
XGB分类器模型泛化不佳,但评估指标改进了吗?
XGB分类器模型泛化不佳,但评估指标改进了吗?
提问于 2022-09-24 20:54:47
我在为下面的问题寻找一个解释。我正在将XGB模型拟合到50k行26个特性的数据集中。
我正在使用不同的max_depths + n_estimators运行网格搜索,该模型使用更深的树执行得更好(深度为14 im,达到c.87精度,c.83精度,当我将深度降低到5时,.85精度和.81精度降低)。在验证集上,两种模型的性能是相同的(.81精度、.78精度)。
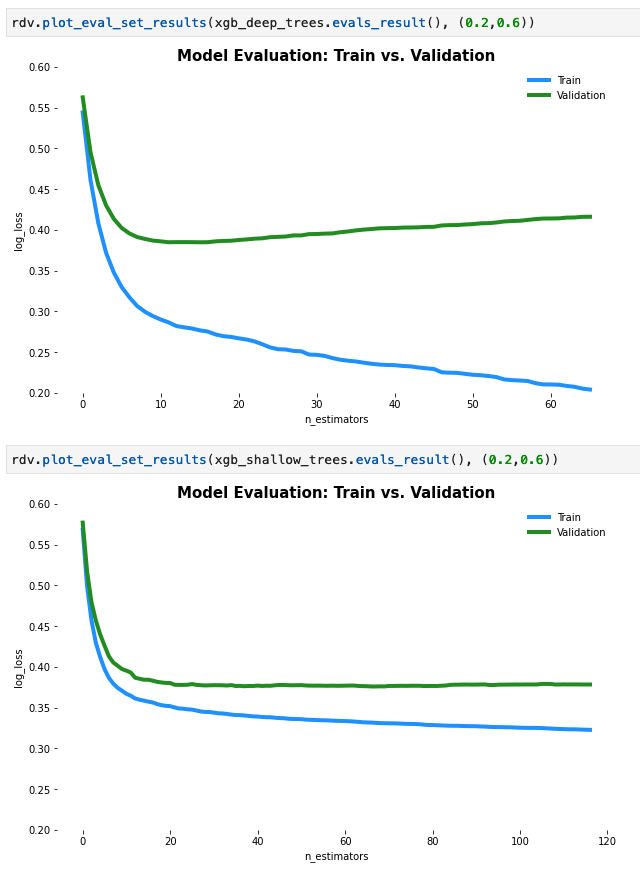
因此,在表面层面上,更深的模型似乎表现出了相同或更好的效果,但当我为这两个模型绘制学习曲线时,更深的模型看起来就像它的过度拟合。下面的图像显示了两个模型的学习曲线,顶部是较深的树,底部是较浅的树。
这怎么解释呢?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-09-25 15:20:46
一个非常简单的原因可能是容量。第一种模式,更深的模式,有更多的能力。因此,由于它的能力,它可以学习有用的东西,导致良好的表现,并在一段时间后,它将开始学习的东西,导致过度适应。这种情况通常发生在大容量的模型上。
您的第二个模型没有足够的能力来适应,这也可能导致它没有足够的能力来学习有用的东西。
你也可以在地块上看到更大的模型开始在10时代附近过度适应,但是它已经设法获得了一个比第二个模型更低的损失。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73840523
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号