
如何在显示匹配项的列表和未找到的元素之间进行模糊搜索?
我试图对列表to_search中的值进行模糊匹配。在to_search列表中搜索choices列表中的每个值,并从result列表中显示相应的项。就像一个MS,但是带有模糊搜索。
这是我当前的代码,它几乎为不同的值打印正确的输出,但是对于在to_search中没有任何相似性的值,我想在output Not Found中显示,但是现在我得到了一些其他的输出。
我要搜索的是前缀,这个顺序是一样的。例如,值38050与此匹配的('358', 72.0, 8)一起出现,因为在38050中有3、5和8,但对我来说没有兴趣,因为3、5和8的顺序不同。如果找到的选择是380 in,至少在前缀上与38050有相似之处,这将是我的匹配。希望你能理解我的解释。
from rapidfuzz import process, fuzz
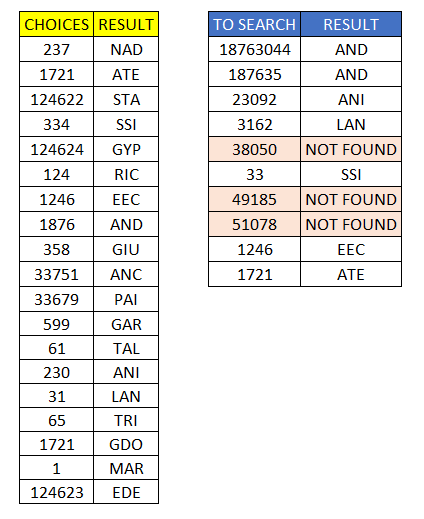
choices = [
'237','1721','124622','334','124624','124','1246','1876','358',
'33751','33679','599','61','230','31','65','1721','1','124623'
]
result = [
'NAD','ATE','STA','SSI','GYP','RIC','EEC','AND','GIU','ANC',
'PAI','GAR','TAL','ANI','LAN','TRI','GDO','MAR','EDE'
]
to_search = ['18763044','187635','23092','3162','38050','33','49185','51078','1246','1721']
for element in to_search:
match = process.extractOne(element, choices, scorer=fuzz.WRatio)
print(element,result[match[2]],' ## ',match)电流输出
>>>
18763044 AND ## ('1876', 90.0, 7)
187635 AND ## ('1876', 90.0, 7)
23092 ANI ## ('230', 90.0, 13)
3162 LAN ## ('31', 90.0, 14)
38050 GIU ## ('358', 72.0, 8) // This should be marked as NOT FOUND
33 SSI ## ('334', 90.0, 3)
49185 MAR ## ('1', 90.0, 17) // This should be marked as NOT FOUND
51078 MAR ## ('1', 90.0, 17) // This should be marked as NOT FOUND
1246 EEC ## ('1246', 100.0, 6)
1721 ATE ## ('1721', 100.0, 1)我想得到的输出:
18763044 AND
187635 AND
23092 ANI
3162 LAN
38050 NOT FOUND
33 SSI
49185 NOT FOUND
51078 NOT FOUND
1246 EEC
1721 ATE表格格式,便于理解输入和输出。提前感谢
回答 2
Stack Overflow用户
发布于 2022-10-17 09:48:17
你可以创造你自己的记分员:
def my_scorer(query,choice,**kwargs):
# default score
score=fuzz.WRatio(query,choice)
is_prefix=False
# if choice is a prefix of query
if choice in query and query.index(choice)==0:
is_prefix=True
# if query is a prefix of choice
if query in choice and choice.index(query)==0:
is_prefix=True
if not is_prefix:
score=-1
return score并将其传递给process.extractOne和score_cutoff=0,以忽略分数低于0的结果
match = process.extractOne(element, choices, scorer=my_scorer, score_cutoff=0)
if match:
print(element, result[match[2]])
else:
print(element, 'NOT FOUND')Stack Overflow用户
发布于 2022-10-17 08:21:21
您可以选择一个比WRatio更考虑订单的记分员。然后设置score_cutoff以排除低于给定相似性的结果。
就您的例子而言,fuzz.ratio和score_cutoff=60似乎有效。您必须在更大的数据集上进行测试,并尝试不同的评分器来确切地了解您需要的是什么:
from rapidfuzz import process, fuzz
choices = [
'237','1721','124622','334','124624','124','1246','1876','358',
'33751','33679','599','61','230','31','65','1721','1','124623'
]
result = [
'NAD','ATE','STA','SSI','GYP','RIC','EEC','AND','GIU','ANC',
'PAI','GAR','TAL','ANI','LAN','TRI','GDO','MAR','EDE'
]
to_search = ['18763044','187635','23092','3162','38050','33','49185','51078','1246','1721']
for element in to_search:
match = process.extractOne(element, choices, scorer=fuzz.ratio, score_cutoff=60)
if match:
print(element,result[match[2]],' ## ',match)
else:
print(element,"NOT FOUND")输出:
18763044 AND ## ('1876', 66.66666666666667, 7)
187635 AND ## ('1876', 80.0, 7)
23092 ANI ## ('230', 75.0, 13)
3162 LAN ## ('31', 66.66666666666667, 14)
38050 NOT FOUND
33 SSI ## ('334', 80.0, 3)
49185 NOT FOUND
51078 NOT FOUND
1246 EEC ## ('1246', 100.0, 6)
1721 ATE ## ('1721', 100.0, 1)https://stackoverflow.com/questions/74093719
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号