
将熊猫的数据重新安排到引文网络
将熊猫的数据重新安排到引文网络
提问于 2022-10-19 14:18:45
编辑:
让我们把故事尽可能简单地说出来。我在熊猫工作。
我的数据是引用其他节点(docdb_id)的节点(cited_patents)。在这种情况下,ddocdb_id中节点的距离为min(Dist_cited_patents)+1,距离为0的节点被认为具有字段!=“”。我想构造一个名为New_var的变量。在这种情况下,逻辑很简单,因为New_var应该以最小的距离接受Cited_patents的值,如Dist_cited_patents所示。因此,在我们的示例中,原始df是:
docdb_id Cited_patents Dist_cited_patents Fields.
1 [7,3] [1,1] ""
2 [1,5] [2,1] ['Math']
3 [1,2,6] [2,0,2] ""
4 [7] [1] ['1. Natural Sciences' '3. Medical and Health Sciences']
5 [1,2] [2,0] ""
6 [5,8] [1,1] ""
7 [4,8] [0,1] ""
8 [4] [0] "" 预期结果是:
docdb_id Cited_patents Dist_cited_patents Fields New_var
1 [7,3] [1,1] "" [Natural Sciences, Medical and Health Sciences, Math]
2 [1,5] [2,1] ['Math'] Math
3 [1,2,6] [2,0,2] "" Math
4 [7] [1] ['1. Natural Sciences' '3. Medical and Health Sciences'] Natural Sciences, Medical and Health Sciences,
5 [1,2] [2,0] "" Math
6 [5,8] [1,1] "" [Natural Sciences, Medical and Health Sciences,, Math]
7 [4,8] [0,1] "" Science
8 [4] [0] "" Science数据提供如下:
# initialize list of lists
data = [[1, [7,3], [1,1], ""], [2, [1,5], [2,1], "Math"], [3, [1,2,6], [2,0,2], ""],[4, [7], [1], "Science"],[5, [1,2], [2,0], ""],[6, [5,8], [1,1], ""],[7, [4,8], [0,1], ""],[8, [4], [0], ""]]
# Create the pandas DataFrame
df = pd.DataFrame(data, columns=['docdb', 'cited_patents','dist_cited_patents','Fields'])谢谢!
回答 1
Stack Overflow用户
发布于 2022-10-19 15:07:28
这可以看作是一个图形问题,您可以用networkx来解决它。
# identify terminal nodes (leafs)
m = df['Fields'].eq('')
leafs = set(df.loc[~m, 'docdb'])
# {2, 4}
# generate exploded version of DataFrame to be able to construct the graph
df2 = df.explode(['cited_patents', 'dist_cited_patents'])
# build the directed graph with weights
import networkx as nx
G = nx.from_pandas_edgelist(df2.rename(columns={'dist_cited_patents': 'weight'}),
source='docdb', target='cited_patents',
edge_attr='weight',
create_using=nx.DiGraph)
# find closest leaf for each node
def distance(n, leaf):
try:
return nx.dijkstra_path_length(G, n, leaf, weight='weight')
except nx.NetworkXNoPath:
return float('inf')
mapper = {n: min(leafs, key=lambda leaf: distance(n, leaf)) for n in G.nodes}
# map leaf to field
fields = df[~m].set_index('docdb')['Fields']
# map each node to terminal leafs to field
df['New_var'] = df2['cited_patents'].map(mapper).map(fields).groupby(level=0).agg(set)
print(df)产出:
docdb cited_patents dist_cited_patents Fields New_var
0 1 [7, 3] [1, 1] {Science, Math}
1 2 [1, 5] [2, 1] Math {Math}
2 3 [1, 2, 6] [2, 0, 2] {Math}
3 4 [7] [1] Science {Science}
4 5 [1, 2] [2, 0] {Math}
5 6 [5, 8] [1, 1] {Science, Math}
6 7 [4, 8] [0, 1] {Science}
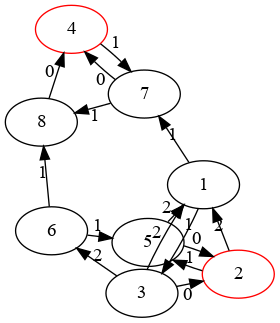
7 8 [4] [0] {Science}图表:
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74127008
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号