
R中Pareto型2的参数估计
R中Pareto型2的参数估计
提问于 2022-09-30 18:59:01
我有一个连续变量,从0到1(百分比数据,包括0),我想确定最佳的分布来建模它。我上的是R-Studio,数据有问题的这里。请注意,大约27%的观测值为0,我计划在进行过程中探索零通货膨胀。
我检查了直方图和ecdf (见下文),以了解我正在处理的是什么。菲特弗勒斯给了我'beta',而gamlss给了我一个Pareto类型2,这我不是很熟悉。
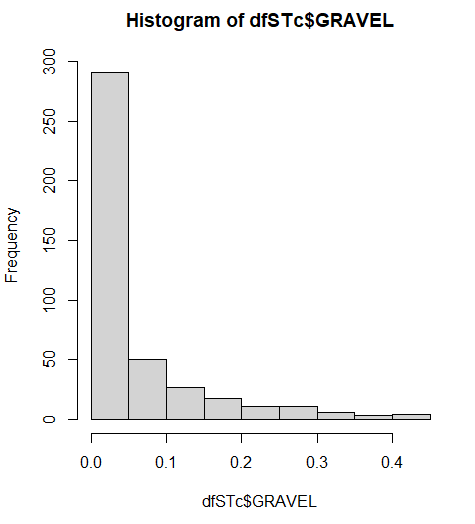
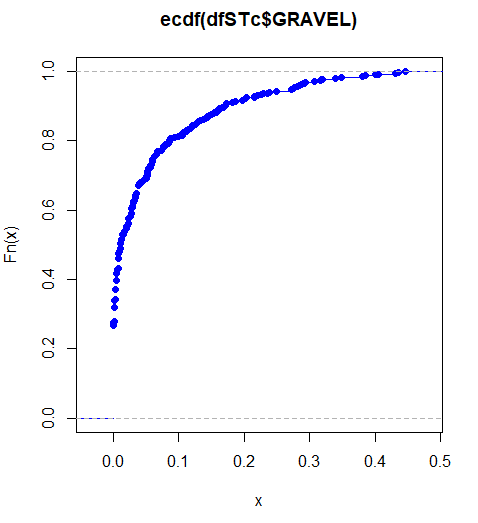
我已经确定了beta发行版的参数并对其进行了拟合,使用KS测试了其他几个发行版,但是问题是,我在估计位置和规模方面的所有缺陷都失败了。据我所知,这是因为数据集中的零。如果我在整个数据集中添加一个很小的数量(即0.0001),它就能工作,但老实说,我不确定这是一个好的解决方案,并且会将它与其他任何东西进行比较。我尝试了EnvStats、VGAM、CaDENCE,所有这些都给了我错误。因此,我谦卑地来到这里,希望有人能够提出另一个选项,用于估计该数据集的Pareto Type 2参数。
回答 1
Stack Overflow用户
发布于 2022-09-30 20:43:51
您可以考虑以下方法:
library(DEoptim)
df <- read.csv("percentData.csv")
data <- unlist(df)
log_Lik <- function(data, param)
{
x <- data
k <- param[1]
s <- param[2]
log_Lik <- sum(log(k/(s + x) * (s / (s + x)) ^ k))
return(-log_Lik)
}
obj_Res <- DEoptim(fn = log_Lik, lower = c(0, 0), upper = c(1000, 1000), data = data, control = list(parallelType = 1))
obj_Res$optim$bestmem页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73912980
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号