
Python,请求webscraping - NSE印度给出emtpy列表
Python,请求webscraping - NSE印度给出emtpy列表
提问于 2022-09-22 09:47:19
我正试图利用要求从NSE中收集数据,以找到印度股市的顶级成份股。我在雅虎金融上使用了同样的方法,而且它也起了作用,但在这里,我一直得到空列表作为结果。
这是我的代码:
import requests
from lxml import html
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
headers = {'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:77.0) Gecko/20100101 Firefox/77.0'}
resp = requests.get('https://www.nseindia.com/market-data/top-gainers-loosers', verify=False, headers=headers)
tree = html.fromstring(resp.content)
count = 1
stocks = []
for i in range(30):
name = tree.xpath('//*[@id="topgainer-Table"]/tbody/tr['+str(count)+']/td[1]/a')
print(name)
try:
stocks.append(name[0].text)
except:
pass
#name.text
count +=1
print(stocks)作为输出,我被打印了很多次(一个空列表)。我认为问题在于NSE,因为它有许多不同的表,所有这些表都具有相同的xpath。
有什么想法吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2022-09-22 09:54:23
如果您检查网站,它需要一些时间来加载数据,所以从bs4您将无法找到数据。
网络选项卡::
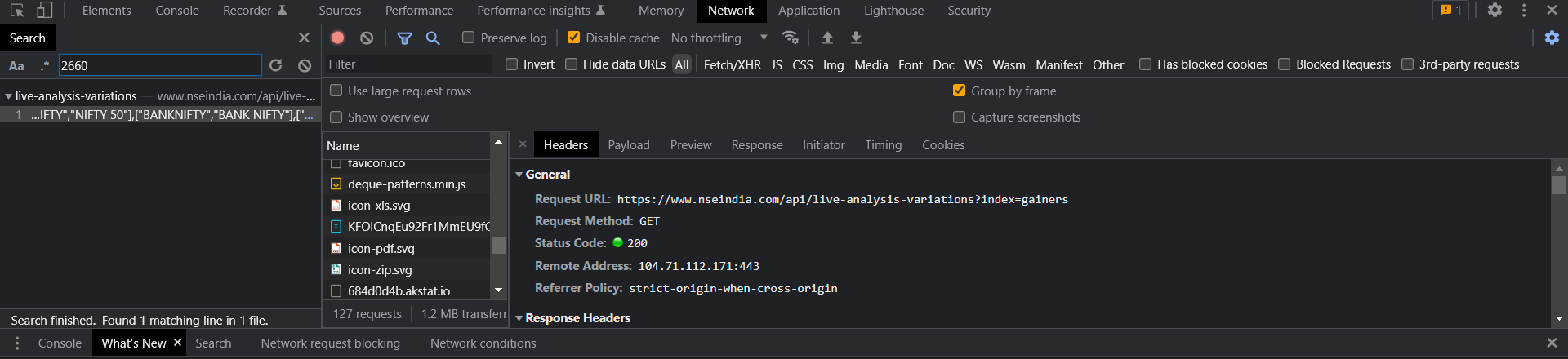
您可以从“网络”选项卡中找到它,并搜索从附在屏幕截图中获得的任何公司名称,并找到该网址并调用它,它将返回JSON数据。所以你可以提取你想要的数据
import requests
import pandas as pd
headers={"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"}
res=requests.get(r"https://www.nseindia.com/api/live-analysis-variations?index=gainers",headers=headers)
all_data=res.json()['NIFTY']['data']
df=pd.DataFrame(all_data)输出:

顶部松类的URL ::https://www.nseindia.com/api/live-analysis-variations?index=loosers
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/73812560
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号