24H34F3N5O4
11985 D12454 Icenticaftor C12H13F6N3O3
11986 D12455 Lirafugratinib C28H24FN7O2
11987 D12456 Lirafugratinib hydrochloride C28H24FN7O2. HCl
Key COMPONENT
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
... ...
11983 NaN
11984 NaN
11985 NaN
11986 NaN
11987 NaN
[11988 rows x 4 columns]需要更多的回忆,我把它留给你去做。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74189879
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号