
如何在OpenAI的Whisper ASR中获得字级时间戳?
如何在OpenAI的Whisper ASR中获得字级时间戳?
提问于 2022-09-23 02:15:26
我使用OpenAI的低语 python来进行语音识别。我怎样才能得到文字级的时间戳?
使用OpenAI的低语进行转录(在Ubuntu20.04 x64 LTS上使用Nvidia GeForce RTX 3090进行测试):
conda create -y --name whisperpy39 python==3.9
conda activate whisperpy39
pip install git+https://github.com/openai/whisper.git
sudo apt update && sudo apt install ffmpeg
whisper recording.wav
whisper recording.wav --model large如果使用Nvidia GeForce RTX 3090,请在conda activate whisperpy39之后添加以下内容
pip install -f https://download.pytorch.org/whl/torch_stable.html
conda install pytorch==1.10.1 torchvision torchaudio cudatoolkit=11.0 -c pytorch回答 1
Stack Overflow用户
发布于 2022-09-23 16:29:23
https://openai.com/blog/whisper/只提到“短语级时间戳”,我由此推断,如果不添加更多代码,就无法获得字级时间戳。
不直接支持获取字级时间戳,但可以使用时间戳标记的预测分布或交叉注意权重。
https://github.com/jianfch/stable-ts (麻省理工学院许可证):
该脚本修改了Whisper模型的方法,以获得每个单词的预测时间戳标记,而不需要添加推断。它还将时间戳稳定到单词级别,以确保编年史。
请注意:
- 不清楚这些字级的时间戳有多精确。
- 字幕有时不同步。
另一种选择:使用一些字级强制对齐程序。例如,拉赫斯 (Apache-2.0许可证)具有综合化和Wav2vec强制对齐:
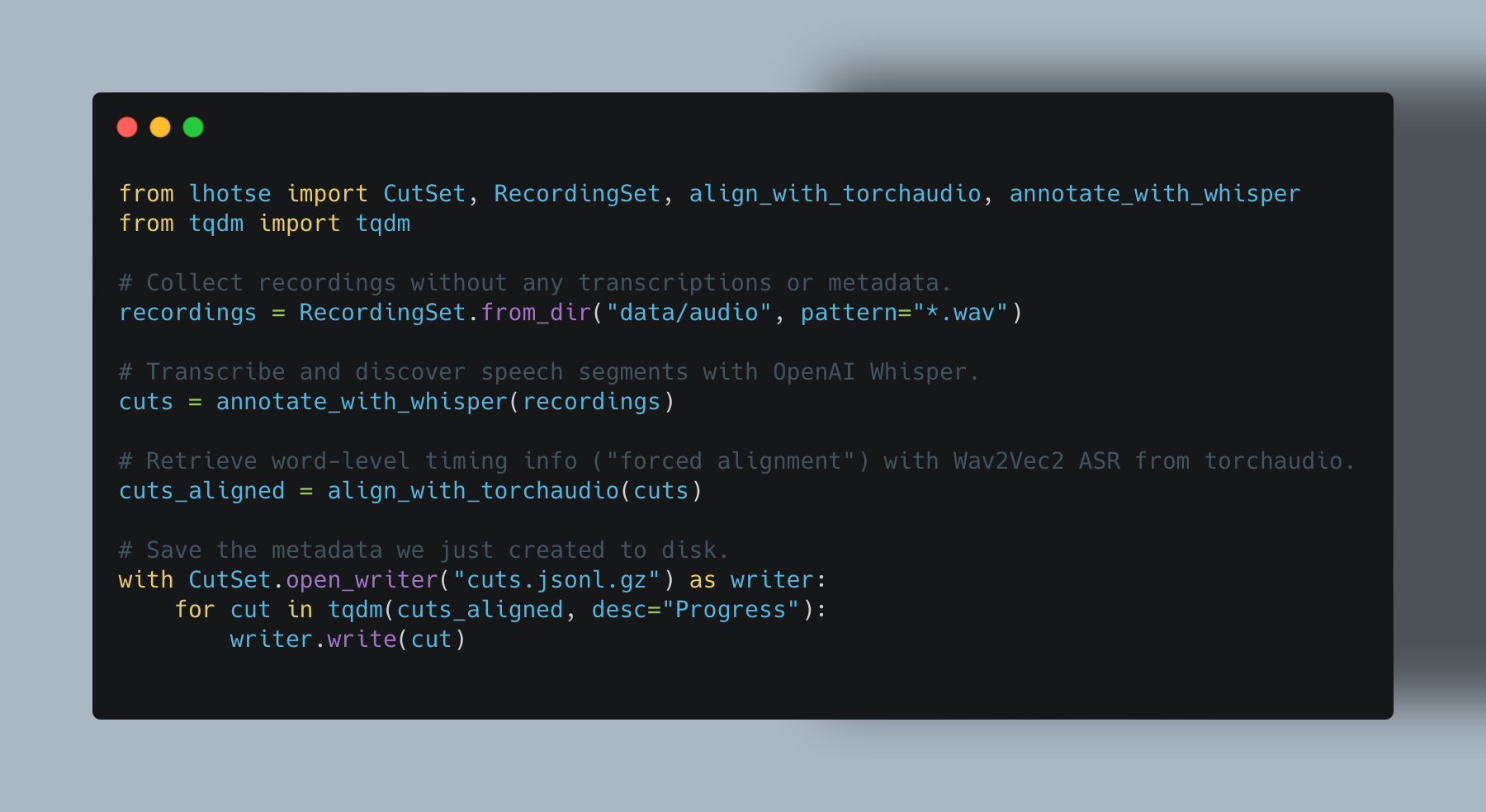
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73822353
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号