
在此代码中比较的是哪些组?
在此代码中比较的是哪些组?
提问于 2022-09-28 21:40:53
我在Stata进行了线性和logistic回归,并比较了不同种族/族裔群体之间的结果。这是我正在使用的用户定义编码的一个例子,我不明白每个变量(x1、x2、x3)要比较哪个组。有人能帮忙吗!!
x1 :生成x1= -.5如果种族== 1
替换x1 = .5如果竞争== 2
替换x1 = -1.5如果比赛== 3
替换x1 = 1.5如果争用== 4
x2 :生成x2= -1如果竞争== 1
替换x2 =1如果比赛== 2
替换x2 = -1如果比赛== 3
替换x2 =1如果比赛== 4
x3 :生成x3= 1.5如果比赛== 1
替换x3 = -.5如果竞争== 2
替换x3 = 1.5如果比赛== 3
替换x3 = -2.5如果比赛== 4
回答 1
Stack Overflow用户
发布于 2022-09-28 22:56:58
假设race的值为1 2 3 4,我们可以检查其影响:
clear
set obs 4
gen race = _n
generate x1 = -.5 if race == 1
replace x1 = .5 if race == 2
replace x1 = -1.5 if race == 3
replace x1 = 1.5 if race == 4
generate x2 = -1 if race == 1
replace x2 = 1 if race == 2
replace x2 = -1 if race == 3
replace x2 = 1 if race == 4
generate x3 = 1.5 if race == 1
replace x3 = -.5 if race == 2
replace x3 = 1.5 if race == 3
replace x3 = -2.5 if race == 4
reshape long x, i(race) j(which)
label define which 1 x1 2 x2 3 x3 4 x4
label val which which
twoway connected x race, by(which, note("") row(1)) yla(-2.5(0.5)1.5, ang(h))
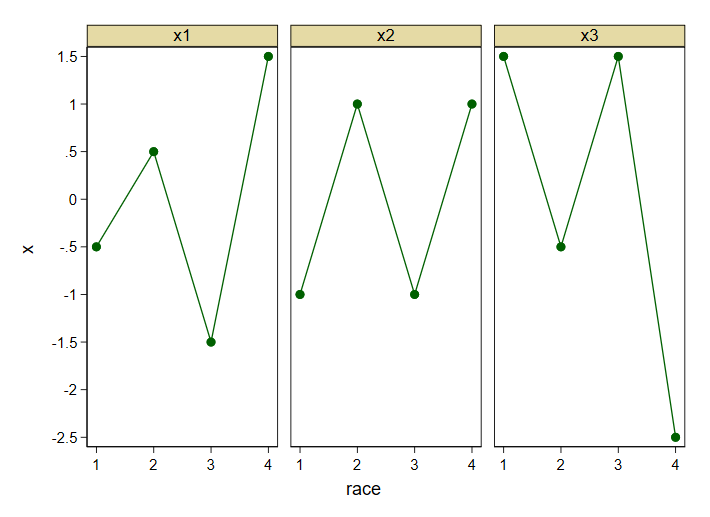
一般来说,这里发生了什么--或者具体而言,这与线性和/或逻辑回归有什么关系--这是任何人的猜测。可能有人在玩不同的种族表示法作为预测器。如果没有更多的上下文,这里甚至没有一个统计问题可以回答,更不用说编程问题了。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73888095
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号