
加速算法熊猫
加速算法熊猫
提问于 2022-10-11 12:53:26
在谈到这个问题之前,我要解释一下我正在使用的算法。为此,假设我有如下数据:
# initialize list of lists
data = [[2, [4], None], [4, [9,18,6], None], [6, [], 9],[7, [2], None],[9, [4], 7],[14, [18,6], 3],[18, [7], 1]]
# Create a mock pandas DataFrame
df = pd.DataFrame(data, columns=['docdb', 'cited_docdb','frontier'])现在,我将定义一个距离度量,它是0,即边界变量不同于NaN。该算法基本上更新距离变量如下:
observation);
- Assign
- 查找变量cited_docdb中有一个distance=0的所有docdb (这是一个在cited_docdb;
- Assign中对它们的值为0的列表--与它们的cited_docdb
- Repeat中至少有一个0的距离-- distance=1,2,3、.、max_cited_docdb (被引用的最大数目)
)
该算法的工作原理如下:
df.replace(' NaN', np.NaN)
df['distance'] = np.where((df['fronteer'] >0), 0, np.nan)for k in range(max(max_cited_docdb)):
s=df.set_index('docdb')['distance'].dropna()[df.set_index('docdb')['distance'].dropna()>=k]
df['cited_docdb'] = [[s.get(i, i) for i in x] for x in df['cited_docdb']]
m=[k in x for x in df['cited_docdb']]
df.loc[m&df['distance'].isna(), 'distance'] = k+1现在,我的问题是我的原始数据库有300万个观测值,引用大多数其他docdb的docdb有9500个值(即最长的cited_docdb列表有9500个值)。因此,上面的算法非常慢。有什么方法可以加快速度(例如用dask来修改算法?)还是不想?
非常感谢
回答 1
Stack Overflow用户
发布于 2022-10-11 13:20:29
它看起来像一个图问题,您希望在docdb中的节点和固定的终端节点之间获得最短的距离(这里是NaN)。
您可以使用networkx来处理这个问题。
这是你的图表:
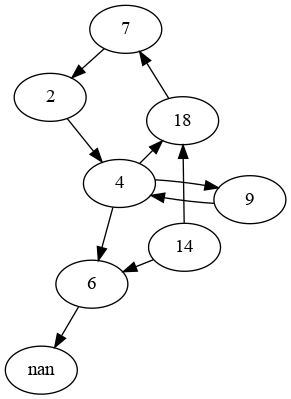
import networkx as nx
G = nx.from_pandas_edgelist(df.explode('cited_docdb'),
source='docdb', target='cited_docdb',
create_using=nx.DiGraph)
# get shortest path length (minus bounds = 2)
d = {n: len(nx.shortest_path(G, n, np.nan))-2
for n in df.loc[df['frontier'].isna(), 'docdb']}
# {2: 2, 4: 1, 7: 3}
# map values
df['distance'] = df['docdb'].map(d).fillna(0, downcast='infer')产出:
docdb cited_docdb frontier distance
0 2 [4] NaN 2
1 4 [9, 18, 6] NaN 1
2 6 [] 9.0 0
3 7 [2] NaN 3
4 9 [4] 7.0 0
5 14 [18, 6] 3.0 0
6 18 [7] 1.0 0页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/74028504
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号