
如何使用光栅数据从交叉口生成sf空间数据
如何使用光栅数据从交叉口生成sf空间数据
提问于 2022-10-04 19:13:53
我有一个矢量型空间数据文件,用于一个给定城市的街道,另一个文件具有栅格型空间数据和地形坡度。
我的目标是跨越这两条数据,找出哪些地方有最陡峭的街道。
如果两者都是sf类型的数据,我将使用st_intersection函数。但是,当数据是不同的类型时,如何处理呢?
我的最终目标是以向量的形式生成空间数据,其中有一列表示该拉伸的斜率。
可复制的例子:
library(elevatr)
library(terra)
library(geobr)
library(osmdata) # package for working with streets
# 2 - get the municipality shapefile (vectorized spatial data)
municipality_shape <- read_municipality(code_muni = 3305802)
# 3 - get the raster topographical data
t <- elevatr::get_elev_raster(locations = municipality_shape,
z = 10, prj = "EPSG:4674")
obj_raster <- rast(t)
# 4 - calculate the slope
aspect <- terrain(obj_raster, "aspect", unit = "radians")
slope <- terrain(obj_raster, "slope", unit = "radians")
hillshade <- shade(slope, aspect)
# 5 - get the streets data
getbb("Teresópolis")
big_streets <- getbb("Teresópolis") |>
opq() |> # função que faz a query no OSM
add_osm_feature(key = "highway", # selecionar apenas ruas
value = "primary") |> # característica das ruas
osmdata_sf() # retorna a query como um objeto sf
# 6 - intersects the raster hillshade object with the sf object from streets available in big_streets$osm_lines$geometry.回答 1
Stack Overflow用户
回答已采纳
发布于 2022-10-04 20:22:49
如果您只想提取街道,那么将行字符串子集出来:
big_streets <- getbb("Teresópolis")%>%
opq()%>% # função que faz a query no OSM
add_osm_feature(key = "highway", # selecionar apenas ruas
value = "primary") %>% # característica das ruas
osmdata_sf() %>%
osm_poly2line() %>%
`[[`("osm_lines")现在,对于每条街道,使用extract获取与每个行字符串对应的数据。您需要对此进行平均值,以便每条街道都有一个平均值(但如果您愿意的话,也可以得到最大坡度)。
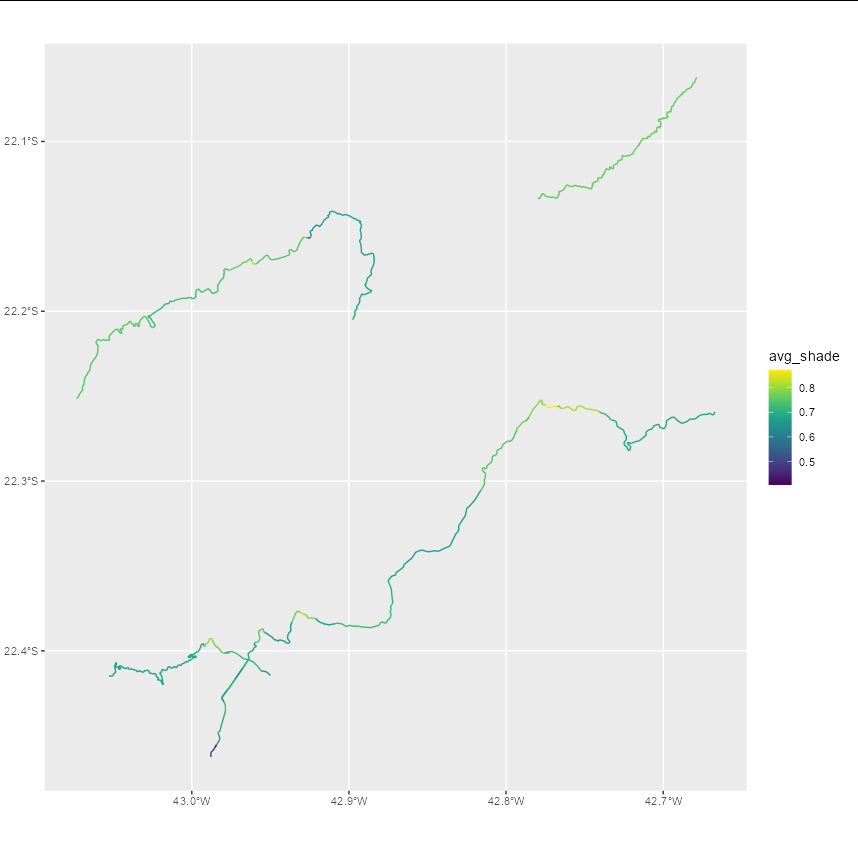
big_streets$avg_shade <- sapply(big_streets$geometry, function(x) {
mean(extract(hillshade, vect(x))[[2]])
})现在,big_streets有了一个额外的列,给出了每条街道上shade的平均值。我们可以看到这是什么样子:
ggplot(big_streets) + geom_sf(aes(color = avg_shade)) + scale_color_viridis()
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73952627
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号