
Scikit学习NMF如何调整结果分解的稀疏性?
对于稀疏基集的生成,非负矩阵因式分解是值得称赞的。但是,当我运行sklearn.decomposition.NMF时,这些因素并不稀疏。较早版本的NMF具有“稀疏度”参数beta。更新的版本不会,但我希望我的基本矩阵W实际上是稀疏的。我能做什么?(下面是再现问题的代码)。
我一直在尝试增加各种正则化参数(例如,alpha),但并不是很稀疏(就像Lee and Seung (1999)将它应用到Olivetti人脸数据集时的论文中那样)。他们基本上还是长得像特征脸。
我的CNM输出(不是很稀少):

Lee和Seung CNM纸输出基栏(在我看来很稀疏):

重现我的问题的代码:
from sklearn.datasets import fetch_olivetti_faces
import matplotlib.pyplot as plt
import numpy as np
from sklearn.decomposition import NMF
faces, _ = fetch_olivetti_faces(return_X_y=True)
# run nmf on the faces data set
num_nmf_components = 50
estimator = NMF(num_nmf_components,
init='nndsvd',
tol=5e-3,
max_iter=1000,
alpha_W=0.01,
l1_ratio=0)
H = estimator.fit_transform(faces)
W = estimator.components_
# plot the basis faces
n_row, n_col = 6, 4 # how many faces to plot
image_shape = (64, 64)
n_samples, n_features = faces.shape
plt.figure(figsize=(10,12))
for face_id, face in enumerate(W[:n_row*n_col]):
plt.subplot(n_row, n_col, face_id+1)
plt.imshow(face.reshape(image_shape), cmap='gray')
plt.axis('off')
plt.tight_layout()是否有一些参数的组合与sklearn.decomposition.NMF(),让您拨号在稀疏?我使用了alpha_W和l1_ratio的不同组合,甚至调整了组件的数量。我还是带着艾根脸的东西。
回答 1
Stack Overflow用户
发布于 2022-10-14 04:26:37
这里有几件事我们需要解开。首先,sparseness怎么了?第二,如何使用sklearn函数生成稀疏脸?
那个贱人去哪了?
sklearn.decomposition.NMF函数经历了从0.16版本到0.19版本的重大更改。实现非网络矩阵分解的方法有多种。
在0.16之前,NMF使用Hoyer 2004中描述的投影梯度下降,并包含一个稀疏参数(正如OP所指出的,它允许您调整结果W基的稀疏性)。
由于这个在sklearn的github回购上非常彻底的问题中概述的各种限制,决定继续使用另外两种方法:
这是一项相当重要的工作,其结果是我们现在在错误函数、初始化和正则化方面有了很大的自由度。你可以在问题上读到这件事。目标函数现在是:

您可以阅读更多的细节/解释在医生那里,但是要注意一些与这个问题相关的事情:
solver参数,用于乘法更新的mu或坐标下降的cd。不建议采用较老的投影梯度下降法(具有稀疏参数)。- 从目标函数中可以看出,正则化W和H(分别为
alpha_W和alpha_H)都有权值。理论上,如果你想统治W,你应该增加alpha_W。 - 您可以使用L1或L2规范进行正则化,两者之间的比率由
l1_ratio设置。l1_ratio越大,对L1范数的权重越大,L2范数越重。注意: L1范数倾向于生成更稀疏的参数集,而L2范数则倾向于生成较小的参数集,因此在理论上,如果您想要稀疏性,那么将您的l1_ratio设置得很高。
如何生成稀疏人脸?
对目标函数的检查表明了该做什么。把alpha_W和l1_ratio调高。但是也要注意,Lee论文使用了乘法更新(mu),所以如果您想要复制他们的结果,我建议将solver设置为mu、设置alpha_W high和l1_ratio high,然后看看会发生什么。
在OP的问题中,他们隐式地使用了cd求解器(这是默认的),并设置了alpha_W=0.01和l1_ratio=0,我不一定期望创建稀疏的基集。
但事情其实没那么简单。我用高l1_ratio和alpha_W尝试了一些坐标下降的初始运行,发现很低的稀疏性。因此,为了量化其中的一些,我做了一个网格搜索,并使用了一个稀疏的度量。
将稀疏性量化本身就是一个家庭手工业(例如看这篇文章,这里引用的那篇论文)。我用的是霍耶的稀疏度,改编自宁发包装中的标准
def sparseness_hoyer(x):
"""
The sparseness of array x is a real number in [0, 1], where sparser array
has value closer to 1. Sparseness is 1 iff the vector contains a single
nonzero component and is equal to 0 iff all components of the vector are
the same
modified from Hoyer 2004: [sqrt(n)-L1/L2]/[sqrt(n)-1]
adapted from nimfa package: https://nimfa.biolab.si/
"""
from math import sqrt # faster than numpy sqrt
eps = np.finfo(x.dtype).eps if 'int' not in str(x.dtype) else 1e-9
n = x.size
# measure is meant for nmf: things get weird for negative values
if np.min(x) < 0:
x -= np.min(x)
# patch for array of zeros
if np.allclose(x, np.zeros(x.shape), atol=1e-6):
return 0.0
L1 = abs(x).sum()
L2 = sqrt(np.multiply(x, x).sum())
sparseness_num = sqrt(n) - (L1 + eps) / (L2 + eps)
sparseness_den = sqrt(n) - 1
return sparseness_num / sparseness_den这实际上量化了一些复杂的图像,但粗略地说,稀疏图像是一个只有几个像素活动的图像,一个非稀疏图像有很多像素是活动的。如果我们在OP中的faces示例上运行PCA,我们可以看到特征面的稀疏值很低,在0.04左右:

使用坐标下降?
如果我们使用OP中使用的参数(使用坐标下降、低W_alpha和l1_ratio (除了200个组件)运行NMF ),那么稀疏值同样很低:

如果您查看稀疏值的直方图,就会验证这一点:
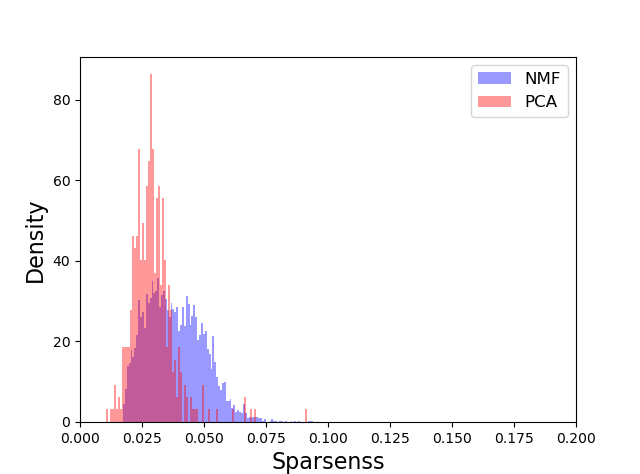
不同的,但不是超级令人印象深刻,与PCA相比。
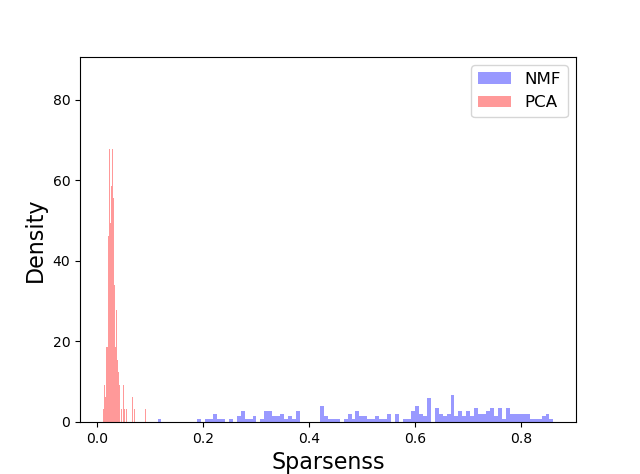
接下来,我在W_alpha和l1_ratio空间中进行网格搜索,将它们更改为0到1(以0.1步递增)。我发现稀疏度在1岁时并没有达到最大值。令人惊讶的是,与理论预期相反,我发现只有当l1_ratio为0时,稀疏性才会很高,并且急剧下降到0以上。在这部分参数中,当alpha_W为0.9时,稀疏性最大化:
从直觉上看,这是一个巨大的进步。稀疏值的分布仍有很大差异,但它们要高得多:
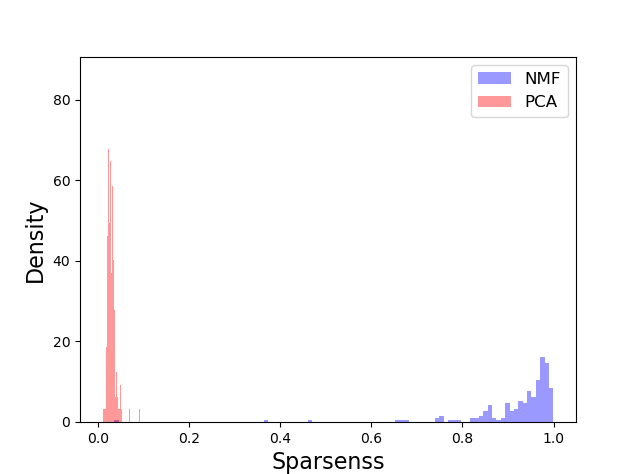
然而,也许为了复制Lee和Seung的结果,并更好地控制稀疏性,我们应该使用乘法更新(这就是他们使用的)。接下来再试一次。
使用乘法更新的分割方法
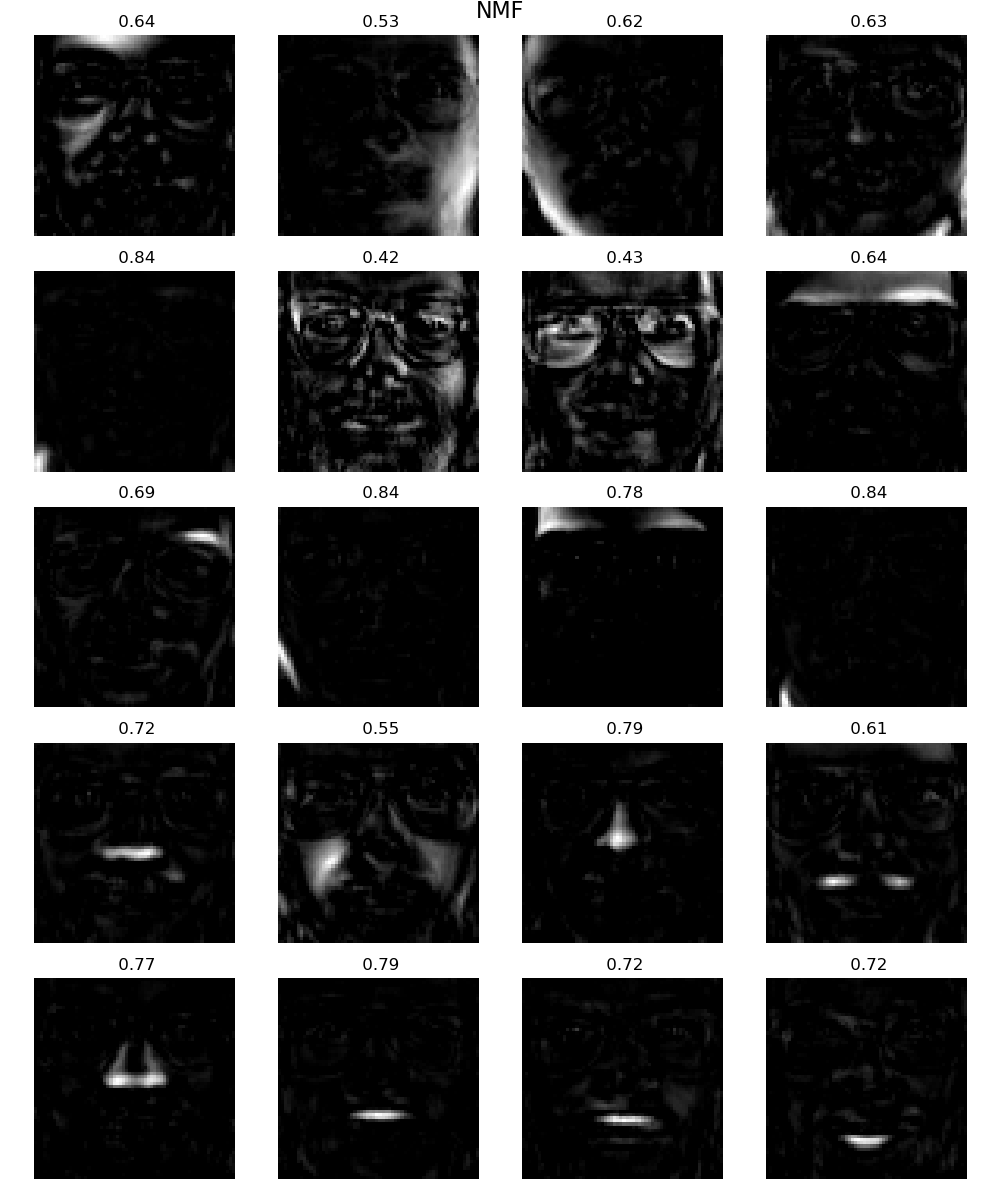
在下一次尝试中,我使用了乘性更新,这比预期的要好得多,出现了稀疏的、基于部件的表示:

您可以看到巨大的差异,这反映在稀疏值的直方图中:
注意,生成此代码的代码如下所示。
最后一件有趣的事情是:这种方法的稀疏值似乎随着组件数的增加而增加。我把稀疏性作为组件的函数绘制出来,这是(粗略地)生成出来的,并且在算法的所有运行过程中都是一致的:
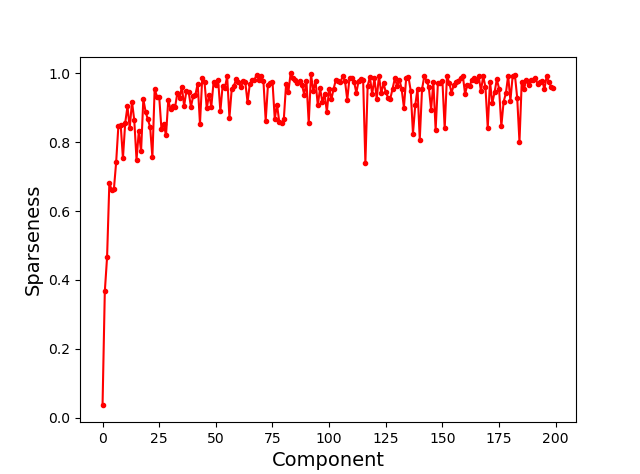
我还没有在其他地方见过这方面的讨论,所以我想我应该提一下。
使用mu NMF算法生成人脸稀疏表示的代码:
from sklearn.datasets import fetch_olivetti_faces
import matplotlib.pyplot as plt
import numpy as np
from sklearn.decomposition import NMF
faces, _ = fetch_olivetti_faces(return_X_y=True)
num_nmf_components = 200
alph_W = 0.9 # cd: .9, mu: .9
L1_ratio = 0.9 # cd: 0, L1_ratio: 0.9
try:
del estimator
except:
print("first run")
estimator = NMF(num_nmf_components,
init='nndsvdar', # nndsvd
solver='mu',
max_iter=50,
alpha_W=alph_W,
alpha_H=0, zeros
l1_ratio=L1_ratio,
shuffle=True)
H = estimator.fit_transform(faces)
W = estimator.components_
# plot the basis faces
n_row, n_col = 5, 7 # how many faces to plot
image_shape = (64, 64)
n_samples, n_features = faces.shape
plt.figure(figsize=(10,12))
for face_id, face in enumerate(W[:n_row*n_col]):
plt.subplot(n_row, n_col, face_id+1)
face_sparseness = sparseness_hoyer(face)
plt.imshow(face.reshape(image_shape), cmap='gray')
plt.title(f"{face_sparseness: 0.2f}")
plt.axis('off')
plt.suptitle('NMF', fontsize=16, y=1)
plt.tight_layout()https://stackoverflow.com/questions/73848268
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号