
使用R中的tesseract识别图像中的特定字符?
使用R中的tesseract识别图像中的特定字符?
提问于 2022-10-07 17:54:12
我试图识别和删除心电图图像文件中的特定字符。在ECG中,出现的“单词”不是通常的英语单词,而是像"aVR“、"V5”、"II“这样的引号。下面是一个示例图像:
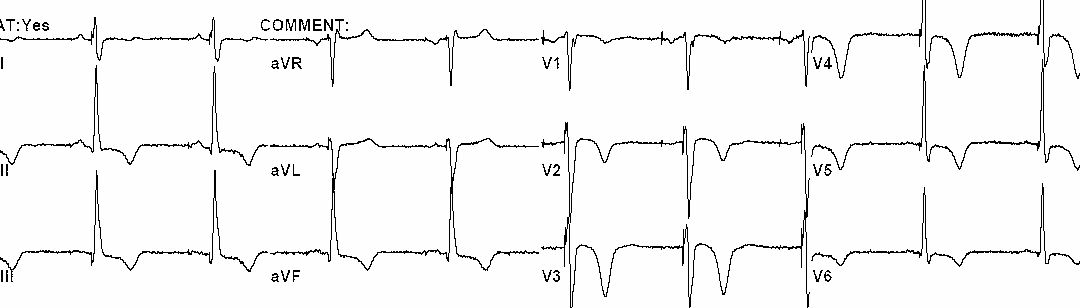
我试图使用R中的tesseract包来识别和删除这些图像中的所有字符/数字,以便只留下心电图线。这就是我尝试过的:
eng <- tesseract("eng")
ECG_signs1 <- tesseract(options = list(tessedit_char_whitelist = "V1V2V3V4V5V6aVRaVLaVF"))
ECG_signs2 <- tesseract(options = list(tessedit_char_whitelist = "V1"))
tes.data1 <- tesseract::ocr_data ("processing_image.png", engine = eng)
tes.data2 <- tesseract::ocr_data ("processing_image.png", engine = ECG_signs1)
tes.data3 <- tesseract::ocr_data ("processing_image.png", engine = ECG_signs2)但是产生的碎片没有行,即tesseract不会识别这些图像中的任何字符。
我不知道还能做什么,因为文字在图像中看起来非常清晰,对比度很高,噪音也很低。我很高兴使用任何其他为R提供的OCR图书馆,我非常感谢您的帮助。谢谢!
回答 1
Stack Overflow用户
发布于 2022-11-30 23:47:48
这些图像的特征:
- 我们想要保留的部分(心电图线)主要是水平连接的像素线。
- 我们想要擦除的部分(文本)是小的、孤立的像素块。
一个方法
- 使用
imager包获取图像中具有区域、宽度、高度、.小于某些阈值的
# --- Load packages
require( purrr )
require( imager )
require( tibble )
require( dplyr )
# --- Configure
cfg <- list(
DATA_PATH = 'path/to/image/files'
)
# --- Get an image for experimentation
im <- load.image( file.path( cfg$DATA_PATH, 'D6VDQ.png' ))
# --- Convert to gray scale
gs <- grayscale( im )
# --- Remove very light marks
px <- threshold( gs )
# --- Extract contours
ct <- contours( px, nlevels = 2 )
# ---------------------
# --- Utility functions
# ---------------------
gross_width <- function( i ){
( max( ct[[ i ]]$x ) - min( ct[[ i ]]$x ) )
}
gross_height <- function( i ){
( max( ct[[ i ]]$y ) - min( ct[[ i ]]$y ) )
}
# --- Calculate the overall width and height for each blob
widths <- seq( ct ) %>% map_dbl( gross_width ) %>% round( 0 )
heights <- seq( ct ) %>% map_dbl( gross_height ) %>% round( 0 )
# --- Consolidate the information about the blobs into one place
blobs <- tibble(
id = seq( ct )
, x = seq( ct ) %>% map( ~ct[[ .x ]]$x )
, y = seq( ct ) %>% map( ~ct[[ .x ]]$y )
, gross_width = widths
, gross_height = heights
, gross_area = widths * heights
)
# --- Try an arbitrary threshold to see what happens
cfg$MAX_WIDTH <- quantile( blobs$gross_width )[ 4 ] # Third quartile
cfg$MAX_HEIGHT <- quantile( blobs$gross_height )[ 4 ] # Third quartile
# --- A function to conditionally erase a blob
erase_small_blobs <- function( i ){
if( ( widths[[ i ]] <= cfg$MAX_WIDTH ) &
( heights[[ i ]] <= cfg$MAX_HEIGHT ) ){
color.at( im, ct[[ i ]]$x, ct[[ i ]]$y ) <<- c( 1, 1, 1 )
}
}
# --- Process all the blobs with the selective eraser
seq( ct ) %>%
walk( erase_small_blobs )
# --- Show the results
plot( im )
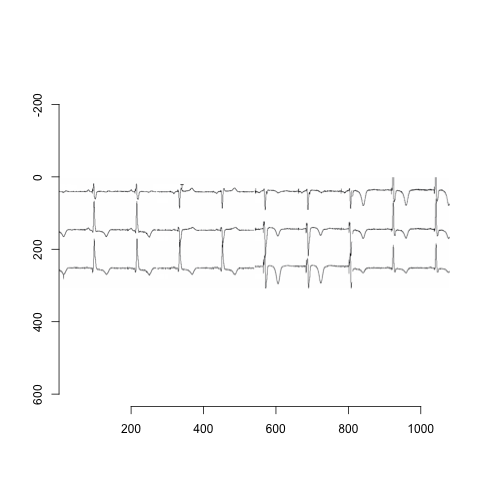
评估
这第一次尝试删除了所有的文本,除了在顶部跟踪的第三次心跳附近的一个'T‘,也许是因为它太接近跟踪,而不是它自己的blob。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73990939
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号