
连接表与PostgreSQL中的许多列和数组:内存和性能
我正在为一个产品搜索建立一个Postgres数据库(多达300万种产品),每种产品都有大量相似的数据,例如不同国家的价格,以及不同国家的平均评级,多达170个国家。
自然解决方案似乎使用数组(例如,价格为real[]列,评级为另一列)。但是,需要为每个国家的数据分别编制索引,以便进行排序和范围查询(不同国家的数据并不可靠地相互关联)。因此,在这一讨论上,我认为最好为每个国家使用单独的专栏。
大约有8个国家特有的属性,其中可能有4个需要索引,所以我可能会有超过1300列和650索引。这可能是个问题吗?有没有更好的解决办法?
编辑之后,每个人都告诉我许多到许多关系,正常化,等等:
我不相信。如果我的理解是正确的,这总是归结为一个 连接表 (很多名字都知道),就像Erwin的答案一样。
正如我在第一条评论中提到的,如果每个产品的价格和评级只适用于少数几个国家,这将是一个很好的解决方案。然而,如果不是这样的话,连接表可能会导致更高的内存需求(考虑经常重复的产品-id和country-id,甚至更严重的是,用于数亿行的窄表的行开销 )。
这里有一个Python脚本来演示这一点。它为不同国家的产品的价格和评级创建了一个连接表product_country,并为相同的产品创建了一个“多列表”products。表中包含了100,000种产品和100个国家的随机值。
为了简单起见,我使用int来识别产品和国家,对于连接表方法,我只构建连接表。
import psycopg2
from psycopg2.extras import execute_values
from random import random
from time import time
cn = psycopg2.connect(...)
cn.autocommit = True
cr = cn.cursor()
num_countries = 100
num_products = 100000
def junction_table():
print("JUNCTION TABLE")
cr.execute("CREATE TABLE product_country (product_id int, country_id int, "
"price real, rating real, PRIMARY KEY (product_id, country_id))")
t = time()
for p in range(num_products):
# use batch-insert, without that it would be about 10 times slower
execute_values(cr, "INSERT INTO product_country "
"(product_id, country_id, price, rating) VALUES %s",
[[p, c, random() * 100, random() * 5]
for c in range(num_countries)])
print(f"Insert data took {int(time() - t)}s")
t = time()
cr.execute("CREATE INDEX i_price ON product_country (country_id, price)")
cr.execute("CREATE INDEX i_rating ON product_country (country_id, rating)")
print(f"Creating indexes took {int(time() - t)}s")
sizes('product_country')
def many_column_table():
print("\nMANY-COLUMN TABLE")
cr.execute("CREATE TABLE products (product_id int PRIMARY KEY, "
+ ', '.join([f'price_{i} real' for i in range(num_countries)]) + ', '
+ ', '.join([f'rating_{i} real' for i in range(num_countries)]) + ')')
t = time()
for p in range(num_products):
cr.execute("INSERT INTO products (product_id, "
+ ", ".join([f'price_{i}' for i in range(num_countries)]) + ', '
+ ", ".join([f'rating_{i}' for i in range(num_countries)]) + ') '
+ "VALUES (" + ",".join(["%s"] * (1 + 2 * num_countries)) + ') ',
[p] + [random() * 100 for i in range(num_countries)]
+ [random() * 5 for i in range(num_countries)])
print(f"Insert data took {int(time() - t)}s")
t = time()
for i in range(num_countries):
cr.execute(f"CREATE INDEX i_price_{i} ON products (price_{i})")
cr.execute(f"CREATE INDEX i_rating_{i} ON products (rating_{i})")
print(f"Creating indexes took {int(time() - t)}s")
sizes('products')
def sizes(table_name):
cr.execute(f"SELECT pg_size_pretty(pg_relation_size('{table_name}'))")
print("Table size: " + cr.fetchone()[0])
cr.execute(f"SELECT pg_size_pretty(pg_indexes_size('{table_name}'))")
print("Indexes size: " + cr.fetchone()[0])
if __name__ == '__main__':
junction_table()
many_column_table()输出:
JUNCTION TABLE
Insert data took 179s
Creating indexes took 28s
Table size: 422 MB
Indexes size: 642 MB
MANY-COLUMN TABLE
Insert data took 138s
Creating indexes took 31s
Table size: 87 MB
Indexes size: 433 MB最重要的是,连接表的总大小(table+indexes)大约是多列表的两倍,而仅表的大小甚至是多列表的近5倍。
这很容易由行开销以及每行中重复的product和country-id (10,000,000行,而多列表中只有100,000行)来解释。
大小与产品数量(我用70万个产品进行了测试)近似线性,因此对于300万产品,连接表大约为32 GB (12.7GB关系+19.2GB索引),而多列表仅为15.6 GB (2.6 GB表+ 13 GB索引),而是决定一切是否应该缓存在RAM中的表。
当所有数据都被缓存时,查询时间大致相同,这里是70万个产品的典型示例:
EXPLAIN (ANALYZE, BUFFERS)
SELECT product_id, price, rating FROM product_country
WHERE country_id=7 and price < 10
ORDER BY rating DESC LIMIT 200
-- Limit (cost=0.57..1057.93 rows=200 width=12) (actual time=0.037..2.250 rows=200 loops=1)
-- Buffers: shared hit=2087
-- -> Index Scan Backward using i_rating on product_country (cost=0.57..394101.22 rows=74544 width=12) (actual time=0.036..2.229 rows=200 loops=1)
-- Index Cond: (country_id = 7)
-- Filter: (price < '10'::double precision)
-- Rows Removed by Filter: 1871
-- Buffers: shared hit=2087
-- Planning Time: 0.111 ms
-- Execution Time: 2.364 msEXPLAIN (ANALYZE, BUFFERS)
SELECT product_id, price_7, rating_7 FROM products
WHERE price_7 < 10
ORDER BY rating_7 DESC LIMIT 200
-- Limit (cost=0.42..256.82 rows=200 width=12) (actual time=0.023..2.007 rows=200 loops=1)
-- Buffers: shared hit=1949
-- -> Index Scan Backward using i_rating_7 on products (cost=0.42..91950.43 rows=71726 width=12) (actual time=0.022..1.986 rows=200 loops=1)
-- Filter: (price_7 < '10'::double precision)
-- Rows Removed by Filter: 1736
-- Buffers: shared hit=1949
-- Planning Time: 0.672 ms
-- Execution Time: 2.265 ms在灵活性、数据完整性等方面,我认为多列方法没有严重问题:我可以轻松地为国家添加和删除列,如果对列使用合理的命名方案,那么应该很容易避免错误。
,所以我想我完全有理由不使用连接表.
此外,与许多列相比,使用数组更清晰、更简单,而且如果有一种方法可以轻松地为数组元素定义单个索引,那么这将是最好的解决方案(甚至可以减少总索引的大小?)。
,所以我认为我最初的问题仍然有效。但是,还有很多需要考虑和测试的地方。而且,我绝不是数据库专家,所以如果我错了就告诉我。
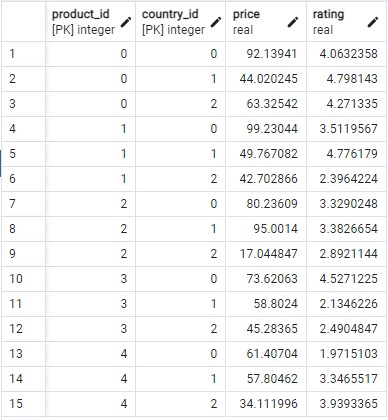
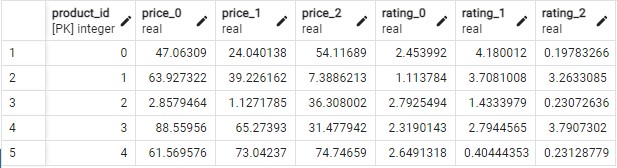
在这里,来自5个产品和3个国家的脚本的测试表:
回答 1
Stack Overflow用户
发布于 2022-10-17 21:32:04
关系数据库的“自然”解决方案是在一对多或多到多的关系中创建额外的表。调查数据库规范化。
每个国家产品评级的基本m:n设计:
CREATE TABLE country (
country_id varchar(2) PRIMARY KEY
, country text UNIQUE NOT NULL
);
CREATE TABLE product (
product_id int GENERATED ALWAYS AS IDENTITY PRIMARY KEY
, product text NOT NULL
-- more?
);
CREATE TABLE product_ratings (
product_id int REFERENCES product
, country_id varchar(2) REFERENCES country
, rating1 real
, rating2 real
-- more?
, PRIMARY KEY (product_id, country_id)
);更多详细信息:
https://stackoverflow.com/questions/74103128
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号