
Python -迭代网站列表和刮取数据-在requests.get失败
我有一张从吉特布那里刮来的物品清单。这是位于df_actionname 'ActionName‘中的。然后,每个'ActionName‘都可以转换成一个'Weblink’来创建一个网站链接。我试图循环每一个网页链接和刮数据从它。
我的代码:
#Code to create input data
import pandas as pd
actionnameListFinal = ['TruffleHog OSS','Metrics embed','Super-Linter',]
df_actionname = pd.DataFrame(actionnameListFinal, columns = ['ActionName'])
# Create dataframes
df_actionname = pd.DataFrame(actionnameListFinal, columns = ['ActionName'])
#Create new column for parsed action names
df_actionname['Parsed'] = df_actionname['ActionName'].str.replace( r'[^A-Za-z0-9]+','-', regex = True)
df_actionname['Weblink'] = 'https://github.com/marketplace/actions/' + df_actionname['Parsed']
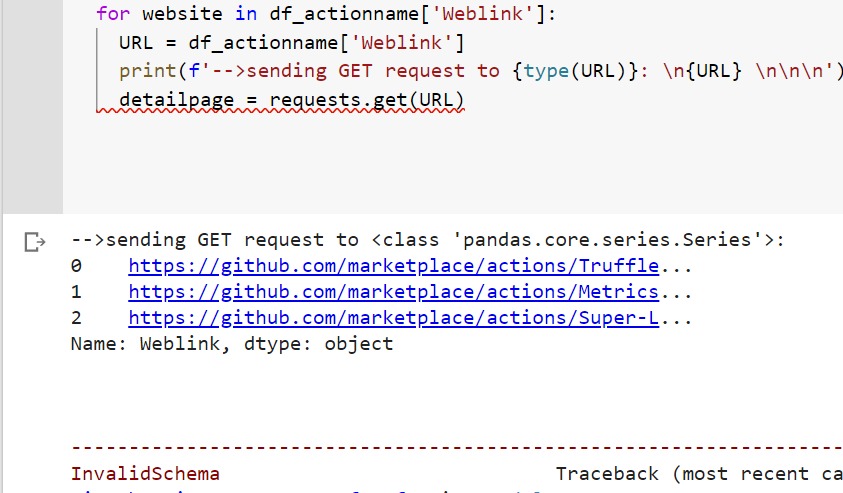
for website in df_actionname['Weblink']:
URL = df_actionname['Weblink']
detailpage = requests.get(URL)我的代码在“detailpage= requests.get(URL)”中失败,我收到的错误消息是:
在get_adapter InvalidSchema(f“未为{url!r}找到连接适配器”)中,requests.exceptions.InvalidSchema:没有为'0 https://github.com/marketplace/actions/Truffle...\n1 https://github.com/marketplace/actions/Metrics...\n2 https://github.com/marketplace/actions/Super-L...\n3 https://github.com/marketplace/actions/Swift-Doc\nName:Weblink,dtype: object‘找到连接适配器
回答 1
Stack Overflow用户
发布于 2022-10-02 20:48:20
您需要设置一个有效的url。将for循环更改为
# from bs4 import BeautifulSoup
for website in df_actionname['Weblink']:
detailpage = requests.get(website)
pageSoup = BeautifulSoup(detailpage.content, 'html.parser')
print(f'scraped "{pageSoup.title.text}" from {website}')给我输出
scraped "TruffleHog OSS · Actions · GitHub Marketplace · GitHub" from https://github.com/marketplace/actions/TruffleHog-OSS
scraped "Metrics embed · Actions · GitHub Marketplace · GitHub" from https://github.com/marketplace/actions/Metrics-embed
scraped "Super-Linter · Actions · GitHub Marketplace · GitHub" from https://github.com/marketplace/actions/Super-Linter您这样做的方式,不仅是您的代码基本上尝试重复发送相同的GET请求每个循环(因为URL根本不依赖于website ),requests.get的输入不是一个url,如果在请求之前添加print,您可以看到:
https://stackoverflow.com/questions/73920398
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号