
数据结构
数据结构
提问于 2022-10-12 15:06:35
我有一个数据框架,其中包含了一长串条目。
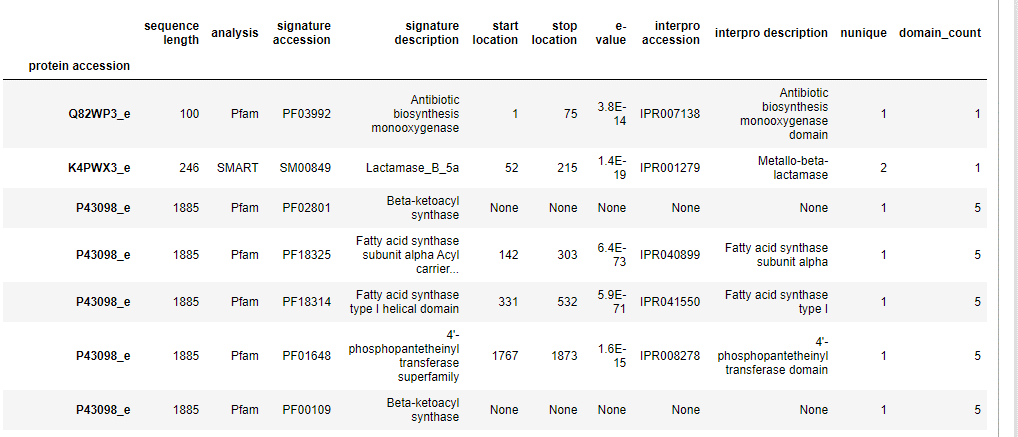
我用蛋白质登录号给他们编了索引。问题是,它们是重复的,因为有些蛋白质由多个结构域组成。我想让蛋白质的加入号成为主要条目(并且它有多少个域的信息- domain_count)和这些蛋白质的结构域是子条目。例如,当我键入:
df_filtered.loc['P43098_e', 'domain_count']它返回每个域的数字5 (5次)。我希望它只打印5次,因为P43098_e将是直接分配有关domain_count信息的主要条目。有人能帮帮我吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-10-12 15:17:10
这就是你要找的吗?
如果您将数据作为代码共享,我也将能够获得结果
df_filtered.loc[df_filtered['protein_accession'] == 'P43098_e', 'domain_count'][:1].values[0](df_filtered.loc[df_filtered['protein_accession'] == 'P43098_e', 'domain_count']
.head(1)
.squeeze())或
(df_filtered[df_filtered['protein_accession'] == 'P43098_e']['domain_count']
.head(1)
.squeeze())或
要么您需要在reset_index()上运行df_fitered解决方案,要么在语句中添加reset_filtered,如下所示
(df_filtered.reset_index()[df_filtered.reset_index()['protein_accession'] == 'P43098_e']['domain_count']
.head(1)
.squeeze())页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74044138
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号