
只需要根据当前月份使用使用databricks的火星雨增量负载来更新数量
只需要根据当前月份使用使用databricks的火星雨增量负载来更新数量
提问于 2022-10-11 16:46:11
我正在将增量表加载到S3增量湖中。表模式为product_code、date、quantity、crt_dt。
我将获得6个月的预测数据,例如,如果这个月是2022年5月,我将获得5月、6月、7月、8月、9月、10月的数量数据。我现在面临的问题是数据每个月都会被复制。我只希望根据最近的crt_dt在delta表中只有一行,如下面的屏幕截图所示。有人能帮我解决我应该实现的问题吗?
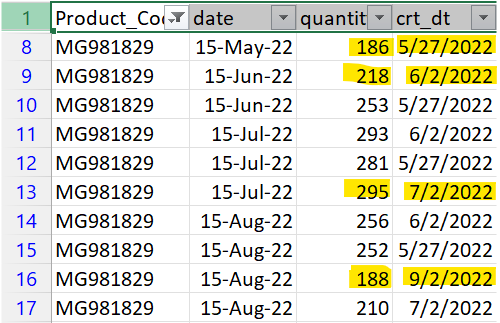
数据由crt_dt进行分区。
谢谢!
回答 2
Stack Overflow用户
发布于 2022-10-11 19:06:04
如果您想正常地获得最近的crt_dt,这段代码就能做到这一点
w3 = Window.partitionBy("product_cat").orderBy(col("crt_dt").desc())
df.withColumn("row",row_number().over(w3)) \
.filter(col("row") == 1).drop("row") \
.show()有关更多详细信息,请查看此https://sparkbyexamples.com/pyspark/pyspark-select-first-row-of-each-group/
Stack Overflow用户
发布于 2022-10-14 19:56:25
您有一个数据集,您希望对其进行筛选,然后将其写入Delta表。
另一张海报告诉你如何过滤数据以满足你的要求。下面是如何过滤数据,然后写出数据。
filtered_df = df.withColumn("row",row_number().over(w3)) \
.filter(col("row") == 1).drop("row") \
.show()
filtered_df.write.format("delta").mode("append").save("path/to/delta_lake")如果您不使用Python,也可以使用SQL完成此操作。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74031506
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号