
Azure的TTS语音速率和音高是否在后处理中完成?
我正在使用Azure的TTS服务,并且想知道在生成基本声音之后,速率和音调值是否应用于音频文件,还是它们是产生基本声音的AI算法的一部分?
我想知道上面的情况,因为它会影响对生成文件的采样(和可用声音)的选择。例如,如果我在24 the处生成一个声音文件,然后根据设置(速率、音高)进行拉伸,那么与在48 the产生的声音文件相比,会有一些质量损失,然后再进行后处理。然而,如果速度和音高是AI算法的一部分,那么声音就不会受到高质量的影响。
这也很重要,因为如果声音是在后期处理的,我可以在DAW中以更高的精度完成这个任务,而不是依赖于TTS进程中的设置。但是,如果algo根据TTS中的设置修改声音,那么质量将尽可能好。
回答 1
Stack Overflow用户
发布于 2022-09-27 09:41:15
有两种方法可以执行这些操作:
- 创建自定义语音
开放式演讲演播室
b.录制音频
c.执行语音合成器
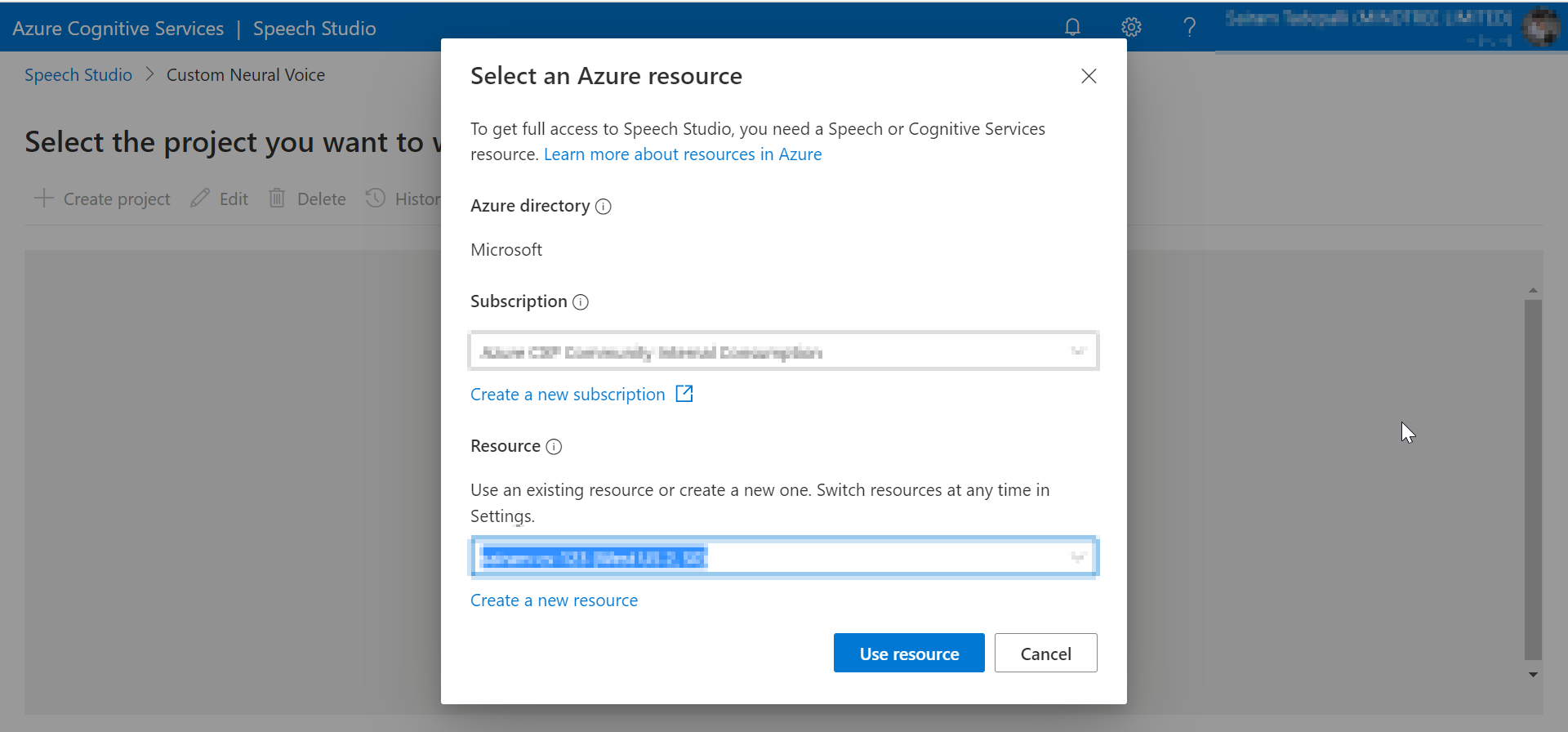
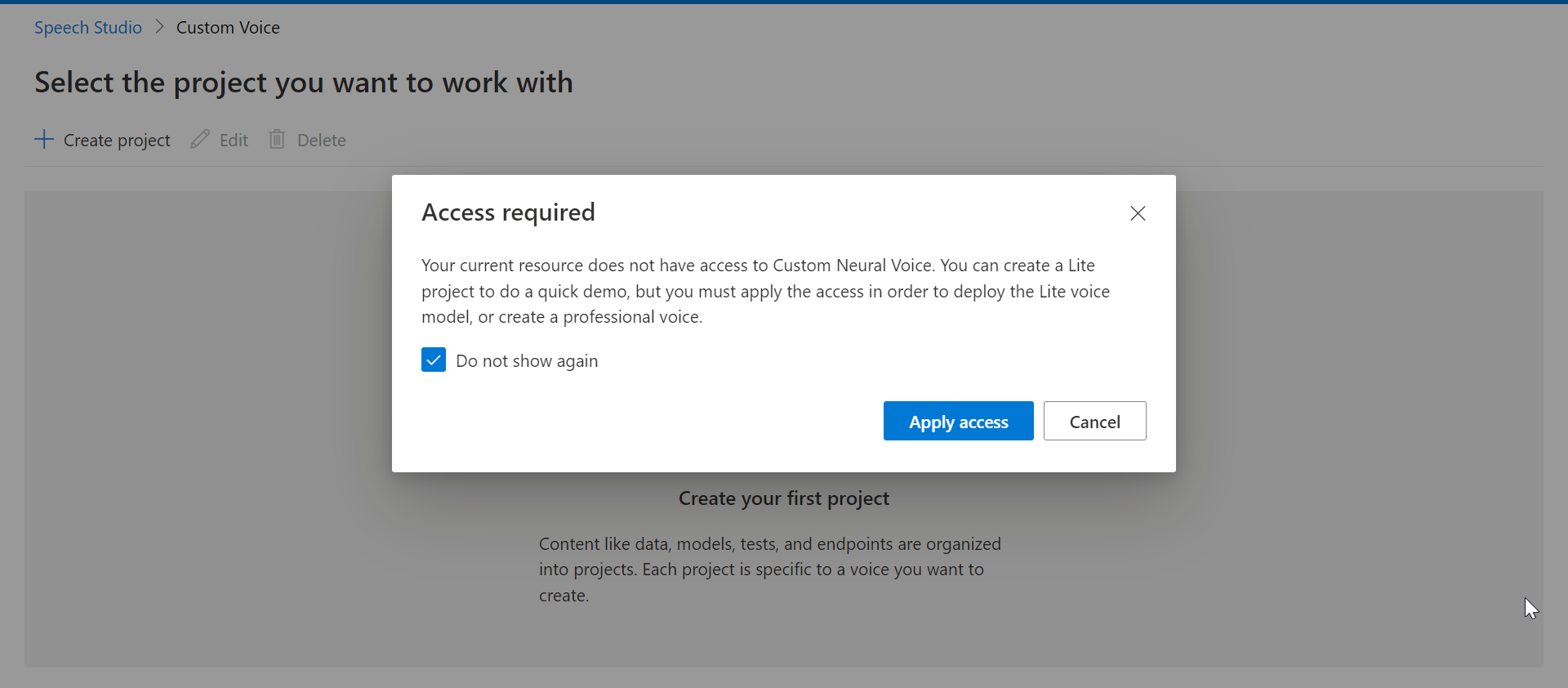
若要获得访问权限,请单击“应用访问”。您的组织管理员将根据请求给予您访问权限。
要获得操作的完整结构,请检查注释部分中提到的链接。
若要执行编程方式,请按照以下代码块并替换订阅和区域详细信息。
import azure.cognitiveservices.speech as speechsdk
def recognize_from_mic():
# Find your key and resource region under the 'Keys and Endpoint' tab in your Speech resource in Azure Portal
# Remember to delete the brackets <> when pasting your key and region!
speech_config = speechsdk.SpeechConfig(subscription="", region="westus2")
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config)
# Asks user for mic input and prints transcription result on screen
print("Speak into your microphone.")
result = speech_recognizer.recognize_once_async().get()
print(result.text)
recognize_from_mic()利用语音合成标记语言对合成进行改进。使用以下XML代码创建用于语音合成的XML文件。
<speak version="1.0" xmlns="URL" xml:lang="string"></speak>若要为文本语音选择语音,请按照注释中提到的链接进行操作。要调整语音补丁和样式,请按照注释中提到的链接构建XML。
https://stackoverflow.com/questions/73803114
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号